
Взлет в трендах! Большая модель Meituan стала популярной благодаря своей "скорости"

Разработчики из Китая и других стран: протестировали, новая open-source модель от Meituan работает невероятно быстро!
Когда AI действительно становится таким же повсеместным, как вода и электричество, сила модели перестает быть единственным вопросом, который волнует всех.
С начала года — от Claude 3.7 Sonnet, Gemini 2.5 Flash до недавних GPT-5 и DeepSeek V3.1 — ведущие разработчики моделей думают о том, как, сохраняя точность, сделать так, чтобы AI решал каждую задачу с минимальными вычислительными затратами и давал ответ в кратчайшие сроки. Другими словами, как не тратить лишние токены и не терять время.
Для компаний и разработчиков, строящих приложения на базе моделей, такой переход от «создания самой мощной модели» к созданию более практичных и быстрых моделей — отличная новость. Еще более приятно, что становится все больше связанных с этим open-source моделей.
На днях мы обнаружили на HuggingFace новую модель — LongCat-Flash-Chat.

Эта модель принадлежит серии LongCat-Flash от Meituan, доступна для использования на официальном сайте.
Она изначально понимает, что «не все токены равны», и потому динамически распределяет вычислительный бюджет для важных токенов в зависимости от их значимости. Благодаря этому, активируя лишь небольшое количество параметров, она по производительности сопоставима с ведущими open-source моделями.

После открытия исходного кода LongCat-Flash попала в топ поисковых запросов.
Кроме того, скорость этой модели произвела сильное впечатление — на видеокарте H800 скорость инференса превышает 100 токенов в секунду. Разработчики из разных стран подтвердили это в тестах — кто-то получил скорость 95 токенов/с, кто-то за минимальное время получил ответ, сопоставимый с Claude.
