
Diventa virale! Il modello AI di Meituan diventa popolare grazie alla sua "velocità"

Sviluppatori in patria e all'estero: testato personalmente, il nuovo modello open source di Meituan è super veloce!
Quando l'AI diventerà davvero diffusa come l'acqua e l'elettricità, la potenza del modello non sarà più l'unica preoccupazione di tutti.
Dall'inizio dell'anno con Claude 3.7 Sonnet, Gemini 2.5 Flash fino ai recenti GPT-5 e DeepSeek V3.1, tutti i principali produttori di modelli stanno riflettendo su come, garantendo l'accuratezza, permettere all'AI di risolvere ogni problema con il minimo calcolo possibile e rispondere nel minor tempo possibile. In altre parole, come evitare di sprecare sia token che tempo.
Per le aziende e gli sviluppatori che costruiscono applicazioni sui modelli, questo passaggio da "costruire semplicemente il modello più potente" a "costruire modelli più pratici e veloci" è una buona notizia. E ciò che è ancora più confortante è che i modelli open source correlati stanno diventando sempre più numerosi.
Qualche giorno fa, su HuggingFace abbiamo scoperto un nuovo modello: LongCat-Flash-Chat.

Questo modello proviene dalla serie LongCat-Flash di Meituan, utilizzabile direttamente dal sito ufficiale.
Sa naturalmente che "not all tokens are equal", quindi assegna dinamicamente il budget di calcolo ai token importanti in base alla loro rilevanza. Questo gli permette di raggiungere prestazioni comparabili ai migliori modelli open source attuali, attivando solo una piccola quantità di parametri.

Dopo l'open source, LongCat-Flash è diventato trending topic.
Allo stesso tempo, la velocità di questo modello ha lasciato tutti molto impressionati: su una scheda grafica H800, la velocità di inferenza supera i 100 token al secondo. I test di sviluppatori sia cinesi che stranieri lo confermano: alcuni hanno raggiunto una velocità di 95 token/s, altri hanno ottenuto risposte paragonabili a quelle di Claude in tempi brevissimi.
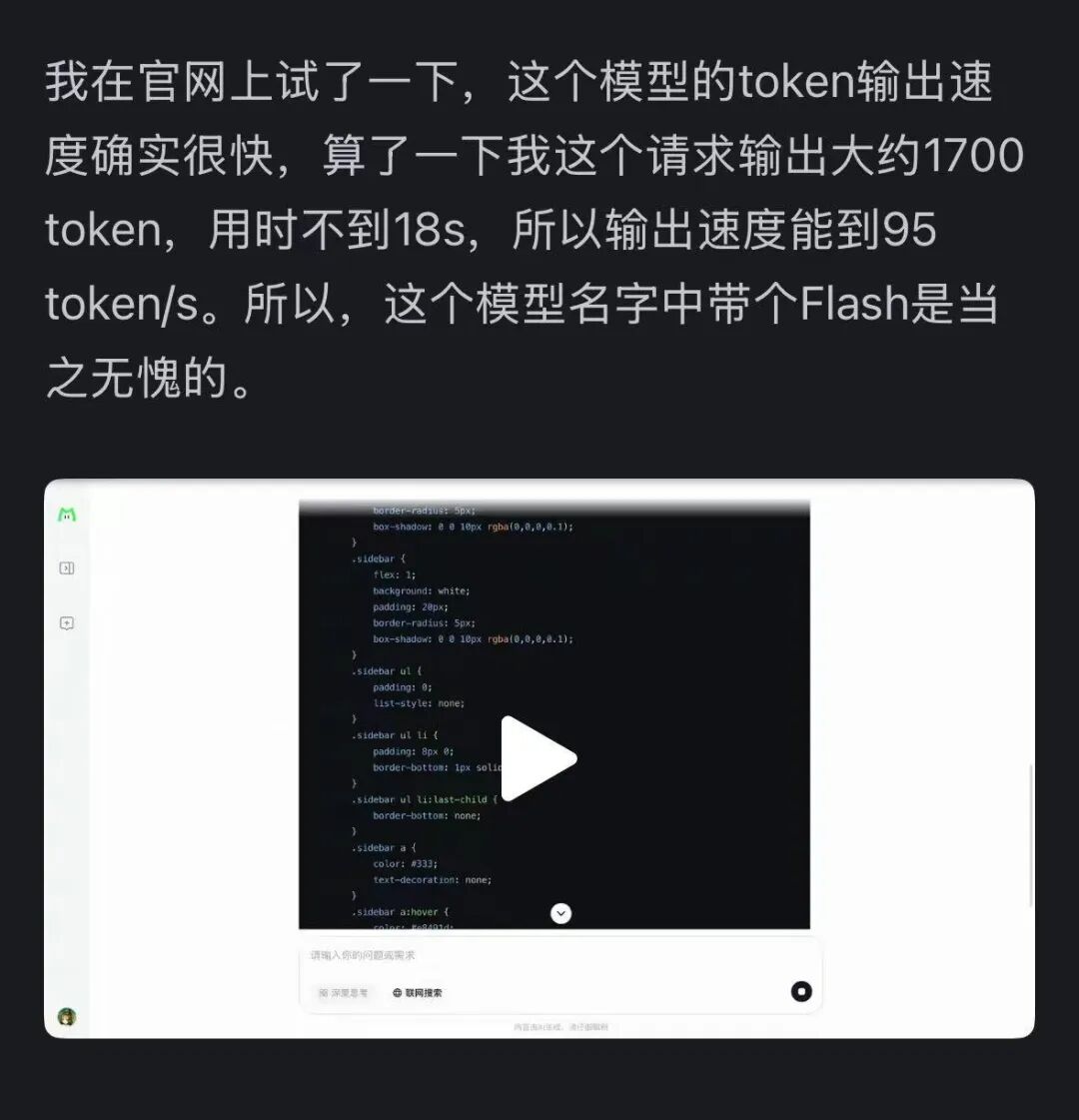
Fonte immagine: utente Zhihu @小小将.
