

Autor: Miao Zheng
O Google fingiu estar adormecido por 8 meses e, de repente, lançou o explosivo Gemini 3 Pro.
O Google finalmente lançou o Gemini 3 Pro, de forma muito repentina e bastante “discreta”.
Embora o Google tenha lançado o modelo de edição de imagens Nano Banana antes do Gemini 3 Pro, recuperando assim alguma visibilidade, no que diz respeito aos modelos base, o Google já estava em silêncio há demasiado tempo.
Durante mais de meio ano, todos discutiam as novas iniciativas da OpenAI ou elogiavam o domínio do Claude na área de código, mas ninguém mencionava o Gemini, que não recebia uma atualização de versão há 8 meses.
Mesmo que o negócio de cloud do Google e os seus relatórios financeiros sejam impressionantes, no núcleo da comunidade de desenvolvedores de IA, a presença do Google estava a ser gradualmente diluída.
Felizmente, após uma experiência imediata, percebi que o Gemini 3 Pro não nos decepcionou.
No entanto, ainda é cedo para tirar conclusões. Porque o setor de IA já ultrapassou a fase em que o número de parâmetros era o mais impressionante; agora, todos competem em aplicações, implementação e custos.
Se o Google conseguirá adaptar-se à nova versão e ao novo ambiente, ainda é uma incógnita.
01
Pedi ao Gemini 3 Pro para se descrever numa frase, e foi assim que respondeu.
“Já não tenho pressa em provar ao mundo o quão inteligente sou, mas começo a pensar em como me tornar mais útil.” — Gemini 3 Pro
No ranking LMArena, o Gemini 3 Pro atingiu o topo com uma pontuação Elo de 1501, estabelecendo um novo recorde na avaliação de capacidades gerais de modelos de IA. É um resultado bastante impressionante, até Altman felicitou publicamente no Twitter.