Источник изображения: пользователь Zhihu @小小将.
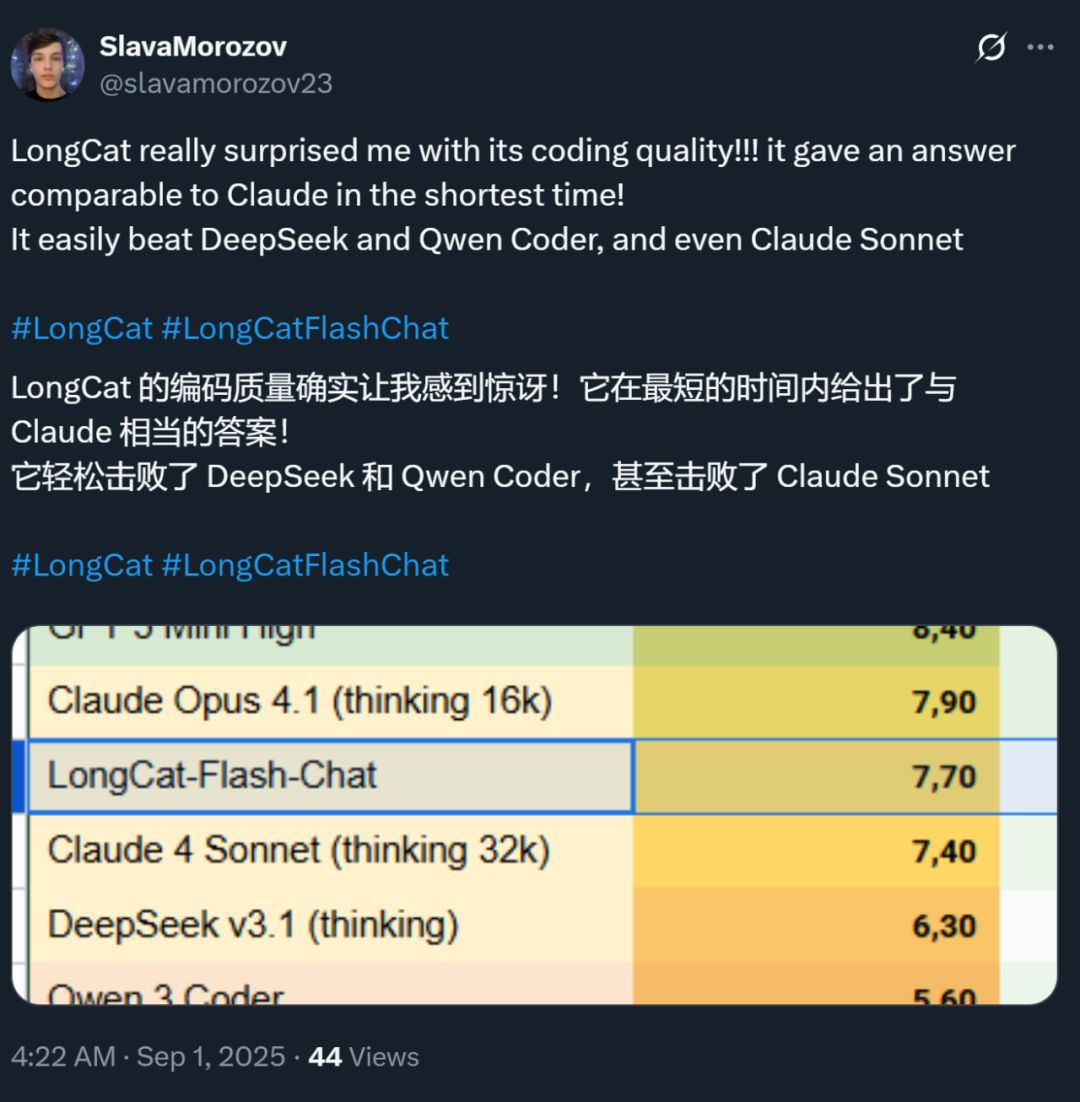
Источник изображения: пользователь X @SlavaMorozov.
Вместе с открытием исходного кода Meituan также опубликовала технический отчет по LongCat-Flash, где можно найти множество технических деталей.

Технический отчет: LongCat-Flash Technical Report
В этой статье мы подробно расскажем об этом.
Как большие модели экономят вычисления?
Посмотрим на архитектурные инновации и методы обучения LongCat-Flash
LongCat-Flash — это гибридная экспертная модель с общим числом параметров 560 миллиардов, которая может активировать от 18.6 до 31.3 миллиардов (в среднем 27 миллиардов) параметров в зависимости от контекста.
Для обучения этой модели было использовано более 20 триллионов токенов, но время обучения составило менее 30 дней. За это время система достигла 98,48% времени доступности, практически не требуя вмешательства человека для устранения сбоев — то есть весь процесс обучения был практически полностью автоматизирован.
Еще более впечатляет то, что модель, обученная таким образом, показывает отличные результаты и при реальном развертывании.
Как показано на рисунке ниже, как неразмышляющая модель, LongCat-Flash достигает производительности, сопоставимой с SOTA неразмышляющими моделями, включая DeepSeek-V3.1 и Kimi-K2, при этом имея меньше параметров и более высокую скорость инференса. Это делает ее конкурентоспособной и практичной для задач общего назначения, программирования, использования инструментов агентами и других направлений.
