
Von Liquidationssturm bis Cloud-Ausfall: Die Krisenzeit der Krypto-Infrastruktur

Am 20. führte ein Problem bei Amazons AWS dazu, dass Coinbase sowie Dutzende anderer großer Krypto-Plattformen, darunter Robinhood, Infura, Base und Solana, außer Betrieb gesetzt wurden.
Originaltitel: Crypto Infrastructure is Far From Perfect
Originalautor: YQ, Crypto KOL
Originalübersetzung: AididiaoJP, Foresight News
Amazon Web Services hat erneut einen bedeutenden Ausfall erlitten, der die Krypto-Infrastruktur schwer beeinträchtigte. Probleme mit AWS in der US-East-1-Region (Datenzentrum Nord-Virginia) führten dazu, dass Coinbase sowie Dutzende anderer großer Krypto-Plattformen, darunter Robinhood, Infura, Base und Solana, lahmgelegt wurden.
AWS hat eine „erhöhte Fehlerquote“ eingeräumt, die Amazon DynamoDB und EC2 betrifft – zentrale Datenbank- und Computing-Dienste, auf die Tausende Unternehmen angewiesen sind. Dieser Ausfall liefert einen unmittelbaren und anschaulichen Beweis für das zentrale Argument dieses Artikels: Die Abhängigkeit der Krypto-Infrastruktur von zentralisierten Cloud-Service-Anbietern schafft systemische Schwachstellen, die sich unter Druck immer wieder zeigen.
Das Timing ist aufschlussreich. Nur zehn Tage nachdem eine Kettenreaktion von Liquidationen im Wert von 1.93 billions US-Dollar Infrastrukturfehler auf der Ebene der Handelsplattformen offenlegte, zeigt der heutige AWS-Ausfall, dass das Problem über einzelne Plattformen hinausgeht und sich auf die grundlegende Cloud-Infrastrukturebene erstreckt. Wenn AWS ausfällt, wirken sich die Kaskadeneffekte gleichzeitig auf zentralisierte Handelsplattformen, „dezentrale“ Plattformen mit zentralisierten Abhängigkeiten und unzählige andere Dienste aus.
Dies ist kein Einzelfall, sondern ein Muster. Die folgende Analyse dokumentiert ähnliche AWS-Ausfälle im April 2025, Dezember 2021 und März 2017, die jedes Mal zu Ausfällen wichtiger Krypto-Dienste führten. Die Frage ist nicht, ob der nächste Infrastrukturausfall eintritt, sondern wann und was ihn auslöst.
Kettenreaktion von Liquidationen am 10.–11. Oktober 2025: Fallstudie
Das Liquidationsereignis vom 10.–11. Oktober 2025 bietet eine aufschlussreiche Fallstudie für das Muster von Infrastrukturausfällen. Um 20:00 Uhr UTC löste eine bedeutende geopolitische Ankündigung einen marktweiten Ausverkauf aus. Innerhalb einer Stunde kam es zu Liquidationen im Wert von 6 billions US-Dollar. Bis zur Öffnung der asiatischen Märkte waren in 1.6 Millionen Händlerkonten bereits 19.3 billions US-Dollar an gehebelten Positionen ausgelöscht.
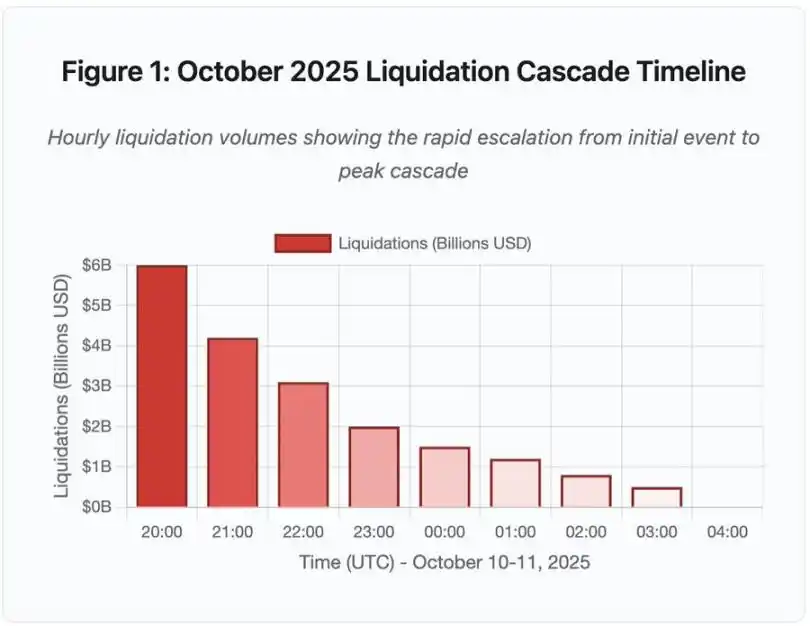
Abbildung 1: Zeitstrahl der Kettenreaktion von Liquidationen im Oktober 2025
Diese interaktive Zeitstrahlgrafik zeigt die dramatische Entwicklung des Liquidationsvolumens pro Stunde. Allein in der ersten Stunde wurden 6 billions US-Dollar ausgelöscht, gefolgt von einer noch heftigeren Beschleunigung in der zweiten Stunde der Kettenreaktion. Die Visualisierung zeigt:
· 20:00–21:00: Initialer Schock – 6 billions US-Dollar liquidiert (roter Bereich)
· 21:00–22:00: Höhepunkt der Kettenreaktion – 4.2 billions US-Dollar, API-Rate-Limits beginnen zu greifen