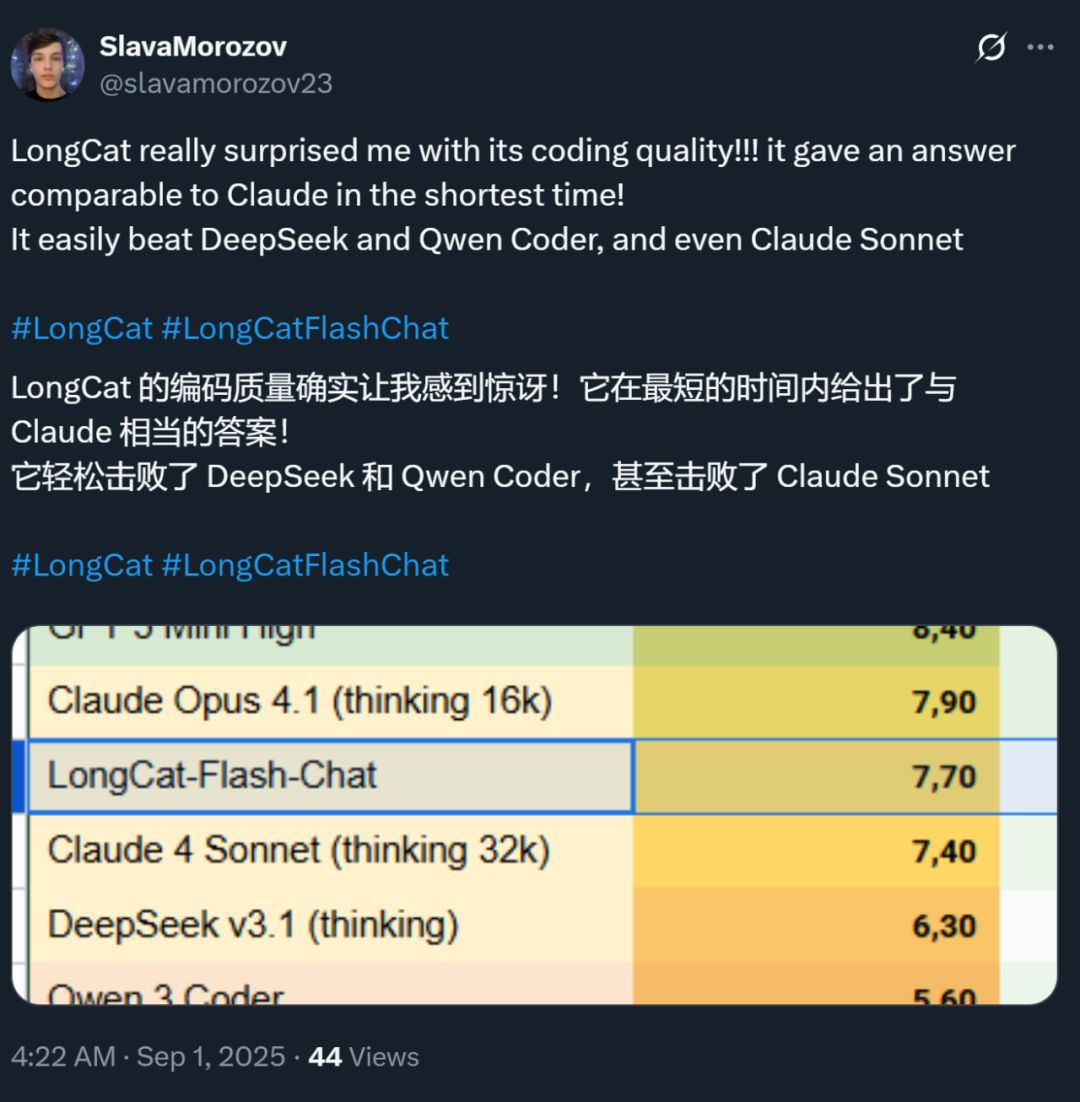
Fonte immagine: utente X @SlavaMorozov.