No teste de capacidades matemáticas, o modelo atingiu 100% de precisão no modo de execução de código do AIME2025 (American Invitational Mathematics Examination). No teste de conhecimento científico GPQADiamond, o Gemini 3 Pro obteve uma precisão de 91,9%.
Os resultados do concurso MathArenaApex mostram que o Gemini 3 Pro obteve uma pontuação de 23,4%, enquanto outros modelos principais ficaram geralmente abaixo de 2%. Além disso, no teste chamado Humanity'sLastExam, o modelo atingiu uma pontuação de 37,5% sem utilizar ferramentas.
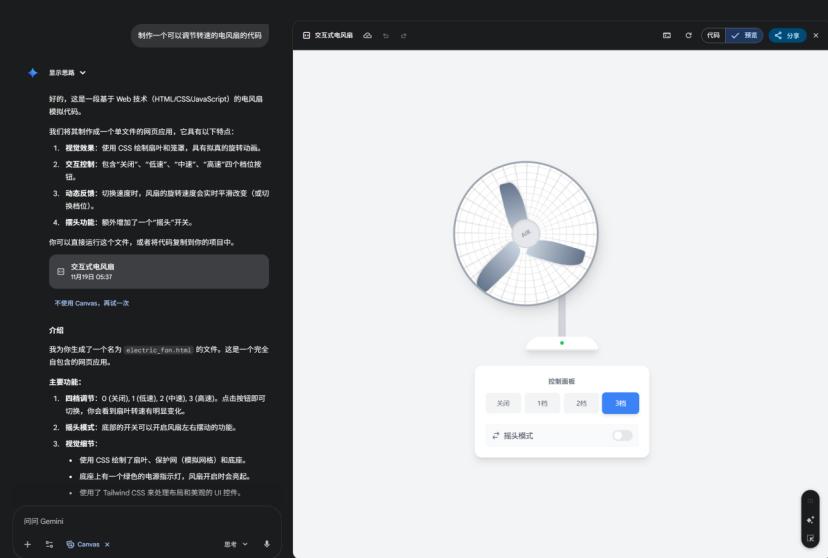
O Google introduziu nesta atualização uma funcionalidade de geração de código chamada “vibecoding”. Esta funcionalidade permite ao utilizador descrever as suas necessidades em linguagem natural, e o sistema gera o código e a aplicação correspondentes.
No teste do ambiente de programação Canvas, após o utilizador descrever “criar uma ventoinha elétrica com velocidade ajustável”, o sistema gerou, em cerca de 30 segundos, um código completo com animação de rotação, barra de controlo de velocidade e botão de ligar/desligar.
Os casos apresentados oficialmente também incluem uma simulação visual do processo de fusão nuclear.
No que diz respeito à interação, o Gemini 3 Pro acrescentou a funcionalidade “GenerativeUI”. Ao contrário dos assistentes de IA tradicionais, que apenas devolvem respostas em texto, este sistema pode gerar automaticamente layouts de interface personalizados de acordo com o conteúdo da consulta.
Por exemplo, quando o utilizador faz perguntas sobre computação quântica, o sistema pode gerar uma interface interativa com explicações de conceitos, gráficos dinâmicos e links para artigos relevantes.
Para a mesma questão dirigida a diferentes públicos, o sistema gera diferentes designs de interface. Por exemplo, ao explicar o mesmo conceito a crianças e adultos, utiliza diferentes formas de apresentação: para crianças, mais fofas; para adultos, mais simples e diretas.
A funcionalidade experimental Visual Layout, disponível no Google Labs, demonstra esta aplicação de interface, permitindo ao utilizador obter layouts de visualização ao estilo de revista, com imagens, módulos e elementos de UI ajustáveis.
O lançamento também inclui o sistema de agentes inteligentes chamado Gemini Agent, atualmente em fase experimental. Este sistema pode executar tarefas em múltiplos passos e conectar-se a serviços do Google como Gmail, Google Calendar e Reminders.
No cenário de gestão de caixa de entrada, o sistema pode filtrar e-mails automaticamente, marcar prioridades e redigir respostas. O planeamento de viagens é outro cenário de aplicação: o utilizador só precisa de fornecer o destino e o período aproximado, e o sistema consulta o calendário, pesquisa opções de voos e hotéis e adiciona o itinerário. Esta funcionalidade está atualmente disponível apenas para subscritores do Google AI Ultra nos EUA.
No processamento multimodal, o Gemini 3 Pro é construído com uma arquitetura de especialistas mistos esparsos, suportando entrada de texto, imagem, áudio e vídeo. A janela de contexto do modelo é de 1 milhão de tokens, o que significa que pode processar documentos ou conteúdos de vídeo mais longos.
O professor de História da Universidade Laurier do Canadá, Mark Humphries, testou o modelo e verificou que a taxa de erro de caracteres na identificação de manuscritos do século XVIII foi de 0,56%, uma redução de 50% a 70% em relação à versão anterior.
O Google afirma que os dados de treino incluem documentos públicos da web, código, imagens, áudio e vídeo, e que a fase final de treino utilizou técnicas de aprendizagem por reforço.
O Google também lançou uma versão otimizada chamada Gemini 3 Deep Think, especialmente para tarefas de raciocínio complexo. Este modo está atualmente em avaliação de segurança e deverá ser disponibilizado nas próximas semanas para subscritores do Google AI Ultra.
No modo de IA do Google Search, os utilizadores podem clicar no separador “thinking” para ver o processo de raciocínio deste modo. Em comparação com o modo padrão, o Deep Think realiza mais etapas de análise antes de gerar uma resposta.
Além dos materiais oficiais, comparei também o Gemini 3 Pro com o ChatGPT-5.1.
A primeira comparação foi a geração de imagens.
Prompt: Gera-me um iPhone17
ChatGPT-5.1

