Vitalik: Nowa koncepcja architektury glue i coprocessor, zwiększająca wydajność i bezpieczeństwo

Sklejacz powinien być zoptymalizowany, aby stać się dobrym sklejaczem, a koprocesor powinien być zoptymalizowany, aby stać się dobrym koprocesorem.
Klej powinien być zoptymalizowany, aby być dobrym klejem, a koprocesor powinien być zoptymalizowany, aby być dobrym koprocesorem.
Oryginalny tytuł: „Glue and coprocessor architectures”
Autor: Vitalik Buterin, założyciel Ethereum
Tłumaczenie: Deng Tong, Jinse Finance
Szczególne podziękowania dla Justina Drake'a, Georgiosa Konstantopoulosa, Andreja Karpathy'ego, Michaela Gao, Taruna Chitry oraz różnych współtwórców Flashbots za przekazane opinie i komentarze.
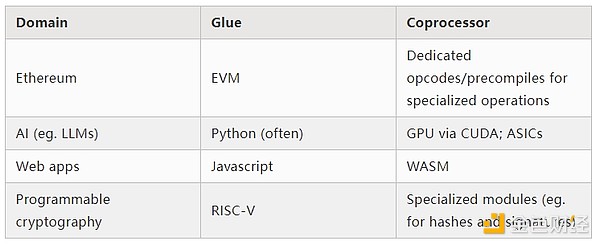
Jeśli przeanalizujesz z umiarkowanymi szczegółami dowolne intensywne obliczeniowo zadanie we współczesnym świecie, raz po raz zauważysz jedną cechę: obliczenia można podzielić na dwie części:
- Stosunkowo niewielka ilość złożonej, ale niezbyt intensywnej obliczeniowo „logiki biznesowej”;
- Duża ilość intensywnej, ale wysoce ustrukturyzowanej „drogiej pracy”.
Oba te typy obliczeń najlepiej obsługiwać w różny sposób: pierwszy z nich może mieć mniej wydajną architekturę, ale wymaga bardzo wysokiej uniwersalności; drugi może mieć niższą uniwersalność, ale wymaga bardzo wysokiej wydajności.
Jakie są przykłady tego podejścia w praktyce?
Najpierw przyjrzyjmy się środowisku, które znam najlepiej: Ethereum Virtual Machine (EVM). Oto ślad debugowania geth z mojej ostatniej transakcji na Ethereum: aktualizacja hasha IPFS mojego bloga na ENS. Ta transakcja zużyła łącznie 46924 gas, które można sklasyfikować w następujący sposób:
- Podstawowy koszt: 21,000
- Dane wywołania: 1,556
- Wykonanie EVM: 24,368
- Opcode SLOAD: 6,400
- Opcode SSTORE: 10,100
- Opcode LOG: 2,149
- Inne: 6,719

Ślad EVM aktualizacji hasha ENS. Przedostatnia kolumna to zużycie gas.
Morał tej historii jest taki: większość wykonania (patrząc tylko na EVM, około 73%, a jeśli uwzględnić podstawowy koszt obejmujący obliczenia, około 85%) koncentruje się na bardzo niewielkiej liczbie ustrukturyzowanych, kosztownych operacji: odczyty i zapisy do pamięci, logi i kryptografia (podstawowy koszt obejmuje 3000 za weryfikację podpisu, EVM obejmuje także 272 za hash). Pozostała część wykonania to „logika biznesowa”: zamiana bitów calldata, aby wyodrębnić ID rekordu, który próbuję ustawić, oraz hash, na który go ustawiam itd. W przypadku transferów tokenów obejmuje to dodawanie i odejmowanie sald, w bardziej zaawansowanych aplikacjach mogą to być pętle itd.
W EVM oba te typy wykonania są obsługiwane w różny sposób. Zaawansowana logika biznesowa jest pisana w bardziej zaawansowanych językach, zwykle Solidity, który kompiluje się do EVM. Kosztowna praca jest nadal wywoływana przez opcode EVM (takie jak SLOAD), ale ponad 99% rzeczywistych obliczeń jest wykonywanych w dedykowanych modułach napisanych bezpośrednio w kodzie klienta (a nawet w bibliotekach).
