Erinnern Sie sich noch an das viel diskutierte mysteriöse KI-Bildbearbeitungsmodell „nano-banana“? Damals sorgte es in der LMArena, der Arena für große Sprachmodelle, mit seiner herausragenden Leistung für großes Aufsehen. Auch die Technikexperten von Google Gemini traten nacheinander auf und machten die Community auf Social Media neugierig, es wurde sogar zeitweise als das sagenumwobene Gemini 3.0 Pro gehandelt.
Jetzt hat Google endlich das Geheimnis gelüftet.
Am 27. August um Mitternacht (UTC+8) hat Google AI Studio offiziell Gemini 2.5 Flash Image (Codename nano banana) 🍌 veröffentlicht.
Das lang erwartete Gemini 2.5 Flash Image ist endlich da | Bildquelle: GeekPark
Dies ist das bisher fortschrittlichste Bildgenerierungs- und Bearbeitungsmodell von Google. Es ist nicht nur unglaublich schnell – fast wie ein „Blitz“-Erlebnis –, sondern hat auch auf mehreren Ranglisten SOTA-Ergebnisse erzielt und liegt in der LMArena weit vorne.
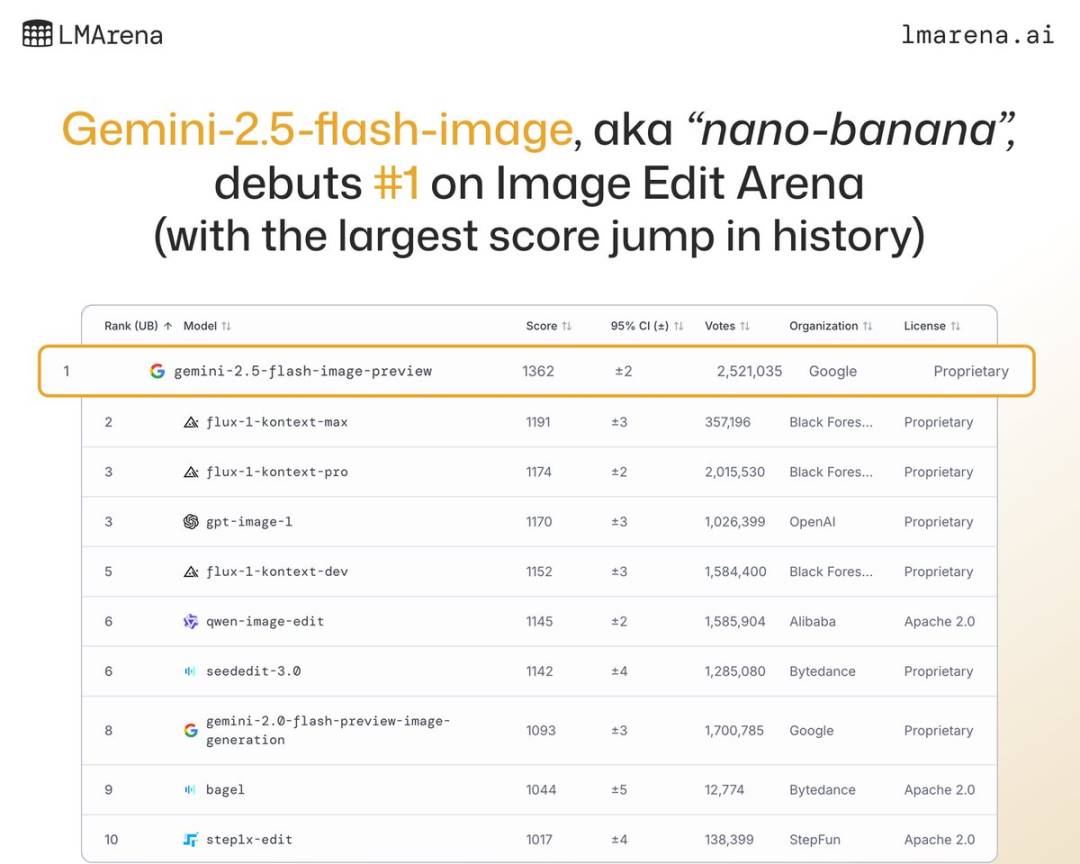
Gemini 2.5 Flash Image erreicht direkt bei Markteintritt SOTA-Fähigkeiten | Bildquelle: LMarena.ai
Im technischen Blog erwähnt Google, dass Gemini 2.0 Flash bereits aufgrund seiner niedrigen Latenz und seines guten Preis-Leistungs-Verhältnisses bei Entwicklern beliebt ist, aber die Nutzer sehnten sich nach noch höherer Bildqualität und mehr kreativer Kontrolle. Gemini 2.5 Flash Image bringt genau diese Upgrades mit: Die Konsistenz der Rollen wird endlich vollständig beibehalten, die bildbasierte Bearbeitung auf Basis von Prompts ist präziser, die Verschmelzung mehrerer Bilder wirkt natürlich und flüssig, und das Verständnis für Weltwissen macht es nicht nur zu einem Modell, sondern zu einem „Ursprung“, der die Grundlage für die nächste Generation von Blockbuster-Anwendungen bildet.