· 22:00–04:00: Anhaltende Verschlechterung – 9.1 billions US-Dollar werden in einem illiquiden Markt liquidiert
· Kritischer Wendepunkt: API-Rate-Limits, Rückzug von Market Makern, Ausdünnung des Orderbuchs
Das Ausmaß ist mindestens eine Größenordnung größer als bei jedem früheren Krypto-Marktereignis, historische Vergleiche zeigen die Sprungfunktion dieses Ereignisses:
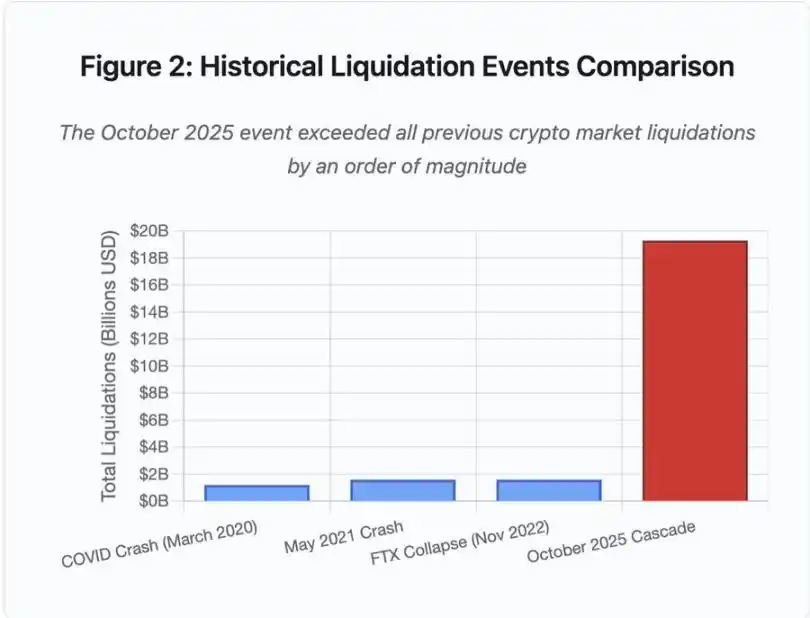
Abbildung 2: Vergleich historischer Liquidationsereignisse
Das Balkendiagramm verdeutlicht dramatisch die herausragende Größe des Ereignisses im Oktober 2025:
· März 2020 (COVID): 1.2 billions US-Dollar
· Mai 2021 (Crash): 1.6 billions US-Dollar
· November 2022 (FTX): 1.6 billions US-Dollar
· Oktober 2025: 19.3 billions US-Dollar – 16-mal größer als der bisherige Rekord
Doch die Liquidationszahlen erzählen nur einen Teil der Geschichte. Interessanter ist die Frage nach dem Mechanismus: Wie löste ein externes Marktereignis genau dieses Fehlermuster aus? Die Antwort offenbart systemische Schwächen in der Infrastruktur zentralisierter Handelsplattformen und im Design von Blockchain-Protokollen.
Off-Chain-Ausfälle: Architektur zentralisierter Handelsplattformen
Infrastrukturüberlastung und Rate-Limits
Handelsplattform-APIs setzen Rate-Limits ein, um Missbrauch zu verhindern und die Serverlast zu steuern. Im Normalbetrieb ermöglichen diese Limits legitimen Handel und blockieren potenzielle Angriffe. In extrem volatilen Phasen, wenn Tausende Händler gleichzeitig ihre Positionen anpassen wollen, werden diese Rate-Limits jedoch zum Engpass.
CEXs begrenzen Liquidationsbenachrichtigungen auf eine Order pro Sekunde, selbst wenn sie Tausende Orders pro Sekunde verarbeiten. Während der Kettenreaktion im Oktober führte dies zu Intransparenz. Nutzer konnten das Ausmaß der Kettenreaktion in Echtzeit nicht erkennen. Drittanbieter-Überwachungstools zeigten Hunderte Liquidationen pro Minute, während die offiziellen Datenquellen deutlich weniger anzeigten.
API-Rate-Limits verhinderten, dass Händler in der entscheidenden ersten Stunde ihre Positionen anpassen konnten, Verbindungsanfragen liefen ins Leere, Orderübermittlungen scheiterten. Stop-Loss-Orders wurden nicht ausgeführt, Positionsabfragen lieferten veraltete Daten – dieser Infrastrukturengpass verwandelte ein Marktereignis in eine operative Krise.
Traditionelle Handelsplattformen konfigurieren ihre Infrastruktur für die normale Last plus Sicherheitsmarge. Doch normale und Stresslast unterscheiden sich grundlegend, das durchschnittliche Tagesvolumen ist kein guter Prädiktor für Spitzenlasten. Während der Kettenreaktion stieg das Handelsvolumen um das 100-fache oder mehr, Positionsabfragen um das 1000-fache, da jeder Nutzer gleichzeitig sein Konto prüfte.
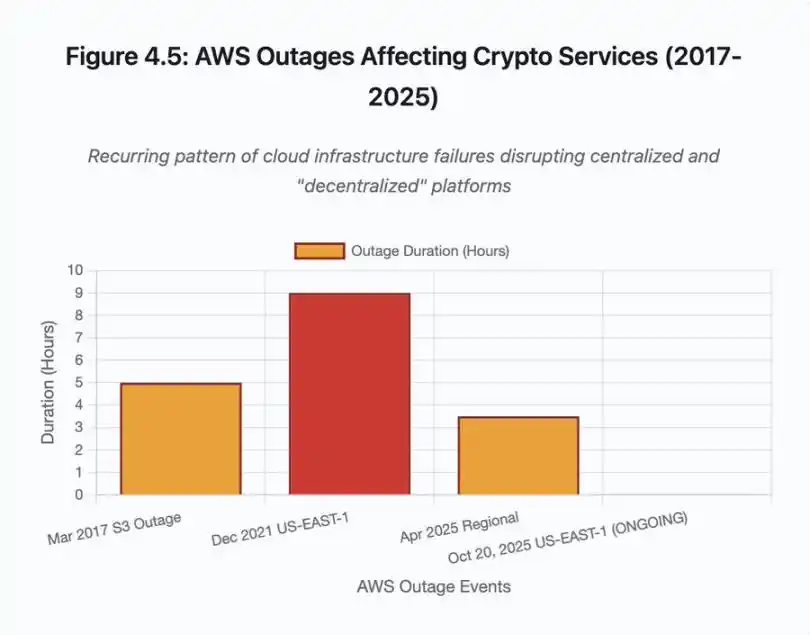
Abbildung 4.5: Von AWS-Ausfällen betroffene Krypto-Dienste
Automatisch skalierende Cloud-Infrastruktur hilft, kann aber nicht sofort reagieren – das Starten zusätzlicher Datenbank-Read-Replikas dauert Minuten. Das Erstellen neuer API-Gateway-Instanzen dauert Minuten. In diesen Minuten bewertet das Margin-System weiterhin den Wert von Positionen auf Basis beschädigter Preisdaten aus überlasteten Orderbüchern.