Oltre al modello open source, Meituan ha anche pubblicato il rapporto tecnico di LongCat-Flash, dove possiamo trovare molti dettagli tecnici.

Rapporto tecnico: LongCat-Flash Technical Report
In questo articolo, lo presenteremo in dettaglio.
Come risparmiare potenza di calcolo nei grandi modelli?
Scopriamo le innovazioni architetturali e i metodi di training di LongCat-Flash
LongCat-Flash è un modello a esperti misti con un totale di 560 miliardi di parametri, in grado di attivare da 18.6 a 31.3 miliardi (in media 27 miliardi) di parametri in base alle esigenze contestuali.
La quantità di dati utilizzata per addestrare questo modello supera i 200 trilioni di token, ma il tempo di training è stato di meno di 30 giorni. Inoltre, durante questo periodo, il sistema ha raggiunto un uptime del 98,48%, quasi senza necessità di intervento umano per gestire i guasti: ciò significa che l'intero processo di training è stato praticamente "senza intervento umano" e completamente automatico.
Ancora più impressionante è che il modello così addestrato si comporta altrettanto bene anche in fase di deployment reale.
Come mostrato nell'immagine qui sotto, in quanto modello non di ragionamento, LongCat-Flash ha raggiunto prestazioni paragonabili ai migliori modelli non di ragionamento SOTA, tra cui DeepSeek-V3.1 e Kimi-K2, con meno parametri e una velocità di inferenza superiore. Questo lo rende molto competitivo e pratico in ambiti come uso generale, programmazione e strumenti agent.
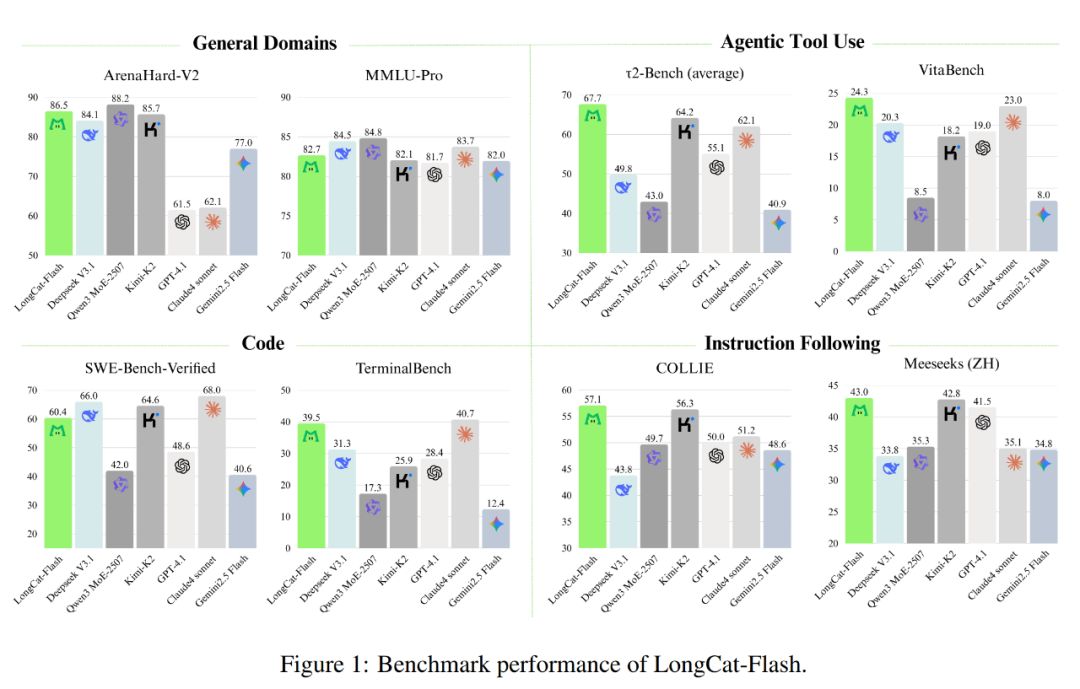
Inoltre, anche il suo costo è notevole: solo 0,7 dollari per ogni milione di token generati. Questo prezzo, rispetto ai modelli di pari scala sul mercato, è davvero molto conveniente.
Dal punto di vista tecnico, LongCat-Flash punta principalmente a due obiettivi dei modelli linguistici: efficienza computazionale e capacità agent, integrando innovazione architetturale e metodi di training multi-stage, per realizzare un sistema di modelli scalabile e intelligente.
Per quanto riguarda l'architettura, LongCat-Flash adotta una nuova architettura MoE (figura 2), con due punti salienti:
Esperti a zero calcolo (Zero-computation Experts);
MoE con connessione rapida (Shortcut-connected MoE, ScMoE).