Aby lepiej zrozumieć ten wzorzec, przyjrzyjmy się innemu kontekstowi: kodowi AI napisanemu w Pythonie z użyciem torch.
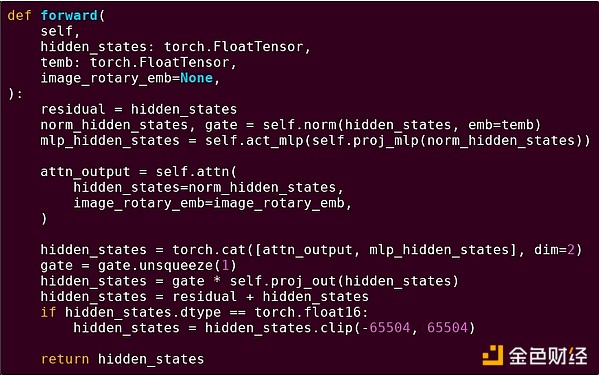
Przekazanie do przodu bloku modelu transformer
Co tu widzimy? Widzimy stosunkowo niewielką ilość „logiki biznesowej” napisanej w Pythonie, która opisuje strukturę wykonywanych operacji. W praktycznych zastosowaniach istnieje również inny rodzaj logiki biznesowej, która decyduje o szczegółach, takich jak sposób pobierania wejścia i operacje wykonywane na wyjściu. Jednak jeśli zagłębimy się w każdą pojedynczą operację (self.norm, torch.cat, +, *, poszczególne kroki wewnątrz self.attn...), zobaczymy obliczenia wektorowe: te same operacje wykonywane równolegle na dużej liczbie wartości. Podobnie jak w pierwszym przykładzie, niewielka część obliczeń dotyczy logiki biznesowej, a większość dotyczy wykonywania dużych, ustrukturyzowanych operacji na macierzach i wektorach — w rzeczywistości większość to po prostu mnożenie macierzy.
Podobnie jak w przykładzie EVM, oba te typy pracy są obsługiwane w różny sposób. Kod logiki biznesowej jest pisany w Pythonie, który jest bardzo uniwersalnym i elastycznym językiem, ale też bardzo wolnym — akceptujemy tę nieefektywność, ponieważ dotyczy tylko niewielkiej części całkowitych kosztów obliczeniowych. Jednocześnie operacje intensywne są pisane w wysoce zoptymalizowanym kodzie, często uruchamianym na GPU w kodzie CUDA. Coraz częściej widzimy nawet, że wnioskowanie LLM odbywa się na ASIC.
Nowoczesna programowalna kryptografia, taka jak SNARK, ponownie podąża za podobnym wzorcem na dwóch poziomach. Po pierwsze, dowodzący mogą pisać w językach wysokiego poziomu, gdzie ciężka praca wykonywana jest przez operacje wektorowe, podobnie jak w powyższym przykładzie AI. Mój kod okrągłego STARK pokazuje to. Po drugie, sam program wykonywany w kryptografii może być napisany w sposób, który dzieli się na ogólną logikę biznesową i wysoce ustrukturyzowaną kosztowną pracę.
Aby zrozumieć, jak to działa, możemy spojrzeć na jeden z najnowszych trendów w dowodach STARK. Dla uniwersalności i łatwości użycia zespoły coraz częściej budują dowodzące STARK dla szeroko stosowanych minimalnych maszyn wirtualnych, takich jak RISC-V. Każdy program, który wymaga dowodu wykonania, można skompilować do RISC-V, a następnie dowodzący może udowodnić wykonanie tego kodu w RISC-V.