Orakelmanipulation und Preisfindungsschwächen
Während der Kettenreaktion im Oktober wurde eine entscheidende Designentscheidung im Margin-System deutlich: Einige Handelsplattformen berechnen den Wert von Sicherheiten auf Basis interner Spotmarktpreise statt externer Orakel-Datenströme. Unter normalen Marktbedingungen sorgen Arbitrageure für Preisparität zwischen verschiedenen Handelsplätzen. Unter Infrastrukturstress bricht diese Kopplung jedoch zusammen.

Abbildung 3: Orakelmanipulations-Flowchart
Dieses interaktive Flussdiagramm visualisiert fünf Phasen des Angriffsvektors:
· Initialer Ausverkauf: 60 millions US-Dollar Verkaufsdruck auf USDe
· Preismanipulation: USDe fällt auf einer einzigen Börse von 1.00 US-Dollar auf 0.65 US-Dollar
· Orakelausfall: Margin-System verwendet beschädigten internen Preisdatenstrom
· Kettenreaktion: Sicherheiten werden abgewertet, Zwangsliquidationen beginnen
· Verstärkung: Insgesamt 19.3 billions US-Dollar Liquidationen (322-fache Verstärkung)
Der Angriff nutzte die Tatsache aus, dass Binance für verpackte synthetische Sicherheiten Spotmarktpreise verwendete. Als der Angreifer 60 millions US-Dollar USDe in ein relativ dünnes Orderbuch warf, fiel der Spotpreis von 1.00 US-Dollar auf 0.65 US-Dollar. Das Margin-System, das Sicherheiten zum Spotpreis bewertet, stufte alle mit USDe besicherten Positionen um 35 % ab. Dies löste Margin-Calls und Zwangsliquidationen für Tausende Konten aus.
Diese Liquidationen zwangen weitere Verkaufsorders in denselben illiquiden Markt, was die Preise weiter drückte. Das Margin-System beobachtete die niedrigeren Preise und bewertete weitere Positionen ab – eine Rückkopplungsschleife, die 60 millions US-Dollar Verkaufsdruck in 19.3 billions US-Dollar Zwangsliquidationen verstärkte.

Abbildung 4: Rückkopplungsschleife der Kettenreaktion von Liquidationen
Dieses Schleifen-Diagramm illustriert die sich selbst verstärkende Natur der Kettenreaktion:
Preisverfall → Liquidation ausgelöst → Zwangsverkauf → weiterer Preisverfall → [Schleife wiederholt sich]
Mit einem gut gestalteten Orakelsystem wäre dieser Mechanismus wirkungslos gewesen. Hätte Binance einen zeitgewichteten Durchschnittspreis (TWAP) über mehrere Handelsplattformen verwendet, hätte eine kurzfristige Preismanipulation die Bewertung der Sicherheiten nicht beeinflusst. Hätten sie aggregierte Preisdatenströme von Chainlink oder anderen Multi-Source-Orakeln genutzt, wäre der Angriff gescheitert.
Das wBETH-Ereignis vier Tage zuvor zeigte eine ähnliche Schwachstelle. wBETH sollte im Verhältnis 1:1 gegen ETH tauschbar sein. Während der Kettenreaktion trocknete die Liquidität aus, der wBETH/ETH-Spotmarkt zeigte einen Abschlag von 20 %. Das Margin-System bewertete wBETH-Sicherheiten entsprechend ab und löste Liquidationen von Positionen aus, die eigentlich vollständig durch ETH gedeckt waren.
Auto-Deleveraging (ADL)-Mechanismus
Wenn Liquidationen nicht zum aktuellen Marktpreis ausgeführt werden können, implementieren Handelsplattformen Auto-Deleveraging (ADL), um Verluste auf profitable Händler zu verteilen. ADL schließt profitable Positionen zum aktuellen Preis zwangsweise, um die Lücke der liquidierten Positionen zu schließen.
Während der Kettenreaktion im Oktober führte Binance ADL auf mehreren Handelspaaren durch. Händler mit profitablen Long-Positionen wurden zwangsweise glattgestellt – nicht wegen ihres eigenen Risikomanagements, sondern weil andere Positionen insolvent wurden.
ADL spiegelt eine grundlegende Architekturentscheidung im zentralisierten Derivatehandel wider. Die Handelsplattform garantiert, dass sie selbst kein Geld verliert. Das bedeutet, dass Verluste von einer oder mehreren der folgenden Parteien getragen werden müssen:
· Versicherungsfonds (von der Plattform reservierte Mittel zur Deckung von Liquidationslücken)
· ADL (Zwangsschließung profitabler Händler)
· Sozialisierte Verluste (Verteilung der Verluste auf alle Nutzer)
Die Größe des Versicherungsfonds im Verhältnis zum offenen Kontraktvolumen bestimmt die Häufigkeit von ADL. Der Versicherungsfonds von Binance belief sich im Oktober 2025 auf etwa 2 billions US-Dollar. Im Verhältnis zu den 4 billions US-Dollar offenen Kontrakten auf BTC-, ETH- und BNB-Perpetuals entsprach dies einer Deckung von 50 %. Während der Kettenreaktion im Oktober überstieg das offene Kontraktvolumen aller Handelspaare jedoch 20 billions US-Dollar. Der Versicherungsfonds konnte die Lücke nicht decken.