Auch GeekPark hat es sofort ausprobiert. Überraschenderweise ist dies nicht nur ein Modell-Update, sondern erstmals fühlt es sich so an, als sei die Zukunft der KI-Bildbearbeitung zum Greifen nah.
Im Google AI Studio ist das Erlebnis bereits verfügbar | Bildquelle: GeekPark
Anfangs wollte ich das Modell nur routinemäßig testen, um zu sehen, „wie viel schneller es ist“. Doch nach nur wenigen Stunden hatte ich das Gefühl, einen Blick auf die nächste Generation von Blockbuster-Anwendungen werfen zu können.
Früher waren wir an Tools wie Meitu Xiuxiu gewöhnt: Ein paar Klicks, ein Filter, und das Foto wird schnell verschönert. Doch Gemini 2.5 Flash Image fühlt sich völlig anders an. Es ist unglaublich schnell, so intelligent wie ein Designer, der deine Gedanken versteht – du musst nur sagen, was du willst, und in wenigen Sekunden erscheint das gewünschte Bild.

Neben dem Effekt ist die Geschwindigkeit ein weiteres deutliches Unterscheidungsmerkmal von Gemini 2.5 Flash Image gegenüber bisherigen Modellen | Bildquelle: GeekPark
01 Blitzschnelle Generierung, Ergebnisse in wenigen Sekunden
Das unmittelbarste Erlebnis mit nano banana ist die Geschwindigkeit. Bei bisherigen Open-Source-Modellen musste man, selbst mit guter Hardware, oft mehrere Dutzend Sekunden oder länger warten, bis ein brauchbares Bild generiert wurde. Für mobile Nutzer war das Warten noch quälender.
Doch Gemini 2.5 Flash Image senkt diese Hürde auf wenige Sekunden. Es ist laut Google das „neueste, schnellste und effizienteste“ native Multimodal-Modell, bei dessen Optimierung offensichtlich viel Aufwand betrieben wurde. In meinen Tests dauerte es nach Eingabe eines Prompts nur drei bis vier Sekunden (UTC+8), bis das Ergebnis erschien – mit beeindruckender Auflösung und Detailtreue.
Dieses Erlebnis erinnert an die alltägliche Nutzung von Meitu Xiuxiu: Ein Klick auf den „Verschönern“-Button, und der Effekt ist fast sofort sichtbar. Der Unterschied: Meitu Xiuxiu nutzt Algorithmen, um Filter anzuwenden, während Gemini 2.5 Flash Image ein Bild von Grund auf neu erstellt oder ein Foto nach deinen Wünschen umfassend verändert. Dieses „Sag, was du willst, und es passiert“-Gefühl ist mit den bisherigen, mühsamen Bildbearbeitungsprozessen nicht vergleichbar.

Solche Anforderungen wie „Entferne Passanten aus dem Hintergrund“ lassen sich mit nur einem Prompt lösen | Bildquelle: GeekPark
Wenn Geschwindigkeit das Nutzererlebnis traditioneller Bildbearbeitung verbessert, dann erweitert die „native Multimodalität“ die KI-Bildfähigkeiten.