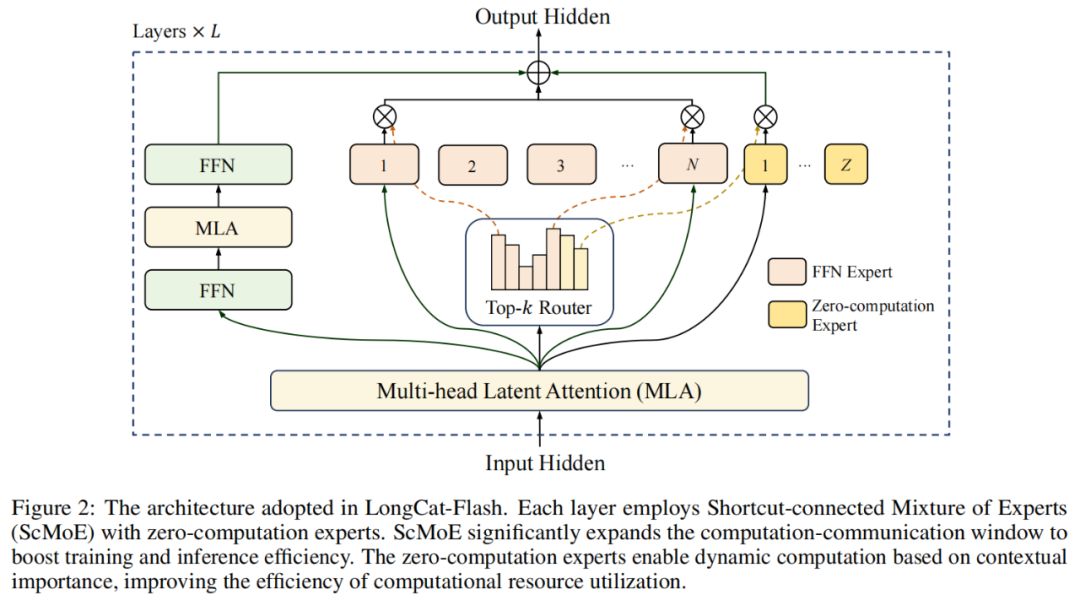
Esperti a zero calcolo
L'idea centrale degli esperti a zero calcolo è che non tutti i token sono "uguali".
Possiamo capirlo così: in una frase, alcune parole sono molto facili da prevedere, come "di", "è", che quasi non richiedono calcolo, mentre altre, come i nomi propri, richiedono molti calcoli per essere previste correttamente.
Nelle ricerche precedenti, si adottava generalmente questo approccio: indipendentemente dalla complessità del token, veniva attivato un numero fisso (K) di esperti, causando un enorme spreco di calcolo. Per i token semplici, non è necessario chiamare così tanti esperti, mentre per quelli complessi, potrebbe non esserci abbastanza calcolo assegnato.
Ispirandosi a ciò, LongCat-Flash ha proposto un meccanismo di allocazione dinamica delle risorse di calcolo: tramite gli esperti a zero calcolo, per ogni token vengono attivati dinamicamente diversi FFN (Feed-Forward Network) esperti, allocando così il calcolo in modo più ragionevole in base all'importanza contestuale.
In concreto, LongCat-Flash, oltre agli N esperti FFN standard, aggiunge Z esperti a zero calcolo nel suo pool di esperti. Gli esperti a zero calcolo restituiscono semplicemente l'input come output, senza introdurre costi computazionali aggiuntivi.
Il modulo MoE di LongCat-Flash può essere formalizzato come segue:
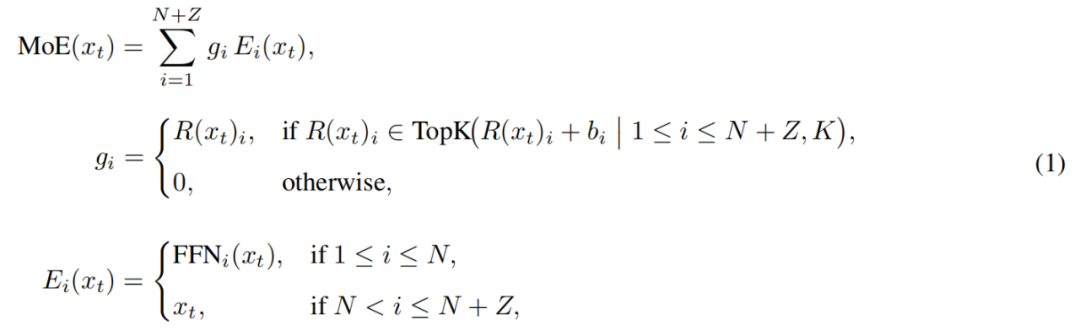
Dove x_t è il t-esimo token della sequenza di input, R rappresenta il router softmax, b_i è il bias relativo all'i-esimo esperto, K è il numero di esperti selezionati per ogni token. Il router assegna ogni token a K esperti, e il numero di FFN attivati varia in base all'importanza contestuale del token. Grazie a questo meccanismo adattivo, il modello può imparare ad allocare più risorse di calcolo ai token più importanti, ottenendo prestazioni migliori a parità di calcolo, come mostrato in figura 3a.