Nach dem Ereignis im Oktober kündigte Binance an, dass sie bei einem offenen Kontraktvolumen unter 4 billions US-Dollar für BTC-, ETH- und BNB-USDⓈ-M-Kontrakte ADL ausschließen. Dies schafft einen Anreiz: Die Plattform kann einen größeren Versicherungsfonds unterhalten, um ADL zu vermeiden, bindet damit aber Kapital, das sonst profitabel eingesetzt werden könnte.
On-Chain-Ausfälle: Grenzen von Blockchain-Protokollen
Das Balkendiagramm vergleicht die Ausfallzeiten verschiedener Ereignisse:
· Solana (Februar 2024): 5 Stunden – Engpass bei der Abstimmungsdurchsatz
· Polygon (März 2024): 11 Stunden – Versionsinkompatibilität der Validatoren
· Optimism (Juni 2024): 2,5 Stunden – Sequencer-Überlastung (Airdrop)
· Solana (September 2024): 4,5 Stunden – Spam-Angriff auf Transaktionen
· Arbitrum (Dezember 2024): 1,5 Stunden – Ausfall des RPC-Anbieters
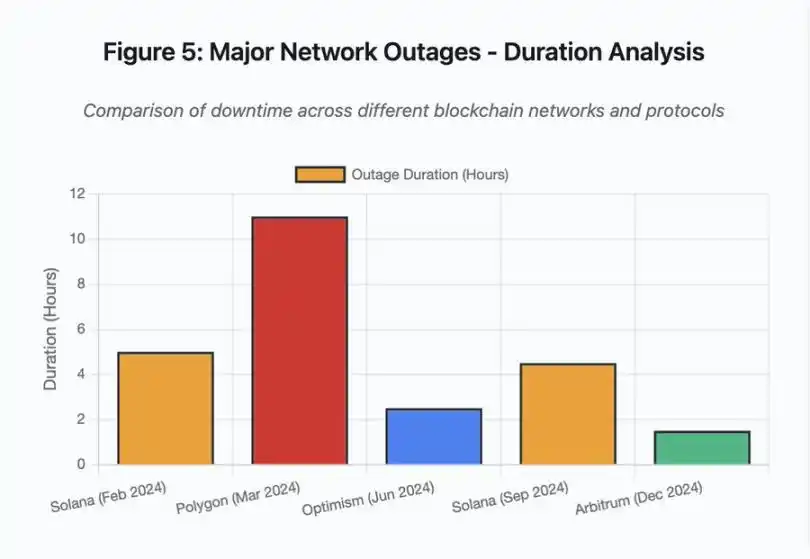
Abbildung 5: Hauptnetzwerkausfälle – Daueranalyse
Solana: Konsens-Engpass
Solana erlebte zwischen 2024 und 2025 mehrere Ausfälle. Der Ausfall im Februar 2024 dauerte etwa 5 Stunden, der im September 2024 4–5 Stunden. Beide Ausfälle hatten ähnliche Ursachen: Das Netzwerk konnte während Spam-Angriffen oder extremer Aktivität das Transaktionsvolumen nicht bewältigen.
Abbildung 5 im Detail: Die Ausfälle von Solana (Februar: 5 Stunden, September: 4,5 Stunden) verdeutlichen das wiederkehrende Problem der Netzwerkausfallsicherheit unter Stress.
Solanas Architektur ist auf Durchsatz optimiert. Unter Idealbedingungen verarbeitet das Netzwerk 3.000–5.000 Transaktionen pro Sekunde mit subsekündärer Finalität – eine Größenordnung schneller als Ethereum. Doch bei Stressereignissen schafft diese Optimierung Schwachstellen.
Der Ausfall im September 2024 wurde durch eine Flut von Spam-Transaktionen ausgelöst, die das Abstimmungssystem der Validatoren überforderte. Solana-Validatoren müssen für Blöcke abstimmen, um Konsens zu erreichen. Im Normalbetrieb priorisieren Validatoren Abstimmungstransaktionen, um den Konsensfortschritt zu sichern. Das Protokoll behandelte Abstimmungstransaktionen jedoch zuvor im Gebührenmarkt wie normale Transaktionen.
Wenn der Transaktionspool mit Millionen Spam-Transaktionen gefüllt ist, können Validatoren Abstimmungstransaktionen nicht mehr effizient weiterleiten. Ohne genügend Abstimmungen werden Blöcke nicht finalisiert. Ohne finalisierte Blöcke stoppt die Chain. Nutzer mit ausstehenden Transaktionen sehen diese im Pool feststecken. Neue Transaktionen können nicht eingereicht werden.
StatusGator dokumentierte mehrere Solana-Serviceausfälle 2024–2025, während Solana diese nie offiziell anerkannte. Das schafft Informationsasymmetrien. Nutzer können lokale Verbindungsprobleme nicht von netzwerkweiten Ausfällen unterscheiden. Drittanbieter-Monitoring sorgt für Transparenz, aber Plattformen sollten umfassende Statusseiten pflegen.
Ethereum: Gasgebühren-Explosion
Ethereum erlebte während des DeFi-Booms 2021 extreme Gasgebührenspitzen – einfache Transfers kosteten über 100 US-Dollar, komplexe Smart-Contract-Interaktionen 500–1.000 US-Dollar. Diese Gebühren machten das Netzwerk für kleinere Transaktionen unbrauchbar und eröffneten einen neuen Angriffsvektor: MEV-Extraktion.