Gemini 3 Pro

Subjetivamente, o ChatGPT-5.1 correspondeu melhor às minhas necessidades, por isso venceu esta ronda.
A segunda comparação foi o nível de inteligência dos agentes.
Prompt: Vai pesquisar sobre a conta do WeChat “ZimuBang” e comenta sobre o seu nível
GPT-5.1

Gemini 3 Pro

Embora, subjetivamente, eu prefira a interpretação do Gemini 3 Pro, ela é demasiado elogiosa; o ChatGPT-5.1 consegue identificar algumas deficiências, sendo mais objetivo e realista.
Por fim, a capacidade de código, que é atualmente o foco de todos os grandes modelos.
O projeto que escolhi foi o LightRAG, um dos projetos mais populares recentemente no GitHub. Ele integra estruturas de grafos para melhorar a perceção de contexto e a recuperação eficiente de informação, otimizando a geração aumentada por recuperação para maior precisão e resposta mais rápida. Link do projeto
Prompt: Fala-me sobre este projeto
GPT-5.1

Gemini 3 Pro

Ao mesmo tempo, o Gemini 3 Pro também recebeu grandes elogios de profissionais do setor.


02
Embora o lançamento do Gemini 3 Pro tenha sido muito discreto, na verdade o Google já vinha a preparar o terreno há bastante tempo.
Na conferência de resultados do terceiro trimestre, o CEO do Google, Sundar Pichai, disse: “O Gemini 3 Pro será lançado em 2025.” Sem data concreta, sem mais detalhes, mas deu início a um grande espetáculo de marketing no setor tecnológico.
O Google continuou a enviar sinais para manter a comunidade de IA em alerta máximo, mas recusou-se sempre a fornecer um calendário de lançamento definitivo.
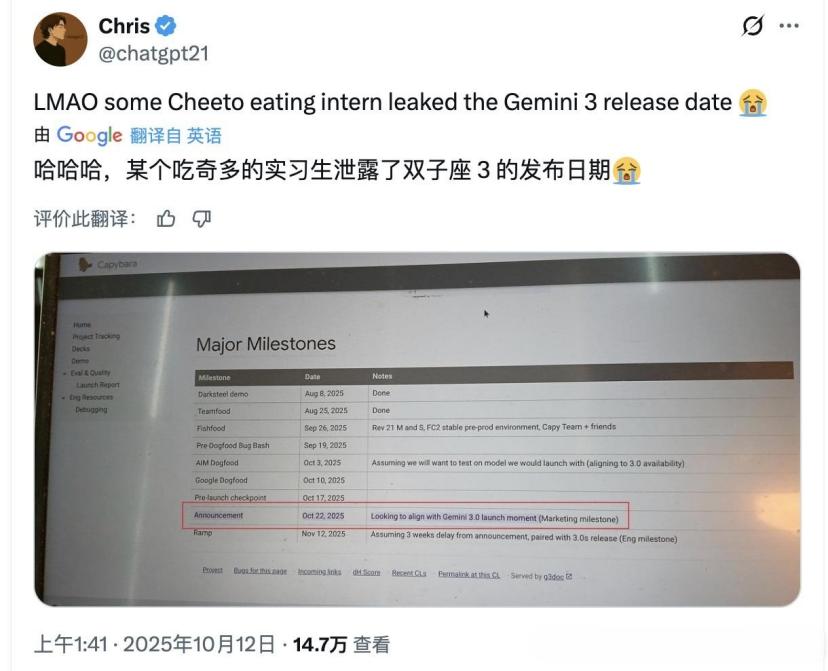
Desde outubro, começaram a surgir vários “vazamentos acidentais”. A partir de 23 de outubro, circulou um calendário interno com uma captura de ecrã do evento “Gemini 3 Pro Release” marcado para 12 de novembro.
Além disso, desenvolvedores atentos encontraram a menção “gemini-3-pro-preview-11-2025” na documentação da API do Vertex AI.
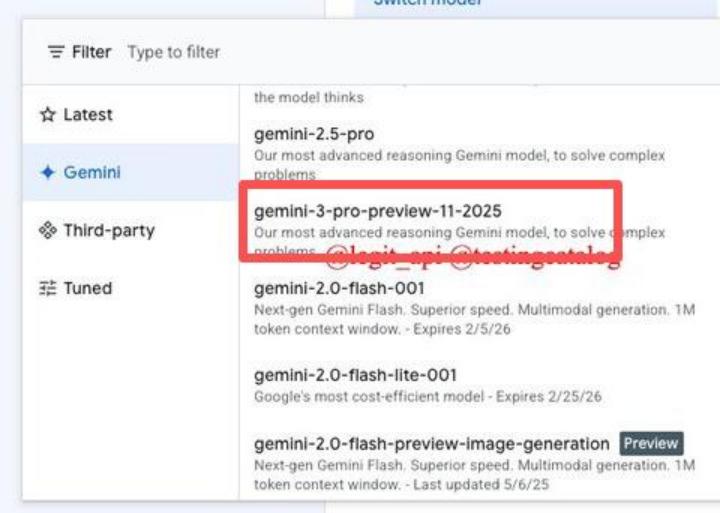