Inoltre, il modello, durante l'elaborazione dell'input, deve imparare a decidere se vale la pena allocare più risorse di calcolo in base all'importanza dei token. Se non si controlla la frequenza di selezione degli esperti a zero calcolo, il modello potrebbe preferire gli esperti computazionali, trascurando quelli a zero calcolo, riducendo così l'efficienza delle risorse.
Per risolvere questo problema, Meituan ha migliorato il meccanismo di bias degli esperti nella strategia aux-loss-free: ha introdotto un bias specifico per ogni esperto, che può regolare dinamicamente il punteggio di routing in base all'utilizzo recente dell'esperto, mantenendo al contempo la separazione dall'obiettivo di training del modello linguistico.
La regola di aggiornamento adotta un controller PID della teoria del controllo per regolare in tempo reale il bias degli esperti. Grazie a ciò, il modello, per ogni token, deve attivare solo da 18.6 a 31.3 miliardi (media circa 27 miliardi) di parametri, ottimizzando la configurazione delle risorse.
MoE con connessione rapida
L'altro punto di forza di LongCat-Flash è il meccanismo MoE con connessione rapida.
In generale, l'efficienza dei modelli MoE di grandi dimensioni è fortemente limitata dai costi di comunicazione. Nel paradigma tradizionale, la parallelizzazione degli esperti introduce un flusso di lavoro sequenziale: prima bisogna effettuare una comunicazione globale per instradare i token agli esperti assegnati, poi può iniziare il calcolo.
Questa sequenza comunicazione-calcolo comporta tempi di attesa aggiuntivi, soprattutto nel training distribuito su larga scala, dove la latenza di comunicazione può diventare un collo di bottiglia.
In precedenza, alcuni ricercatori hanno adottato architetture di esperti condivisi, cercando di sovrapporre la comunicazione al calcolo di un singolo esperto, ma l'efficienza era limitata dalla piccola finestra di calcolo del singolo esperto.
Meituan ha superato questo limite introducendo l'architettura ScMoE, che inserisce una connessione rapida tra i livelli. Questa innovazione chiave permette che il calcolo del FFN denso del livello precedente possa essere eseguito in parallelo con la comunicazione di dispatch/aggregate del livello MoE corrente, creando una finestra di sovrapposizione comunicazione-calcolo molto più ampia rispetto all'architettura di esperti condivisi.
Questa progettazione architetturale è stata verificata in numerosi esperimenti.
Innanzitutto, il design ScMoE non riduce la qualità del modello. Come mostrato in figura 4, la curva di perdita in training dell'architettura ScMoE è quasi identica a quella della baseline senza ScMoE, dimostrando che questo riordino dell'esecuzione non compromette le prestazioni del modello. Questo risultato è stato confermato in diverse configurazioni.
Ancora più importante, questi risultati mostrano che la stabilità e i vantaggi prestazionali di ScMoE sono ortogonali alla scelta della specifica meccanica di attenzione (cioè, indipendentemente dal tipo di attenzione utilizzata, si mantengono stabilità e benefici).
Inoltre, l'architettura ScMoE offre notevoli miglioramenti di efficienza a livello di sistema sia in training che in inferenza. In particolare:
Nel training su larga scala: la finestra di sovrapposizione estesa consente che il calcolo dei blocchi precedenti sia completamente parallelo alle fasi di dispatch e aggregate del livello MoE, suddividendo le operazioni in blocchi a grana fine lungo la dimensione dei token.
Nell'inferenza efficiente: ScMoE supporta pipeline overlapped in single batch, riducendo il tempo teorico per token output (TPOT) di quasi il 50% rispetto a modelli leader come DeepSeek-V3. Ancora più importante, consente l'esecuzione concorrente di diverse modalità di comunicazione: la comunicazione tensor-parallel interna al nodo per il FFN denso (tramite NVLink) può essere completamente sovrapposta alla comunicazione tra nodi degli esperti (tramite RDMA), massimizzando l'utilizzo della rete.
In sintesi, ScMoE offre notevoli miglioramenti prestazionali senza sacrificare la qualità del modello.
Strategia di espansione del modello e training multi-stage
Meituan ha anche proposto una strategia efficiente di espansione del modello che migliora significativamente le prestazioni del modello all'aumentare della scala.
Per prima cosa, il trasferimento degli iperparametri: nel training di modelli di grandissima scala, provare direttamente diverse configurazioni di iperparametri è molto costoso e instabile. Meituan quindi sperimenta prima su modelli più piccoli per trovare la combinazione ottimale di iperparametri, poi trasferisce questi parametri al modello grande, risparmiando costi e garantendo l'efficacia. Le regole di trasferimento sono mostrate nella tabella 1:
In secondo luogo, l'inizializzazione con crescita del modello (Model Growth): Meituan parte da un modello di mezza scala pre-addestrato su decine di miliardi di token, conserva il checkpoint dopo il training, poi espande il modello alla scala completa e continua l'addestramento.