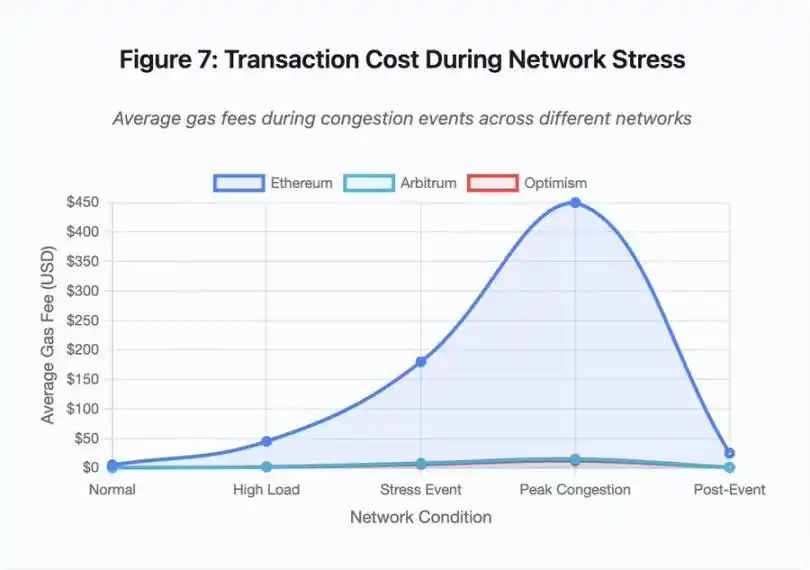
Abbildung 7: Transaktionskosten während Netzwerkstress
Das Liniendiagramm zeigt dramatisch die Gasgebührenerhöhungen während Stressereignissen auf verschiedenen Netzwerken:
· Ethereum: 5 US-Dollar (normal) → 450 US-Dollar (Spitzenlast) – 90-fache Steigerung
· Arbitrum: 0,50 US-Dollar → 15 US-Dollar – 30-fache Steigerung
· Optimism: 0,30 US-Dollar → 12 US-Dollar – 40-fache Steigerung
Die Visualisierung zeigt, dass auch Layer-2-Lösungen erhebliche Gasgebührenerhöhungen erlebten, wenn auch von einem niedrigeren Ausgangsniveau.
Maximal extrahierbarer Wert (MEV) beschreibt den Gewinn, den Validatoren durch das Umordnen, Einfügen oder Ausschließen von Transaktionen erzielen können. In einem Umfeld hoher Gasgebühren wird MEV besonders lukrativ. Arbitrageure versuchen, große DEX-Trades zu frontrunnen, Liquidationsbots konkurrieren um die schnellste Liquidation unterbesicherter Positionen. Dieser Wettbewerb äußert sich als Gasgebotskrieg.
Nutzer, die während Überlastung sicherstellen wollen, dass ihre Transaktion aufgenommen wird, müssen mehr bieten als MEV-Bots. Das führt zu Situationen, in denen die Transaktionsgebühr den Transaktionswert übersteigt. Möchten Sie Ihren 100 US-Dollar Airdrop beanspruchen? Zahlen Sie 150 US-Dollar Gasgebühr. Müssen Sie Sicherheiten hinzufügen, um eine Liquidation zu vermeiden? Sie konkurrieren mit Bots, die 500 US-Dollar Prioritätsgebühr zahlen.
Ethereums Gaslimit begrenzt die Gesamtberechnung pro Block. Bei Überlastung bieten Nutzer um den knappen Blockspace. Der Gebührenmarkt funktioniert wie vorgesehen: Wer mehr bietet, erhält Vorrang. Doch dieses Design macht das Netzwerk bei hoher Nutzung immer teurer – genau dann, wenn Nutzer den Zugang am dringendsten benötigen.
Layer-2-Lösungen versuchen, dieses Problem zu lösen, indem sie Berechnungen off-chain verlagern und gleichzeitig durch regelmäßige Abrechnungen die Sicherheit von Ethereum erben. Optimism, Arbitrum und andere Rollups verarbeiten Tausende Transaktionen off-chain und reichen dann komprimierte Beweise bei Ethereum ein. Diese Architektur senkt die Kosten pro Transaktion im Normalbetrieb erfolgreich.
Layer 2: Sequencer-Engpass
Doch Layer-2-Lösungen bringen neue Engpässe mit sich. Optimism erlebte im Juni 2024 einen Ausfall, als 250.000 Adressen gleichzeitig einen Airdrop beanspruchten. Der Sequencer, der Transaktionen vor der Einreichung bei Ethereum sortiert, war überfordert, Nutzer konnten stundenlang keine Transaktionen einreichen.
Dieser Ausfall zeigt, dass die Verlagerung von Berechnungen off-chain den Infrastrukturbedarf nicht beseitigt. Der Sequencer muss eingehende Transaktionen verarbeiten, sortieren, ausführen und Beweise für die Abrechnung auf Ethereum generieren. Bei extremem Traffic steht der Sequencer vor denselben Skalierungsherausforderungen wie eine eigenständige Blockchain.
Es müssen mehrere RPC-Anbieter verfügbar bleiben. Fällt der Hauptanbieter aus, sollten Nutzer nahtlos auf Alternativen umschalten können. Während des Optimism-Ausfalls funktionierten einige RPC-Anbieter, andere nicht. Nutzer, deren Wallets standardmäßig mit einem ausgefallenen Anbieter verbunden waren, konnten nicht mit der Chain interagieren, obwohl diese selbst online war.
Die AWS-Ausfälle haben wiederholt das zentrale Infrastrukturrisiko im Krypto-Ökosystem aufgezeigt:
· 20. Oktober 2025 (heute): US-East-1-Ausfall betrifft Coinbase sowie Venmo, Robinhood und Chime. AWS bestätigt erhöhte Fehlerquoten bei DynamoDB und EC2.
· April 2025: Regionaler Ausfall betrifft gleichzeitig Binance, KuCoin und MEXC. Mehrere große Börsen waren nicht verfügbar, als ihre AWS-gehosteten Komponenten ausfielen.
· Dezember 2021: US-East-1-Ausfall legt Coinbase, Binance.US und die „dezentrale“ Handelsplattform dYdX für 8–9 Stunden lahm, gleichzeitig sind Amazons eigene Lager und große Streamingdienste betroffen.
· März 2017: S3-Ausfall verhindert, dass Nutzer sich fünf Stunden lang bei Coinbase und GDAX anmelden können, begleitet von weitreichenden Internetausfällen.