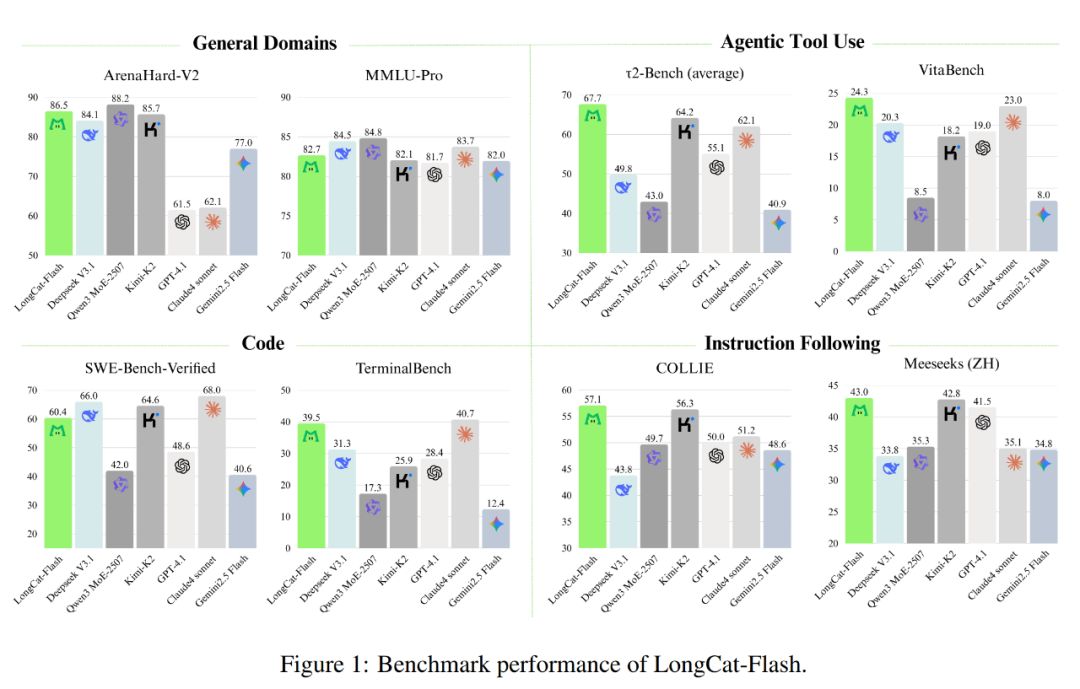
Кроме того, стоимость ее использования также впечатляет — всего 0,7 доллара за миллион выходных токенов. Это очень выгодно по сравнению с моделями аналогичного масштаба на рынке.
С технической точки зрения LongCat-Flash ориентирована на две цели языковых моделей: вычислительная эффективность и агентные способности, сочетая архитектурные инновации и многоступенчатое обучение для создания масштабируемой и интеллектуальной системы моделей.
В архитектуре модели LongCat-Flash использует новую MoE-архитектуру (рис. 2), основные особенности которой:
Эксперты с нулевыми вычислениями (Zero-computation Experts);
MoE с shortcut-соединениями (Shortcut-connected MoE, ScMoE).
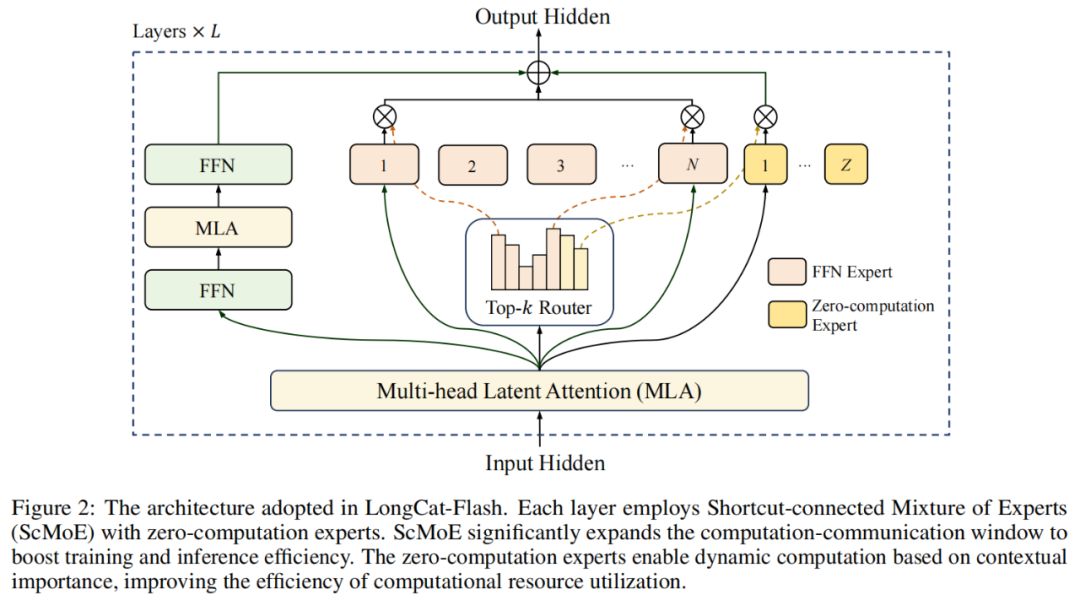
Эксперты с нулевыми вычислениями
Основная идея экспертов с нулевыми вычислениями — не все токены «равны».