Con questo metodo, il modello mostra una tipica curva di perdita: la perdita sale brevemente, poi converge rapidamente e alla fine supera di gran lunga la baseline con inizializzazione casuale. La figura 5b mostra un risultato rappresentativo dell'esperimento con 6B parametri attivati, evidenziando i vantaggi dell'inizializzazione con crescita del modello.
Terzo punto: un kit di stabilità multilivello. Meituan ha rafforzato la stabilità del training di LongCat-Flash su tre fronti: stabilità del router, stabilità dell'attivazione e stabilità dell'ottimizzatore.
Quarto punto: calcolo deterministico, che garantisce la completa riproducibilità dei risultati sperimentali e consente il rilevamento della Silent Data Corruption (SDC) durante il training.
Grazie a queste misure, il processo di training di LongCat-Flash rimane sempre altamente stabile, senza improvvisi aumenti irreversibili della perdita (loss spike).
Basandosi su una formazione stabile, Meituan ha anche progettato con cura la pipeline di training, dotando LongCat-Flash di avanzati comportamenti agent. Questo processo include pre-training su larga scala, training intermedio focalizzato su ragionamento e capacità di codice, e post-training incentrato su dialogo e uso di strumenti.
Fase iniziale: costruire un modello di base più adatto al post-training agent. Meituan ha progettato una strategia di fusione dati in due fasi per concentrare i dati dei domini ad alta intensità di ragionamento.
Fase intermedia: Meituan ha ulteriormente potenziato le capacità di ragionamento e di codice del modello; ha inoltre esteso la lunghezza del contesto a 128k per soddisfare le esigenze del post-training agent.
Infine, Meituan ha effettuato un post-training multi-stage. Dato che i dati di training di alta qualità e alta difficoltà nel campo agent sono scarsi, Meituan ha progettato un framework multi-agent sintetico: questo framework definisce la difficoltà dei compiti su tre dimensioni (elaborazione delle informazioni, complessità del set di strumenti e interazione con l'utente), utilizzando un controller dedicato per generare compiti complessi che richiedono ragionamento iterativo e interazione con l'ambiente.
Questa progettazione consente al modello di eccellere nell'esecuzione di compiti complessi che richiedono l'uso di strumenti e l'interazione con l'ambiente.
Veloce ed economico in esecuzione
Come ci riesce LongCat-Flash?
Come detto prima, LongCat-Flash può eseguire inferenze su una scheda H800 a oltre 100 token al secondo, con un costo di soli 0,7 dollari per ogni milione di token generati: insomma, è sia veloce che economico.
Come ci riesce? Innanzitutto, dispone di un' architettura di inferenza parallela progettata in sinergia con l'architettura del modello; in secondo luogo, sono state aggiunte ottimizzazioni come quantizzazione e kernel personalizzati.
Ottimizzazione dedicata: far "correre" il modello in modo fluido
Sappiamo che per costruire un sistema di inferenza efficiente bisogna risolvere due problemi chiave: la coordinazione tra calcolo e comunicazione, e la lettura/scrittura e memorizzazione della cache KV.
Per la prima sfida, i metodi esistenti sfruttano la parallelizzazione su tre livelli: overlapping a livello di operatori, di esperti e di layer. L'architettura ScMoE di LongCat-Flash introduce una quarta dimensione: overlapping a livello di modulo. Il team ha quindi progettato la strategia di scheduling SBO (Single Batch Overlap) per ottimizzare latenza e throughput.
SBO è una pipeline di esecuzione in quattro fasi che sfrutta appieno il potenziale di LongCat-Flash tramite overlapping a livello di modulo, come mostrato in figura 9. La differenza tra SBO e TBO è che SBO nasconde i costi di comunicazione all'interno di un singolo batch. Nella prima fase esegue il calcolo MLA, fornendo input per le fasi successive; nella seconda fase, Dense FFN e Attn 0 (proiezione QKV) sono sovrapposti alla comunicazione all-to-all dispatch; nella terza fase, MoE GEMM viene eseguito indipendentemente, beneficiando della strategia di deployment EP; nella quarta fase, Attn 1 (attenzione principale e proiezione output) e Dense FFN sono sovrapposti alla combinazione all-to-all. Questo design allevia efficacemente i costi di comunicazione, garantendo l'efficienza di LongCat-Flash.
Per la seconda sfida, ovvero la lettura/scrittura e memorizzazione della cache KV, LongCat-Flash la affronta con innovazioni architetturali nella meccanica di attenzione e nella struttura MTP, riducendo i costi I/O effettivi.
Prima di tutto, accelerazione della decodifica speculativa. LongCat-Flash utilizza MTP come modello draft, ottimizzando tre fattori chiave tramite l'analisi sistemica della formula di accelerazione della decodifica speculativa: lunghezza di accettazione prevista, rapporto di costo tra modello draft e modello target, e rapporto di costo tra verifica target e decodifica. Integrando una singola testa MTP e introducendola nelle fasi finali del pre-training, si ottiene un tasso di accettazione di circa il 90%. Per bilanciare qualità e velocità del draft, si adotta un'architettura MTP leggera per ridurre i parametri, mentre il metodo C2T filtra i token meno probabili tramite un modello di classificazione.