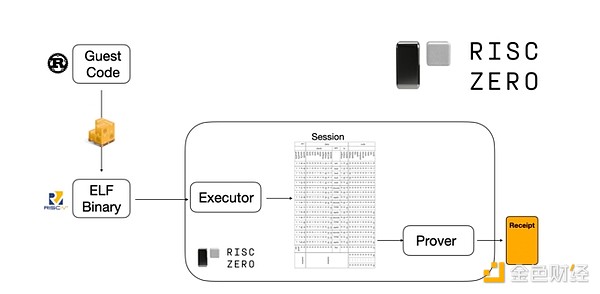
Wykres z dokumentacji RiscZero
To bardzo wygodne: oznacza, że musimy napisać logikę dowodzenia tylko raz, a od tego momentu każdy program wymagający dowodu może być napisany w dowolnym „tradycyjnym” języku programowania (np. RiskZero obsługuje Rust). Jednak istnieje problem: to podejście generuje duże narzuty. Programowalna kryptografia już jest bardzo kosztowna; dodanie narzutu uruchamiania kodu w interpreterze RISC-V jest zbyt duże. Dlatego deweloperzy wymyślili trik: identyfikują konkretne kosztowne operacje, które stanowią większość obliczeń (zwykle hashe i podpisy), a następnie tworzą dedykowane moduły do bardzo wydajnego dowodzenia tych operacji. Następnie wystarczy połączyć nieefektywny, ale uniwersalny system dowodzenia RISC-V z wydajnym, ale specjalistycznym systemem dowodzenia, aby uzyskać to, co najlepsze z obu światów.
Poza ZK-SNARK, programowalna kryptografia, taka jak obliczenia wielostronne (MPC) i w pełni homomorficzne szyfrowanie (FHE), może być optymalizowana w podobny sposób.
Jak wygląda to zjawisko ogólnie?
Współczesne obliczenia coraz częściej podążają za tym, co nazywam architekturą kleju i koprocesora: masz centralny komponent „kleju”, który jest bardzo uniwersalny, ale nieefektywny, odpowiedzialny za przesyłanie danych między jednym lub kilkoma komponentami koprocesora, które są mniej uniwersalne, ale bardzo wydajne.
To uproszczenie: w praktyce krzywa kompromisu między wydajnością a uniwersalnością prawie zawsze ma więcej niż dwa poziomy. GPU i inne chipy, które w branży nazywane są „koprocesorami”, są mniej uniwersalne niż CPU, ale bardziej uniwersalne niż ASIC. Kompromisy w zakresie specjalizacji są złożone i zależą od przewidywań i intuicji dotyczących tego, które części algorytmu pozostaną niezmienne za pięć lat, a które zmienią się za sześć miesięcy. W architekturach dowodów ZK często widzimy podobną wielopoziomową specjalizację. Jednak dla szerokiego modelu myślenia wystarczą dwa poziomy. W wielu dziedzinach obliczeniowych występuje podobna sytuacja:
Jak widać z powyższych przykładów, obliczenia można oczywiście dzielić w ten sposób — wydaje się to być prawem natury. W rzeczywistości można znaleźć przykłady specjalizacji obliczeniowej sprzed dziesięcioleci. Jednak uważam, że ten podział się nasila. I są ku temu powody:
Dopiero niedawno osiągnęliśmy granice wzrostu częstotliwości zegara CPU, więc dalsze korzyści można uzyskać tylko przez równoległość. Jednak równoległość jest trudna do rozumowania, więc dla deweloperów bardziej praktyczne jest kontynuowanie rozumowania sekwencyjnego i pozwolenie, aby równoległość odbywała się w tle, opakowana w dedykowane moduły zbudowane dla określonych operacji.
Szybkość obliczeń dopiero niedawno stała się tak wysoka, że koszt obliczeniowy logiki biznesowej stał się naprawdę pomijalny. W tym świecie optymalizacja VM do uruchamiania logiki biznesowej pod kątem celów innych niż wydajność obliczeniowa również ma sens: przyjazność dla deweloperów, znajomość, bezpieczeństwo i inne podobne cele. Jednocześnie dedykowane moduły „koprocesora” mogą być nadal projektowane pod kątem wydajności i czerpać bezpieczeństwo oraz przyjazność dla deweloperów z ich stosunkowo prostego „interfejsu” z klejem.