Logo depois, começaram a aparecer várias capturas de ecrã no Reddit e no X. Alguns utilizadores afirmaram ter visto o novo modelo na ferramenta Gemini Canvas, outros encontraram identificadores de modelo anormais em certas versões da aplicação móvel.
Depois, os dados de teste abaixo começaram a circular nas redes sociais.
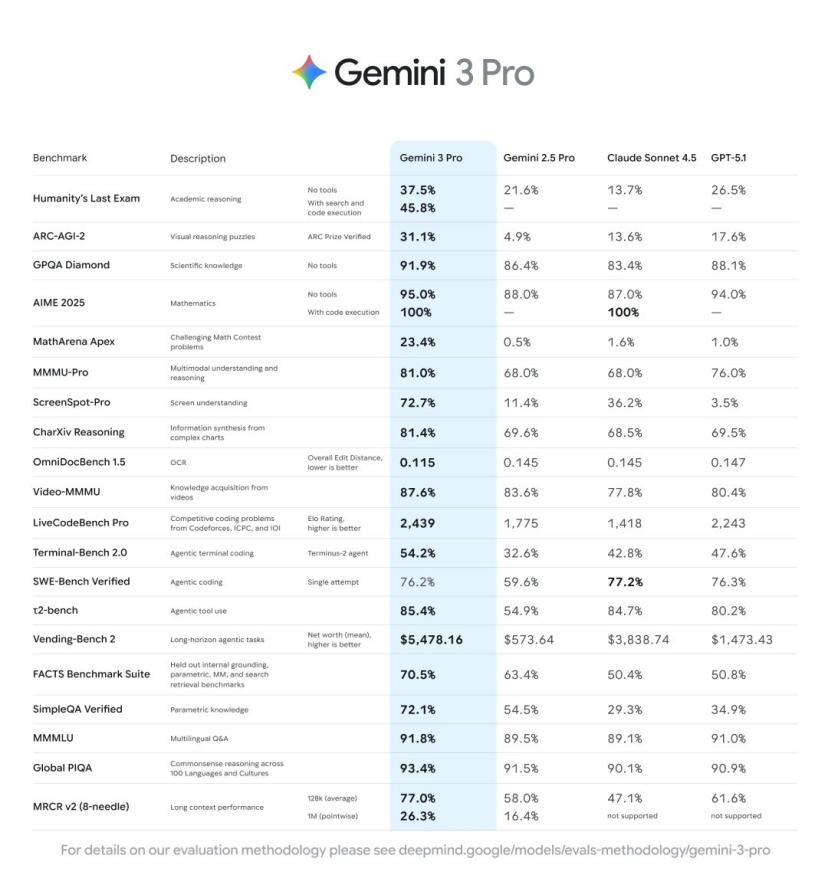
Estes “vazamentos” parecem acidentais, mas na verdade fazem parte de uma preparação cuidadosamente orquestrada.
Cada vazamento mostrou, no momento certo, uma capacidade central do Gemini 3 Pro, e cada discussão elevou as expectativas a um novo patamar. A atitude da conta oficial do Google era intrigante: partilhavam discussões da comunidade, usavam expressões como “em breve” para criar suspense, e até altos cargos do laboratório de IA do Google responderam a previsões de data de lançamento com dois emojis de “pensar”, mas nunca revelaram uma data precisa.
Após quase um mês de preparação, o Google finalmente apresentou o novo Gemini 3 Pro. No entanto, apesar do desempenho robusto do Gemini 3 Pro, a frequência de atualizações do Google deixa um pouco a desejar.
Já em março deste ano, o Google lançou a versão de pré-visualização do Gemini 2.5 Pro, e depois lançou sucessivamente versões derivadas como o Gemini 2.5 Flash Preview. Até ao lançamento do Gemini 3 Pro, a série Gemini não teve qualquer atualização de versão.
Mas os concorrentes do Google não esperaram pelo Gemini.
A OpenAI lançou o GPT-5 a 7 de agosto e, a 12 de novembro, atualizou para o GPT-5.1. Durante este período, a OpenAI também lançou o seu próprio navegador de IA, Atlas, mirando diretamente o território do Google.
A Anthropic tem um ritmo de iteração ainda mais intenso: a 24 de fevereiro lançou o Claude 3.7 Sonnet (o primeiro modelo de raciocínio híbrido), a 22 de maio lançou o Claude Opus 4 e Sonnet 4, a 5 de agosto lançou o Claude Opus 4.1, a 29 de setembro lançou o Claude Sonnet 4.5, e a 15 de outubro lançou o Claude Haiku 4.5.
Esta série de ofensivas apanhou o Google um pouco desprevenido, mas, até agora, o Google conseguiu resistir.