Gemini 2.5 Flash Image kann nicht nur Bilder generieren, sondern versteht gleichzeitig Text- und Bildeingaben. Das bedeutet, ich kann ein Foto und einen Textprompt gleichzeitig eingeben, und das Modell kombiniert beide Informationen, um zu verstehen, was ich wirklich will.
Ein Beispiel: Ich lade ein Straßenfoto hoch und sage dazu „ändere den Hintergrund in die nächtliche Skyline von Shinjuku, Tokio“. (UTC+8) Das Modell erkennt nicht nur das Hauptmotiv im Foto, sondern schneidet die Person präzise aus und ersetzt den Hintergrund durch das neonbeleuchtete Shinjuku. Besonders beeindruckend: Die Lichtverhältnisse der Person bleiben konsistent, ohne den oft künstlichen „Ausschneide-Look“ manueller Bearbeitung.
Diese Fähigkeit erinnert an die „Ein-Klick-Hintergrundwechsel“-Funktion, die in den letzten Jahren oft in den Fotoalben von Smartphones beworben wurde. Damals wirkten die Ergebnisse jedoch oft künstlich, mit unscharfen Rändern und falscher Beleuchtung. Jetzt kann Gemini 2.5 Flash Image durch Weltwissen und visuelles Verständnis diese Details ausgleichen und liefert viel natürlichere Ergebnisse mit deutlich besserer Detailtreue als herkömmliche Text-to-Image- oder Image-to-Image-Modelle.

Originalbild & Gemini 2.5 Flash Image Ergebnis | Bildquelle: GeekPark
Deshalb glaube ich, dass es das Bildbearbeitungserlebnis neu definieren wird: Nicht mehr aufwändige manuelle Anpassungen, sondern die natürliche semantische Interpretation des Modells erledigt die Arbeit – besonders in Szenarien wie Porträtbearbeitung, wo höchste Detailgenauigkeit gefragt ist.

Gerade bei Porträtbearbeitung bietet die Rollenkonsistenz von Gemini 2.5 Flash Image ein noch nie dagewesenes „Vibe Photoshoping“-Erlebnis.

In einer Sekunde wird der Programmierer „gerettet“ | Bildquelle: GeekPark
Dieses Erlebnis bricht mit dem bisherigen Eindruck vieler von KI-Bildgenerierung – „Magie“: Mit guten Prompts entstehen beeindruckende Bilder, mit durchschnittlichen Prompts kann das Ergebnis völlig danebenliegen.
Doch bei Gemini 2.5 Flash Image ist dieses „magische Gefühl“ deutlich abgeschwächt. Das Modell versteht Prompts präziser und näher an der Nutzerintention – das ist der Grund, warum viele plötzlich finden, dass es viel besser nutzbar ist.
Wenn ich zum Beispiel sage „Hintergrund unscharf machen, Vordergrundperson hervorheben“ (UTC+8), ist das Ergebnis nach wenigen Sekunden genau das, was ich wollte. Sage ich „Lass die Person auf dem Foto lächeln“, hebt sich nicht nur der Mundwinkel, sondern auch der Gesichtsausdruck wird angepasst – die Details stimmen. Ich habe sogar ausprobiert, „Koloriere das Schwarzweißfoto“, und das Ergebnis war keine willkürliche Farbgebung, sondern so nah wie möglich an der Atmosphäre historischer Fotos.
Diese „Sag es, und es wird gemacht“-Fähigkeit erinnert mich an frühere Erfahrungen mit Meitu Xiuxiu: Man wollte nur die Haut glätten, aber das ganze Gesicht wurde zu einer „zehnfach verschönerten“ Maskenfratze. Jetzt arbeitet Gemini 2.5 Flash Image präzise und zurückhaltend – es versteht wirklich, was du willst, und versucht, es so originalgetreu wie möglich umzusetzen.