Coraz wyraźniej widać, które operacje są najważniejsze i najdroższe. Najbardziej oczywiste jest to w kryptografii, gdzie najczęściej używane są określone typy kosztownych operacji: operacje modulo, kombinacje liniowe krzywych eliptycznych (znane również jako mnożenie wieloskalowe), szybka transformata Fouriera itd. W AI również staje się to coraz bardziej oczywiste — przez ponad dwadzieścia lat większość obliczeń to „głównie mnożenie macierzy” (choć na różnych poziomach precyzji). Podobne trendy pojawiają się w innych dziedzinach. W porównaniu z 20 latami temu jest znacznie mniej nieznanych niewiadomych w (intensywnych obliczeniowo) obliczeniach.
Co to oznacza?
Kluczowym punktem jest to, że klej (Glue) powinien być zoptymalizowany, aby być dobrym klejem, a koprocesor (coprocessor) powinien być zoptymalizowany, aby być dobrym koprocesorem. Możemy zbadać, co to oznacza w kilku kluczowych obszarach.
EVM
Wirtualne maszyny blockchain (takie jak EVM) nie muszą być wydajne, wystarczy, że są znajome. Wystarczy dodać odpowiedni koprocesor (znany również jako „prekompilacja”), a obliczenia w nieefektywnej VM mogą być w rzeczywistości równie wydajne jak w natywnej, wydajnej VM. Na przykład narzut wynikający z 256-bitowych rejestrów EVM jest stosunkowo niewielki, podczas gdy korzyści płynące ze znajomości EVM i istniejącego ekosystemu deweloperów są ogromne i trwałe. Zespoły optymalizujące EVM odkryły nawet, że brak równoległości zwykle nie jest główną przeszkodą w skalowalności.
Najlepszym sposobem na ulepszenie EVM może być po prostu (i) dodanie lepszych prekompilacji lub dedykowanych opcode, na przykład jakaś kombinacja EVM-MAX i SIMD może być rozsądna, oraz (ii) ulepszenie układu pamięci, na przykład zmiany w Verkle tree, które jako efekt uboczny znacznie obniżają koszt dostępu do sąsiadujących slotów pamięci.
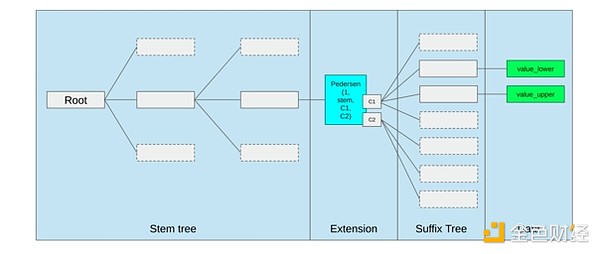
Optymalizacja pamięci w propozycji Ethereum Verkle tree, która umieszcza sąsiadujące klucze pamięci razem i dostosowuje koszt gas, aby to odzwierciedlić. Takie optymalizacje, wraz z lepszymi prekompilacjami, mogą być ważniejsze niż dostosowywanie samego EVM.
Bezpieczne obliczenia i otwarty sprzęt
Jednym z głównych wyzwań w zwiększaniu bezpieczeństwa współczesnych obliczeń na poziomie sprzętowym jest ich zbyt złożony i zastrzeżony charakter: chipy są projektowane pod kątem wydajności, co wymaga zastrzeżonych optymalizacji. Łatwo ukryć tylne drzwi, a luki boczne są ciągle odkrywane.
Ludzie nadal pracują nad bardziej otwartymi i bezpiecznymi alternatywami z różnych perspektyw. Niektóre obliczenia coraz częściej odbywają się w zaufanych środowiskach wykonawczych, w tym na telefonach użytkowników, co już zwiększyło bezpieczeństwo użytkowników. Działania na rzecz bardziej otwartego sprzętu konsumenckiego trwają, a ostatnio odnotowano pewne sukcesy, takie jak laptopy RISC-V z Ubuntu.
Laptop RISC-V z Debianem
Jednak wydajność nadal stanowi problem. Autor powyższego artykułu napisał:
Nowe, otwarte projekty chipów, takie jak RISC-V, nie mogą konkurować z technologią procesorów, która istnieje i była udoskonalana przez dziesięciolecia. Postęp zawsze ma swój początek.