Das Muster ist klar: Diese Handelsplattformen hosten kritische Komponenten auf AWS-Infrastruktur. Wenn AWS einen regionalen Ausfall erlebt, werden mehrere große Handelsplattformen und Dienste gleichzeitig unzugänglich. Nutzer können während des Ausfalls nicht auf Gelder zugreifen, keine Trades ausführen oder Positionen anpassen – genau dann, wenn Marktvolatilität sofortiges Handeln erfordern könnte.
Polygon: Konsens-Versionsinkompatibilität
Polygon (ehemals Matic) erlebte im März 2024 einen 11-stündigen Ausfall. Die Ursache war eine Versionsinkompatibilität der Validatoren: Einige Validatoren liefen mit alter Software, andere mit aktualisierter Version. Diese Versionen berechneten Statusänderungen unterschiedlich.
Abbildung 5 im Detail: Der Polygon-Ausfall (11 Stunden) war der längste der analysierten Ereignisse und unterstreicht die Schwere von Konsensfehlern.
Wenn Validatoren zu unterschiedlichen Ergebnissen über den korrekten Status kommen, scheitert der Konsens, die Chain kann keine neuen Blöcke produzieren, weil sich die Validatoren nicht auf die Blockgültigkeit einigen können. Es entsteht eine Pattsituation: Validatoren mit alter Software lehnen Blöcke von Validatoren mit neuer Software ab – und umgekehrt.
Die Lösung erfordert koordinierte Upgrades der Validatoren, was während eines Ausfalls Zeit kostet. Jeder Validator-Betreiber muss kontaktiert, die richtige Softwareversion bereitgestellt und der Validator neu gestartet werden. In einem dezentralen Netzwerk mit Hunderten unabhängiger Validatoren kann diese Koordination Stunden oder Tage dauern.
Hard Forks werden meist durch Blockhöhen ausgelöst. Alle Validatoren aktualisieren vor einer bestimmten Blockhöhe, um gleichzeitige Aktivierung zu gewährleisten – das erfordert vorherige Koordination. Stufenweise Upgrades, bei denen Validatoren nach und nach neue Versionen übernehmen, bergen das Risiko genau der Versionsinkompatibilität, die zum Polygon-Ausfall führte.
Architektur-Trade-offs
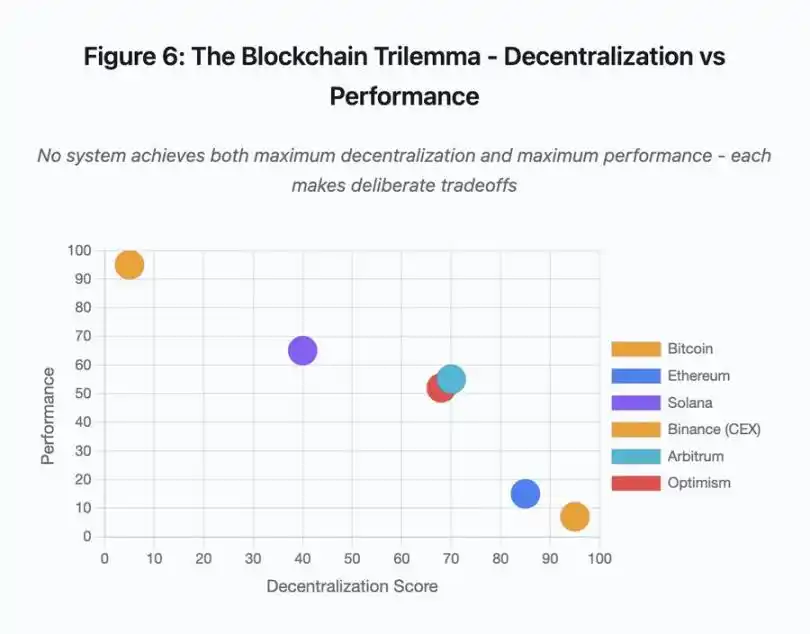
Abbildung 6: Blockchain-Trilemma – Dezentralisierung vs. Performance
Dieses Streudiagramm visualisiert die Zuordnung verschiedener Systeme zu zwei Schlüsseldimensionen:
· Bitcoin: hohe Dezentralisierung, geringe Performance
· Ethereum: hohe Dezentralisierung, mittlere Performance
· Solana: mittlere Dezentralisierung, hohe Performance
· Binance (CEX): minimale Dezentralisierung, maximale Performance
· Arbitrum/Optimism: mittelhohe Dezentralisierung, mittlere Performance
Wesentliche Erkenntnis: Kein System erreicht gleichzeitig maximale Dezentralisierung und maximale Performance – jedes Design trifft wohlüberlegte Kompromisse für unterschiedliche Anwendungsfälle.
Zentralisierte Handelsplattformen erreichen niedrige Latenz durch architektonische Einfachheit – Matching-Engines verarbeiten Orders in Mikrosekunden, der Status liegt in zentralen Datenbanken. Es gibt keinen Konsens-Overhead, aber diese Einfachheit schafft Single Points of Failure, und unter Stress verbreiten sich Kaskadenausfälle durch eng gekoppelte Systeme.
Dezentrale Protokolle verteilen den Status auf Validatoren und eliminieren Single Points of Failure. Hochdurchsatz-Chains behalten diese Eigenschaft auch während Ausfällen (keine Verluste von Geldern, nur temporärer Aktivitätsverlust). Doch Konsens zwischen verteilten Validatoren erzeugt Rechenaufwand – Validatoren müssen sich vor Finalisierung von Statusänderungen einigen. Bei inkompatiblen Versionen oder überwältigendem Traffic kann der Konsensprozess temporär stoppen.
Mehr Replikate erhöhen die Fehlertoleranz, steigern aber die Koordinationskosten. In byzantinisch fehlertoleranten Systemen erhöht jeder zusätzliche Validator den Kommunikationsaufwand. Hochdurchsatz-Architekturen minimieren diesen Aufwand durch optimierte Validator-Kommunikation und erreichen so hohe Performance, sind aber anfällig für bestimmte Angriffsvektoren. Sicherheitsorientierte Architekturen priorisieren Validator-Diversität und robuste Konsensmechanismen, begrenzen den Durchsatz der Basisschicht und maximieren die Resilienz.