Это можно понять так: в предложении есть слова, которые очень легко предсказать, например, «的», «是» (аналогично русским служебным словам), для них почти не нужны вычисления, а есть слова, например, имена людей, для которых требуется много вычислений для точного предсказания.
В предыдущих исследованиях обычно применяли такой подход: независимо от сложности токена для каждого активируется фиксированное количество (K) экспертов, что приводит к огромным вычислительным издержкам. Для простых токенов нет необходимости вызывать столько экспертов, а для сложных может не хватать вычислительных ресурсов.
Вдохновившись этим, LongCat-Flash предложила механизм динамического распределения вычислительных ресурсов: с помощью экспертов с нулевыми вычислениями для каждого токена динамически активируется разное количество FFN (Feed-Forward Network) экспертов, что позволяет более рационально распределять вычисления в зависимости от важности токена в контексте.
Конкретно, в пуле экспертов LongCat-Flash, помимо стандартных N FFN-экспертов, добавлены Z экспертов с нулевыми вычислениями. Такие эксперты просто возвращают входные данные без дополнительных вычислений.
MoE-модуль в LongCat-Flash формализуется так:
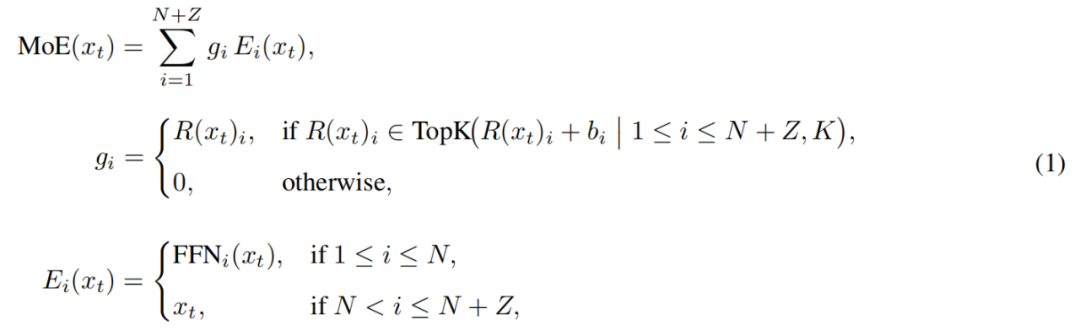
Здесь x_t — t-й токен входной последовательности, R — softmax-роутер, b_i — смещение для i-го эксперта, K — количество экспертов, выбранных для каждого токена. Роутер распределяет каждый токен между K экспертами, причем количество активируемых FFN-экспертов меняется в зависимости от важности токена в контексте. Благодаря такому адаптивному механизму распределения модель учится выделять больше вычислительных ресурсов для более важных токенов, что позволяет достичь лучшей производительности при том же объеме вычислений, как показано на рис. 3a.
Кроме того, при обработке входных данных модель должна научиться определять, стоит ли тратить больше вычислений на тот или иной токен. Если не контролировать частоту выбора экспертов с нулевыми вычислениями, модель может склоняться к выбору вычислительных экспертов, игнорируя экспертов с нулевыми вычислениями, что снижает эффективность использования ресурсов.
Для решения этой проблемы Meituan усовершенствовала механизм смещений экспертов в стратегии aux-loss-free: введено индивидуальное смещение для каждого эксперта, которое динамически корректирует роутинг-балл на основе недавнего использования эксперта, при этом не влияя на основную цель обучения языковой модели.
Правила обновления реализованы с помощью PID-контроллера из теории управления, который в реальном времени корректирует смещения экспертов. Благодаря этому при обработке каждого токена модель активирует лишь 18.6–31.3 миллиарда (в среднем около 27 миллиардов) параметров, что обеспечивает оптимальное распределение ресурсов.
Shortcut-connected MoE
Еще одна особенность LongCat-Flash — механизм shortcut-соединений в MoE.
Обычно эффективность масштабных MoE-моделей сильно ограничивается издержками на коммуникацию. В традиционной парадигме эксперты работают последовательно: сначала требуется глобальная коммуникация для роутинга токенов к экспертам, а затем начинается вычисление.