Bardziej paranoiczne pomysły, takie jak ten projekt komputera RISC-V na FPGA, wiążą się z jeszcze większym narzutem. Ale co, jeśli architektura kleju i koprocesora oznacza, że ten narzut tak naprawdę nie ma znaczenia? Co, jeśli zaakceptujemy, że otwarte i bezpieczne chipy będą wolniejsze niż zastrzeżone, a jeśli to konieczne, nawet zrezygnujemy z typowych optymalizacji, takich jak spekulatywne wykonanie i przewidywanie rozgałęzień, ale spróbujemy to zrekompensować, dodając (jeśli trzeba, zastrzeżone) moduły ASIC do najbardziej intensywnych, specyficznych typów obliczeń? Wrażliwe obliczenia mogą być wykonywane na „głównym chipie”, zoptymalizowanym pod kątem bezpieczeństwa, otwartego projektu i odporności na kanały boczne. Bardziej intensywne obliczenia (np. ZK proofy, AI) będą wykonywane w modułach ASIC, które będą znać mniej informacji o wykonywanych obliczeniach (być może, przez kryptograficzne zaciemnianie, w niektórych przypadkach nawet zero informacji).
Kryptografia
Kolejnym kluczowym punktem jest to, że wszystko to jest bardzo optymistyczne dla kryptografii, zwłaszcza programowalnej kryptografii stającej się głównym nurtem. Już widzieliśmy wysoce zoptymalizowane implementacje niektórych konkretnych, wysoce ustrukturyzowanych obliczeń w SNARK, MPC i innych ustawieniach: narzut dla niektórych funkcji hashujących jest tylko kilkaset razy większy niż bezpośrednie wykonanie obliczeń, a narzut dla AI (głównie mnożenie macierzy) jest bardzo niski. Dalsze ulepszenia, takie jak GKR, mogą jeszcze bardziej obniżyć ten poziom. Całkowicie uniwersalne wykonanie VM, szczególnie w interpreterze RISC-V, może nadal generować narzut rzędu dziesięciu tysięcy razy, ale z powodów opisanych w tym artykule nie ma to znaczenia: o ile najbardziej intensywne części obliczeń są obsługiwane osobno przez wydajne, dedykowane technologie, całkowity narzut jest pod kontrolą.
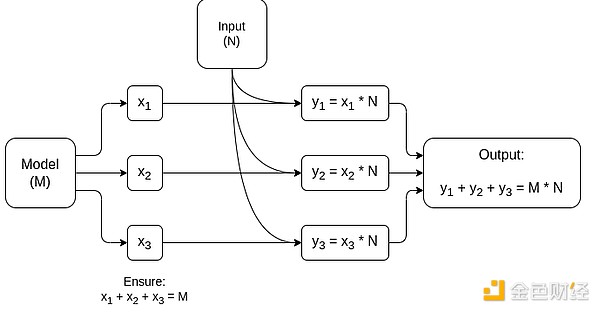
Uproszczony schemat MPC dedykowanego do mnożenia macierzy, największego komponentu wnioskowania modeli AI. Zobacz ten artykuł, aby uzyskać więcej szczegółów, w tym jak zachować prywatność modelu i wejścia.
Jednym wyjątkiem od idei „warstwa kleju musi być tylko znajoma, nie musi być wydajna” jest opóźnienie oraz, w mniejszym stopniu, przepustowość danych. Jeśli obliczenia obejmują dziesiątki powtarzających się kosztownych operacji na tych samych danych (jak w kryptografii i AI), każde opóźnienie spowodowane przez nieefektywną warstwę kleju może stać się głównym wąskim gardłem czasu działania. Dlatego warstwa kleju ma również wymagania dotyczące wydajności, choć są one bardziej specyficzne.