02 Verbesserte Fähigkeiten, einmal genutzt – nie mehr zurück
Um es anschaulicher zu machen, habe ich es mit meinen üblichen mobilen Bildbearbeitungstools verglichen.
In Snapseed muss ich, um den Hintergrund zu verwischen, normalerweise ein bis zwei Minuten lang den Vordergrundbereich manuell auswählen und dann die Unschärfe einstellen. Selbst als geübter Nutzer sind wiederholte Anpassungen unvermeidlich.
Bei Meitu Xiuxiu gibt es zwar eine Ein-Klick-Hintergrundunschärfe, aber oft werden dabei auch die Ränder der Person unscharf – das Ergebnis wirkt unnatürlich.
Mit Gemini 2.5 Flash Image reicht ein einziger Satz, das Modell erkennt automatisch die Grenzen zwischen Person und Hintergrund, der Unschärfeeffekt ist natürlich, Nachbearbeitung ist nicht nötig.

Während Details im Bild geändert werden, bleibt der Rest des Hintergrunds von den typischen „Schmierereien“ früherer KI-Tools verschont | Bildquelle: Twitter
Dieser Vergleich zeigt eines: Gemini 2.5 Flash Image befreit die Nutzer von komplexen Arbeitsschritten und überträgt mehr Aufgaben an das Modell. Für Laien wird die Bildbearbeitung zugänglicher, für Profis spart es viel Zeit.
Mein größter Eindruck nach dem Test: Gemini 2.5 Flash Image ist nicht mehr nur ein Bildbearbeitungstool, sondern eher ein „intelligenter Assistent“.
Früher nutzten wir Meitu Xiuxiu als eine Sammlung vorgefertigter Funktionen – Filter, Verschönerung, Mosaik –, jeder Button stand für eine Funktion. Man musste Schritt für Schritt auswählen und anpassen, bis man zufrieden war.
Jetzt funktioniert Gemini 2.5 Flash Image ganz anders. Du musst nicht mehr die Logik des Tools lernen, sondern das Tool versteht direkt deine Wünsche. Du sagst es einfach, und es erledigt es für dich.
Dieser Wandel wirkt subtil, verändert aber das Verhältnis im Bildbearbeitungsprozess grundlegend. Früher passten wir uns dem Tool an, jetzt passt sich das Tool uns an. Diese Interaktionsform ist der Prototyp der nächsten Anwendungs-Generation.
Gemessen am aktuellen Stand befindet sich Gemini 2.5 Flash Image noch in einer frühen Phase, die Funktionen haben noch Grenzen. Aber die gezeigte Geschwindigkeit, das Verständnis und die Detailtreue lassen viel Raum für Fantasie über die Zukunft.
Was wäre, wenn man es mit Meitu Xiuxiu kombiniert? Vielleicht öffnet man die App, sagt ins Handy: „Bitte bearbeite dieses Foto, lass die Haut natürlicher wirken“, und das Ergebnis ist in wenigen Sekunden da (UTC+8). Oder beim Reisen sagt man: „Mach das Wetter sonnig“ (UTC+8), und das Foto wird sofort sonnig. Vielleicht kann man sogar beim Video-Editing mit einem Satz die ganze Stimmung eines Clips verändern.

Diese Methode könnte in Zukunft schnell zur Standardfunktion für Bildbearbeitung in mobilen Betriebssystemen werden | Bildquelle: Twitter
Deshalb glaube ich, dass es die bisherigen Arbeitsabläufe der Bildbearbeitungstools revolutionieren und die nächste Generation von „Meitu Xiuxiu“ definieren wird: Nicht nur Bildbearbeitung, sondern eine neue Interaktionsweise, bei der KI dein Partner in der Fotobearbeitung wird.
Doch aktuell ist Gemini 2.5 Flash Image noch nicht bereit, als sofort einsatzbereite Massen-Bildbearbeitungs-App zu dienen: Zum einen liegt der Fokus weiterhin auf Bildgenerierung statt auf Feinabstimmung bestehender Bilder, zum anderen enthalten alle mit Gemini 2.5 Flash Image erstellten oder bearbeiteten Bilder ein SynthID-Digitalwasserzeichen, das von Social-Media-Plattformen zur Erkennung von KI-generierten Inhalten genutzt wird.