Layer-2-Lösungen versuchen, beide Eigenschaften durch Schichtung zu bieten. Sie erben die Sicherheit von Ethereum durch L1-Abrechnung und bieten gleichzeitig hohen Durchsatz durch Off-Chain-Berechnung. Doch sie führen neue Engpässe auf Sequencer- und RPC-Ebene ein, was zeigt, dass architektonische Komplexität beim Lösen eines Problems neue Fehlermuster schafft.
Skalierung bleibt das Grundproblem
Diese Ereignisse zeigen ein konsistentes Muster: Systeme werden für normale Last konfiguriert und scheitern dann unter Stress katastrophal. Solana verarbeitet regulären Traffic effizient, bricht aber bei 10.000 % mehr Transaktionen zusammen. Ethereums Gasgebühren bleiben moderat, bis DeFi-Nutzung Überlastung auslöst. Optimisms Infrastruktur funktioniert gut, bis 250.000 Adressen gleichzeitig einen Airdrop beanspruchen. Die Binance-API funktioniert im normalen Handel, wird aber während einer Kettenreaktion von Liquidationen zum Flaschenhals.
Das Ereignis im Oktober 2025 demonstrierte diese Dynamik auf Börsenebene. Im Normalbetrieb sind die API-Rate-Limits und Datenbankverbindungen von Binance ausreichend, doch während der Kettenreaktion, wenn jeder Händler gleichzeitig seine Position anpassen will, werden diese Limits zum Engpass. Das Margin-System, das die Börse durch Zwangsliquidationen schützen soll, verstärkte die Krise, indem es zum schlechtesten Zeitpunkt Zwangsverkäufer schuf.
Autoskalierung bietet keinen ausreichenden Schutz gegen sprunghafte Laststeigerungen. Das Starten zusätzlicher Server dauert Minuten, in denen das Margin-System den Wert von Positionen auf Basis beschädigter Preisdaten aus dünnen Orderbüchern bewertet – bis neue Kapazitäten online sind, hat sich die Kettenreaktion bereits ausgebreitet.
Eine Überkonfiguration für seltene Stressereignisse kostet im Normalbetrieb Geld. Börsenbetreiber optimieren für typische Lasten und akzeptieren gelegentliche Ausfälle als wirtschaftlich vernünftige Wahl. Die Kosten für Ausfallzeiten werden auf die Nutzer abgewälzt, die während kritischer Marktbewegungen Liquidationen, eingefrorene Trades oder den Verlust des Zugriffs auf Gelder erleben.
Infrastrukturverbesserungen
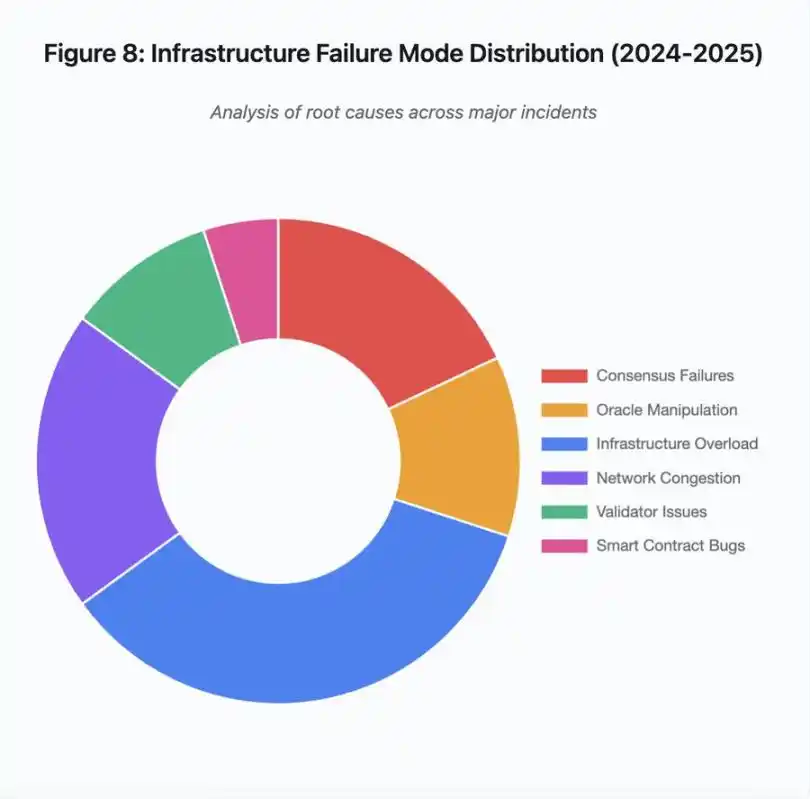
Abbildung 8: Verteilung der Infrastrukturausfallmuster (2024–2025)
Das Kreisdiagramm der Grundursachen zeigt:
· Infrastrukturüberlastung: 35 % (am häufigsten)
· Netzwerküberlastung: 20 %
· Konsensfehler: 18 %
· Orakelmanipulation: 12 %
· Validator-Probleme: 10 %
· Smart-Contract-Schwachstellen: 5 %
Mehrere Architekturänderungen können die Häufigkeit und Schwere von Ausfällen verringern, auch wenn jede mit Kompromissen verbunden ist:
Trennung von Preissystem und Liquidationssystem
Das Problem im Oktober resultierte teilweise aus der Kopplung der Margin-Berechnung an Spotmarktpreise. Die Verwendung von Umtauschverhältnissen statt Spotpreisen für verpackte Assets hätte die Fehlbewertung von wBETH verhindert. Generell sollten zentrale Risikomanagementsysteme nicht von manipulierbaren Marktdaten abhängen. Unabhängige Orakelsysteme mit Multi-Source-Aggregation und TWAP-Berechnung liefern robustere Preisdatenströme.