03
A principal razão pela qual o Google demorou 8 meses a atualizar o Gemini 3 Pro pode ter sido as mudanças na equipa.
Entre julho e agosto de 2025, a Microsoft lançou uma forte ofensiva de recrutamento ao Google, conseguindo contratar mais de 20 especialistas e executivos principais da DeepMind.
Entre eles estavam Dave Citron, Senior Director of Product da DeepMind, responsável pela implementação dos principais produtos de IA, e Amar Subramanya, VP of Engineering do Gemini, um dos principais responsáveis de engenharia do modelo Gemini do Google.
Por outro lado, a equipa do Nano Banana do Google afirmou que, após o lançamento do Gemini 2.5 Pro, o Google passou muito tempo focado na área de geração de imagens por IA, o que atrasou a atualização dos modelos base.
O Google acredita que só depois de superar três grandes desafios na área de geração de imagens — consistência de personagem (Character Consistency), edição em contexto (In-context Editing) e renderização de texto (Text Rendering) — é que o desempenho dos modelos base pode ser realmente melhorado.
A equipa do Nano Banana afirmou que o modelo não só deve “desenhar bem”, mas, mais importante ainda, deve “compreender a linguagem humana” e ser “controlável”, para que a geração de imagens por IA possa realmente ser implementada comercialmente.
Olhando agora para o Gemini 3 Pro, é uma resposta satisfatória, mas, neste campo de batalha de IA onde cada segundo conta, ser suficiente já não chega.
Já que o Google escolheu entregar o exame neste momento, tem de estar preparado para enfrentar os avaliadores mais exigentes — os utilizadores e desenvolvedores que já foram “mimados” pelos concorrentes. Nos próximos meses, a competição não será sobre parâmetros de modelos, mas sim uma luta corpo a corpo pela capacidade de integração do ecossistema. O Google, este elefante, não só tem de aprender a dançar, como tem de dançar mais rápido do que todos os outros.