03 Der Auslöser für den nächsten Blockbuster
Rückblickend wurde Meitu Xiuxiu einst zur Volks-App, weil sie auf einfachste Weise ein Problem löste, das jeder hatte – Fotos schöner machen.
Gemini 2.5 Flash Image geht noch einen Schritt weiter und macht komplexe KI-Fähigkeiten für jeden nutzbar – mit einem „Sekundenbild“-Erlebnis.
Als ich zum ersten Mal sagte „Bitte mach den Hintergrund unscharf“ (UTC+8) und das Bild nach wenigen Sekunden natürlich bearbeitet war, wusste ich: Das ist der Ursprung eines Blockbuster-Produkts. Es ist nicht nur ein Modell, sondern die Basistechnologie für unzählige neue Produkte der Zukunft.
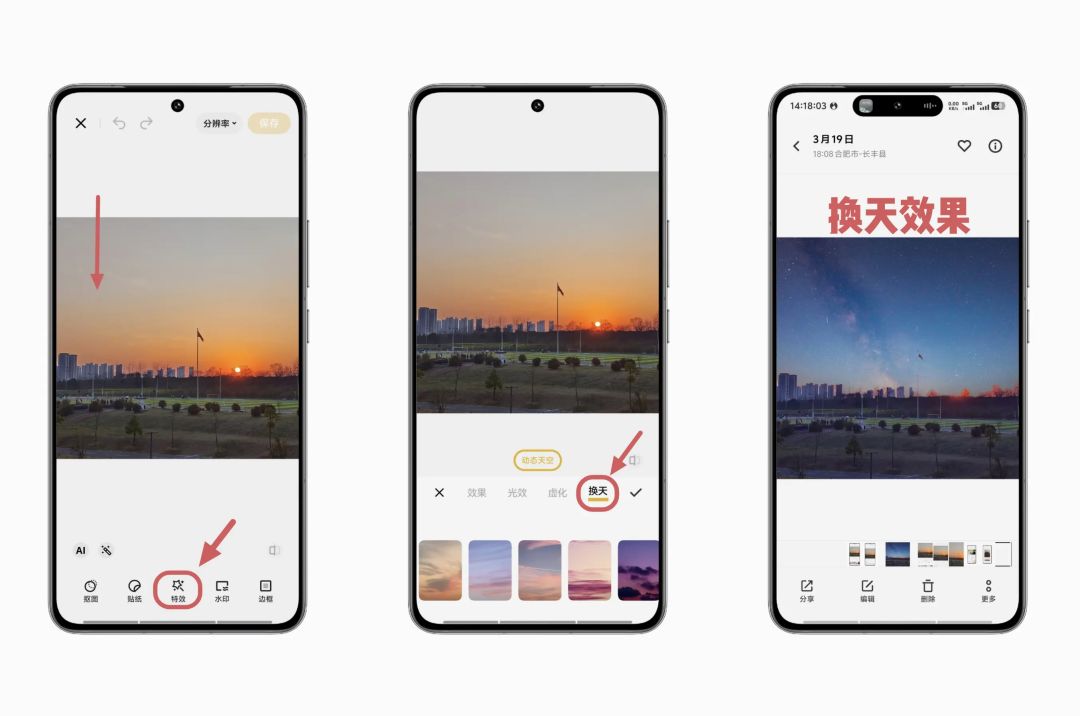
Das in den letzten Jahren bei Smartphone-Nutzern beliebte KI-Feature „Ein-Klick-Himmelstausch“ | Bildquelle: vivo Community
Vielleicht werden wir uns in ein paar Jahren nicht mehr an den Codenamen Banana erinnern, aber wir werden immer mehr Bildbearbeitungstools erleben, bei denen man einfach sagt, was man will, und es wird sofort umgesetzt – vielleicht wird es wie Meitu Xiuxiu einst zum gemeinsamen Gedächtnis einer ganzen Nutzer-Generation.
Nur diesmal wird KI die Vorstellungskraft noch weiter treiben.