Überkonfiguration und redundante Infrastruktur
Der AWS-Ausfall im April 2025, der Binance, KuCoin und MEXC betraf, zeigte das Risiko zentralisierter Infrastrukturabhängigkeit. Kritische Komponenten über mehrere Cloud-Anbieter zu betreiben, erhöht die operative Komplexität und Kosten, eliminiert aber Korrelationen bei Ausfällen. Layer-2-Netzwerke können mehrere RPC-Anbieter mit automatischem Failover unterhalten. Die zusätzlichen Kosten erscheinen im Normalbetrieb als Verschwendung, verhindern aber stundenlange Ausfälle bei Spitzenlast.
Verbesserte Stresstests und Kapazitätsplanung
Das Muster, dass Systeme im Normalbetrieb gut laufen und dann versagen, zeigt unzureichende Tests unter Stress. Die Simulation des 100-fachen der normalen Last sollte Standard sein – das Erkennen von Engpässen in der Entwicklung ist günstiger als während eines echten Ausfalls. Realistische Lasttests bleiben jedoch herausfordernd. Produktions-Traffic zeigt Muster, die synthetische Tests nicht vollständig abbilden können, und das Verhalten der Nutzer unterscheidet sich im Ernstfall von Testsituationen.
Der Weg nach vorn
Überkonfiguration ist die zuverlässigste Lösung, steht aber im Widerspruch zu wirtschaftlichen Anreizen. Für seltene Ereignisse eine zehnfache Überkapazität vorzuhalten, kostet täglich Geld, um ein Problem zu verhindern, das vielleicht einmal im Jahr auftritt. Solange katastrophale Ausfälle nicht genug Kosten verursachen, um Überkonfiguration zu rechtfertigen, werden Systeme unter Stress weiter versagen.
Regulatorischer Druck könnte Veränderungen erzwingen. Wenn Vorschriften 99,9 % Betriebszeit oder maximale Ausfallzeiten vorschreiben, müssen Handelsplattformen überkonfigurieren. Doch Regulierung folgt meist auf Katastrophen, nicht zur Prävention. Der Zusammenbruch von Mt. Gox 2014 führte zur Einführung formeller Krypto-Börsenregulierung in Japan. Das Kettenreaktionsereignis im Oktober 2025 dürfte eine ähnliche regulatorische Reaktion auslösen. Ob diese auf Ergebnisvorgaben (maximale Ausfallzeit, maximaler Slippage bei Liquidationen) oder auf Implementierungsvorgaben (bestimmte Orakel-Anbieter, Circuit-Breaker-Schwellen) abzielen, bleibt abzuwarten.
Die grundlegende Herausforderung ist, dass diese Systeme rund um die Uhr auf globalen Märkten laufen, aber auf Infrastruktur basieren, die für traditionelle Geschäftszeiten konzipiert wurde. Wenn der Stress um 02:00 Uhr auftritt, eilen Teams herbei, um Patches zu deployen, während Nutzer mit steigenden Verlusten konfrontiert sind. Traditionelle Märkte stoppen den Handel bei Stress; Kryptomärkte brechen einfach zusammen. Ob das ein Feature oder ein Bug ist, hängt von Perspektive und Standpunkt ab.
Blockchain-Systeme haben in kurzer Zeit eine bemerkenswerte technische Komplexität erreicht. Die Aufrechterhaltung eines verteilten Konsenses über Tausende Knoten ist eine echte Ingenieursleistung. Doch Zuverlässigkeit unter Stress erfordert den Übergang von Prototyp-Architekturen zu produktionsreifen Infrastrukturen. Dieser Wandel erfordert Investitionen und die Priorisierung von Robustheit über Feature-Entwicklungsgeschwindigkeit.
Die Herausforderung besteht darin, Robustheit über Wachstum zu stellen – gerade in Bullenmärkten, wenn alle Geld verdienen und Ausfälle als Problem anderer erscheinen. Wenn das nächste Stressereignis das System testet, werden neue Schwachstellen sichtbar. Ob die Branche aus Oktober 2025 lernt oder das Muster wiederholt, bleibt offen. Die Geschichte zeigt, dass wir die nächste kritische Schwachstelle durch einen weiteren milliardenschweren Ausfall unter Stress entdecken werden.
Haftungsausschluss: Der Inhalt dieses Artikels gibt ausschließlich die Meinung des Autors wieder und repräsentiert nicht die Plattform in irgendeiner Form. Dieser Artikel ist nicht dazu gedacht, als Referenz für Investitionsentscheidungen zu dienen.
Das könnte Ihnen auch gefallen
Tiefgründige Reflexion: Ich habe acht Jahre meines Lebens in der Krypto-Branche verschwendet
In den letzten Tagen hat ein Artikel mit dem Titel „Ich habe acht Jahre meines Lebens in der Krypto-Branche verschwendet“ auf Twitter über eine Million Aufrufe und breite Resonanz ausgelöst. Der Inhalt spricht die Casino-Natur und die Tendenz zum Nihilismus im Kryptobereich direkt an. ChainCatcher hat diesen Artikel nun übersetzt, um den Austausch und die Diskussion zu fördern.

Warum treiben die zahlreichen neuen Altcoin-ETFs die Coin-Preise nicht an?

Die „DA-Dämmerung“ von Ethereum: Wie das Fusaka-Upgrade Celestia und Avail „überflüssig“ erscheinen lässt?
Der Artikel untersucht das Konzept der modularen Blockchains sowie den Prozess, wie Ethereum durch das Fusaka-Upgrade seine Leistung verbessert. Es werden die Herausforderungen von DA-Schichten wie Celestia und die Vorteile von Ethereum analysiert. Zusammenfassung erstellt von Mars AI Diese Zusammenfassung wurde vom Mars AI-Modell erstellt; ihre Genauigkeit und Vollständigkeit befinden sich noch in der iterativen Entwicklungsphase.
Der steigende Bitcoin-„Liveliness“-Indikator deutet darauf hin, dass der Bullenmarkt anhalten könnte: Analysten