Wnioski
Ogólnie rzecz biorąc, uważam, że powyższe trendy są bardzo pozytywnym rozwojem z wielu perspektyw. Po pierwsze, jest to rozsądny sposób na maksymalizację wydajności obliczeniowej przy zachowaniu przyjazności dla deweloperów, pozwalający uzyskać więcej obu tych korzyści dla wszystkich. W szczególności, poprzez specjalizację po stronie klienta w celu zwiększenia wydajności, zwiększa się nasza zdolność do uruchamiania wrażliwych i wymagających wydajności obliczeń (takich jak ZK proofy, wnioskowanie LLM) lokalnie na sprzęcie użytkownika. Po drugie, tworzy to ogromne okno możliwości, aby dążenie do wydajności nie odbywało się kosztem innych wartości, najbardziej oczywistych: bezpieczeństwa, otwartości i prostoty: bezpieczeństwo i otwartość na kanały boczne w sprzęcie komputerowym, zmniejszenie złożoności obwodów w ZK-SNARK oraz zmniejszenie złożoności wirtualnych maszyn. Historycznie dążenie do wydajności spychało te inne czynniki na dalszy plan. Dzięki architekturze kleju i koprocesora nie jest to już konieczne. Część maszyny jest zoptymalizowana pod kątem wydajności, inna pod kątem uniwersalności i innych wartości, a obie współpracują ze sobą.
Ten trend jest również bardzo korzystny dla kryptografii, ponieważ sama kryptografia jest głównym przykładem „drogich, ustrukturyzowanych obliczeń”, a ten trend przyspiesza jej rozwój. To daje kolejną szansę na zwiększenie bezpieczeństwa. W świecie blockchain również możliwe jest zwiększenie bezpieczeństwa: możemy mniej martwić się o optymalizację wirtualnej maszyny, a bardziej skupić się na optymalizacji prekompilacji i innych funkcji współistniejących z VM.
Po trzecie, ten trend daje szansę mniejszym, nowszym uczestnikom. Jeśli obliczenia staną się mniej monolityczne, a bardziej modułowe, znacznie obniży to barierę wejścia. Nawet ASIC do jednego typu obliczeń mogą mieć znaczenie. To samo dotyczy dziedziny dowodów ZK i optymalizacji EVM. Pisanie kodu o niemal czołowej wydajności staje się łatwiejsze i bardziej dostępne. Audyt i formalna weryfikacja takiego kodu stają się łatwiejsze i bardziej dostępne. Wreszcie, ponieważ te bardzo różne dziedziny obliczeniowe konwergują do kilku wspólnych wzorców, istnieje więcej przestrzeni do współpracy i uczenia się między nimi.
Zastrzeżenie: Treść tego artykułu odzwierciedla wyłącznie opinię autora i nie reprezentuje platformy w żadnym charakterze. Niniejszy artykuł nie ma służyć jako punkt odniesienia przy podejmowaniu decyzji inwestycyjnych.
Może Ci się również spodobać
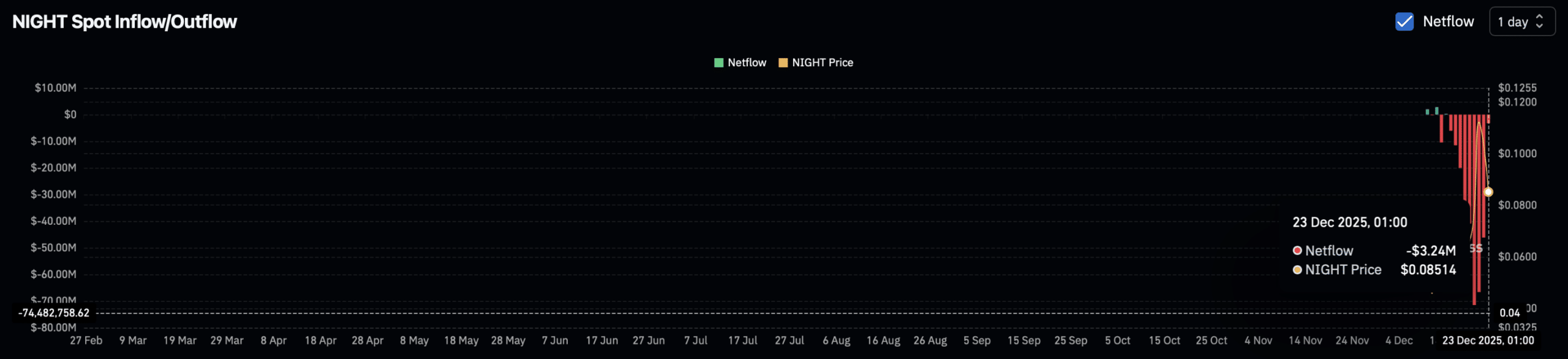
NIGHT z dziennym wolumenem obrotu bliskim 10 miliardów dolarów pochodzi z „przestarzałego” Cardano?