In secondo luogo, ottimizzazione della cache KV tramite la meccanica di attenzione a 64 teste di MLA. MLA mantiene un equilibrio tra prestazioni ed efficienza, riducendo notevolmente il carico computazionale e ottenendo un'eccellente compressione della cache KV, riducendo la pressione su storage e banda. Questo è fondamentale per coordinare la pipeline di LongCat-Flash, poiché il modello ha sempre calcoli di attenzione che non possono essere sovrapposti alla comunicazione.
Ottimizzazione a livello di sistema: far "collaborare" l'hardware
Per minimizzare i costi di scheduling, il team di ricerca di LongCat-Flash ha risolto il problema launch-bound causato dai costi di avvio del kernel nei sistemi di inferenza LLM. In particolare, dopo l'introduzione della decodifica speculativa, la pianificazione indipendente dei kernel di verifica e del forward draft comporta costi significativi. Attraverso la strategia di fusione TVD, hanno fuso il forward target, la verifica e il forward draft in un'unica CUDA graph. Per aumentare ulteriormente l'utilizzo della GPU, hanno implementato uno scheduler overlapped e introdotto uno scheduler overlapped multi-step, che avvia più kernel di forward in una singola iterazione di scheduling, nascondendo efficacemente i costi di scheduling e sincronizzazione CPU.
L'ottimizzazione dei kernel personalizzati affronta le sfide di efficienza uniche dell'inferenza autoregressiva LLM. La fase di pre-fill è intensiva in calcolo, mentre la fase di decodifica, a causa dei pattern di traffico, genera batch piccoli e irregolari spesso limitati dalla memoria. Per MoE GEMM, hanno adottato la tecnica SwapAB, trattando i pesi come matrice sinistra e le attivazioni come matrice destra, sfruttando la flessibilità a grana di 8 elementi nella dimensione n per massimizzare l'utilizzo dei tensor core. I kernel di comunicazione sfruttano la trasmissione hardware-accelerata NVLink Sharp e la riduzione in-switch per minimizzare il movimento dei dati e l'occupazione SM, superando costantemente NCCL e MSCCL++ con soli 4 thread block su messaggi da 4KB a 96MB.
Per la quantizzazione, LongCat-Flash adotta lo stesso schema di quantizzazione a blocchi granulari di DeepSeek-V3. Per ottenere il miglior compromesso tra prestazioni e accuratezza, implementa una quantizzazione a precisione mista a livello di layer basata su due schemi: il primo identifica che alcune layer lineari (in particolare Downproj) hanno attivazioni di input con ampiezza fino a 10^6; il secondo calcola errore di quantizzazione FP8 a livello di blocco per layer, riscontrando errori significativi in alcuni layer esperti. Incrociando i due schemi, si ottiene un notevole miglioramento dell'accuratezza.
Dati reali: quanto è veloce? Quanto costa?
I test mostrano che LongCat-Flash si comporta in modo eccellente in diverse configurazioni. Rispetto a DeepSeek-V3, con lunghezze di contesto simili, LongCat-Flash raggiunge una maggiore throughput di generazione e una velocità superiore.
Nelle applicazioni Agent, considerando le diverse esigenze tra contenuti di inferenza (visibili all'utente, devono corrispondere alla velocità di lettura umana di circa 20 token/s) e comandi d'azione (non visibili all'utente ma influenzano direttamente il tempo di avvio degli strumenti, richiedendo la massima velocità), la velocità di generazione di quasi 100 token/s di LongCat-Flash mantiene la latenza di chiamata dello strumento entro 1 secondo, migliorando notevolmente l'interattività delle applicazioni Agent. Supponendo un costo di 2 dollari all'ora per GPU H800, ciò significa un prezzo di 0,7 dollari per ogni milione di token generati.
L'analisi teorica delle prestazioni mostra che la latenza di LongCat-Flash dipende principalmente da tre componenti: MLA, all-to-all dispatch/combine e MoE. Con EP=128, batch per scheda=96, tasso di accettazione MTP ≈80%, il limite teorico di TPOT di LongCat-Flash è di 16ms, molto meglio dei 30ms di DeepSeek-V3 e dei 26,2ms di Qwen3-235B-A22B. Supponendo un costo di 2 dollari/ora per GPU H800, il costo di output di LongCat-Flash è di 0,09 dollari per milione di token, molto inferiore ai 0,17 dollari di DeepSeek-V3. Tuttavia, questi valori sono solo limiti teorici.
Abbiamo anche testato la pagina di prova gratuita di LongCat-Flash.
Abbiamo prima chiesto al modello di scrivere un articolo sull'autunno, di circa 1000 caratteri.
Appena abbiamo fatto la richiesta e avviato la registrazione dello schermo, LongCat-Flash aveva già scritto la risposta, tanto che non siamo riusciti a fermare la registrazione in tempo.
Osservando attentamente, si nota che la velocità di output del primo token di LongCat-Flash è particolarmente elevata. Con altri modelli di dialogo, spesso si deve aspettare il caricamento, mettendo a dura prova la pazienza dell'utente, come quando si aspetta di ricevere un messaggio su WeChat e il telefono mostra "in ricezione". LongCat-Flash cambia questa esperienza: praticamente non si percepisce alcuna latenza per il primo token.
Anche la velocità di generazione dei token successivi è molto alta, ben oltre la velocità di lettura dell'occhio umano.
Successivamente, abbiamo attivato la "ricerca online" per vedere se LongCat-Flash fosse abbastanza veloce anche in questa funzione. Gli abbiamo chiesto di consigliare buoni ristoranti vicino a Wangjing.
Dal test si percepisce chiaramente che LongCat-Flash non ci mette molto a "pensare" prima di rispondere, ma fornisce la risposta quasi immediatamente. Anche la ricerca online è "veloce". Inoltre, mentre fornisce rapidamente le risposte, cita anche le fonti, garantendo affidabilità e tracciabilità delle informazioni.
Chi può scaricare il modello può provarlo in locale per vedere se la velocità di LongCat-Flash è altrettanto sorprendente.
Quando i grandi modelli entrano nell'era della praticità
Negli ultimi anni, ogni volta che usciva un grande modello, tutti si chiedevano: quali sono i suoi dati benchmark? Quanti record ha battuto? È SOTA? Ora la situazione è cambiata. A parità di capacità, tutti si chiedono: quanto costa usare questo modello? Quanto è veloce? Questo è particolarmente evidente tra aziende e sviluppatori che usano modelli open source. Molti utenti scelgono i modelli open source proprio per ridurre la dipendenza e i costi delle API closed source, quindi sono più sensibili ai requisiti di calcolo, velocità di inferenza ed efficacia della compressione/quantizzazione.
Il modello open source LongCat-Flash di Meituan è proprio un esempio di questa tendenza. Si sono concentrati su come rendere i grandi modelli davvero accessibili e veloci, una chiave per la diffusione della tecnologia.
Questa scelta orientata alla praticità è coerente con l'immagine che abbiamo sempre avuto di Meituan. In passato, la maggior parte dei loro investimenti tecnologici era volta a risolvere problemi reali di business: ad esempio, l'EDPLVO, vincitore del Best Navigation Paper all'ICRA 2022, è stato sviluppato per affrontare le emergenze incontrate dai droni durante le consegne (come la perdita di segnale dovuta a edifici troppo ravvicinati); lo standard ISO globale per l'evitamento degli ostacoli dei droni, recentemente co-redatto, si basa sull'esperienza tecnica di casi come evitare fili di aquiloni o corde di sicurezza per la pulizia dei vetri durante il volo. Il modello LongCat-Flash open source è in realtà il motore dietro il loro strumento di programmazione AI "NoCode", che serve sia l'interno dell'azienda che è aperto gratuitamente all'esterno, con l'obiettivo di promuovere il vibe coding e ottenere riduzione dei costi e aumento dell'efficienza.
Questo passaggio dalla competizione sulle prestazioni all'orientamento pratico riflette in realtà la naturale evoluzione dell'industria AI. Quando le capacità dei modelli si avvicinano, efficienza ingegneristica e costi di deployment diventano fattori chiave di differenziazione. L'open source di LongCat-Flash è solo un esempio di questa tendenza, ma offre alla community un percorso tecnico di riferimento: come abbassare la soglia d'uso mantenendo la qualità del modello, tramite innovazione architetturale e ottimizzazione di sistema. Per quegli sviluppatori e aziende con budget limitati ma desiderosi di sfruttare le capacità AI avanzate, questo è senza dubbio di grande valore.
Esclusione di responsabilità: il contenuto di questo articolo riflette esclusivamente l’opinione dell’autore e non rappresenta in alcun modo la piattaforma. Questo articolo non deve essere utilizzato come riferimento per prendere decisioni di investimento.
Ti potrebbe interessare anche
Quanto bisogna guadagnare nel mondo delle criptovalute per poter dire di aver "cambiato il proprio destino"?
Il vero rischio non sta nella "perdita", ma nel "non sapere mai di aver già vinto".

NBER | Utilizzare modelli per rivelare come l'espansione dell'economia digitale stia rimodellando il panorama finanziario globale
I risultati della ricerca mostrano che, a lungo termine, l'effetto della domanda di riserve prevale sull'effetto di sostituzione, portando a una riduzione dei tassi d'interesse negli Stati Uniti e a un aumento del debito estero degli Stati Uniti.

ETH prende il centro della scena: la vera apertura della seconda metà del mercato toro
Combinando la struttura del mercato, i flussi di capitale, i dati on-chain e l'ambiente normativo, la nostra valutazione è molto chiara: Ethereum sta gradualmente sostituendo Bitcoin, diventando l'asset centrale nella seconda metà del mercato rialzista.