BlackRock: Inwestowanie w bitcoin wchodzi w nowy etap „optymalizacji”

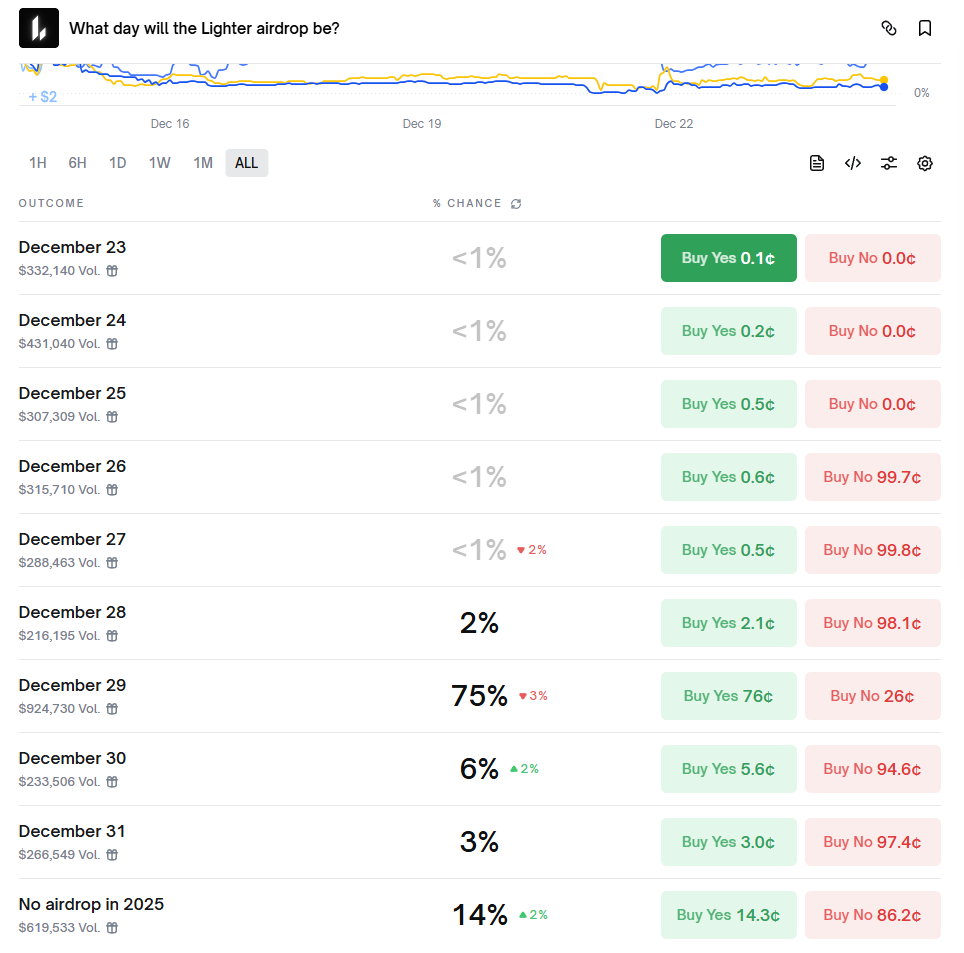
Lighter wkrótce przeprowadzi TGE: pełny przegląd okna czasowego, sygnałów on-chain i wyceny rynkowej
Midnight – Czy cofnięcie NIGHT to tylko przerwa wśród 12% spadku OI?