Такой порядок «сначала коммуникация, потом вычисление» приводит к дополнительному времени ожидания, особенно в масштабном распределенном обучении, где задержки коммуникации становятся узким местом.
Ранее исследователи пытались использовать архитектуру общих экспертов, чтобы перекрыть коммуникацию и вычисления одного эксперта, но эффективность ограничивалась малым окном вычислений одного эксперта.
Meituan преодолела это ограничение, введя архитектуру ScMoE, где между слоями добавлено shortcut-соединение. Эта инновация позволяет: вычисления плотного FFN предыдущего слоя выполняются параллельно с коммуникацией распределения/агрегации в текущем MoE-слое, что формирует более широкое окно перекрытия коммуникации и вычислений по сравнению с архитектурой общих экспертов.
Эта архитектура была подтверждена в ряде экспериментов.
Во-первых, дизайн ScMoE не снижает качество модели. Как показано на рис. 4, кривая потерь при обучении для ScMoE практически идентична базовой архитектуре без ScMoE, что доказывает отсутствие ущерба для производительности. Это подтверждено в различных конфигурациях.
Более того, результаты показывают: стабильность и преимущества производительности ScMoE ортогональны выбору механизма внимания (то есть сохраняются при любом attention-механизме).
Во-вторых, архитектура ScMoE обеспечивает значительный прирост эффективности на уровне системы как при обучении, так и при инференсе. В частности:
В масштабном обучении: расширенное окно перекрытия позволяет вычислениям предыдущих блоков полностью параллелиться с коммуникацией распределения и агрегации в MoE-слое, что достигается путем разбиения операций на мелкие блоки по размерности токенов.
В эффективном инференсе: ScMoE поддерживает однопакетный overlapped pipeline, что снижает теоретическое время вывода токена (TPOT) почти на 50% по сравнению с такими моделями, как DeepSeek-V3. Более того, он позволяет полностью параллелить коммуникацию разных типов: внутриузловую тензорную коммуникацию плотного FFN (через NVLink) и межузловую коммуникацию экспертов (через RDMA), что максимизирует общую загрузку сети.
В целом, ScMoE обеспечивает значительный прирост производительности без ущерба для качества модели.
Стратегии масштабирования модели и многоступенчатое обучение
Meituan также предложила эффективную стратегию масштабирования модели, которая значительно улучшает производительность при увеличении масштаба.
Во-первых, это перенос гиперпараметров: при обучении сверхкрупных моделей прямой перебор гиперпараметров очень дорог и нестабилен. Поэтому Meituan сначала экспериментирует на меньших моделях, чтобы найти оптимальные параметры, а затем переносит их на крупную модель, что экономит ресурсы и обеспечивает результат. Правила переноса приведены в таблице 1:
Во-вторых, инициализация роста модели (Model Growth): Meituan начинает с полумасштабной модели, предварительно обученной на сотнях миллиардов токенов, сохраняет чекпоинт, затем расширяет модель до полного масштаба и продолжает обучение.
При таком подходе кривая потерь выглядит типично: сначала кратковременный рост, затем быстрое схождение и, в итоге, значительное превосходство над случайной инициализацией. На рис. 5b показан типичный результат эксперимента с 6B активируемых параметров, демонстрирующий преимущества инициализации роста модели.
Третья мера — многоуровневый stability suite: Meituan усилила стабильность обучения LongCat-Flash с трех сторон — стабильность роутера, стабильность активаций и стабильность оптимизатора.
Четвертая — детерминированные вычисления, что гарантирует полную воспроизводимость результатов и позволяет выявлять silent data corruption (SDC) в процессе обучения.
Благодаря этим мерам процесс обучения LongCat-Flash остается высоко стабильным, без необратимых всплесков потерь (loss spike).
Сохраняя стабильность обучения, Meituan также тщательно спроектировала pipeline обучения, чтобы LongCat-Flash приобрела продвинутые агентные способности. Процесс включает масштабное предварительное обучение, среднеэтапное обучение для развития навыков рассуждения и программирования, а также постобучение, сфокусированное на диалогах и использовании инструментов.
На начальном этапе строится базовая модель, более подходящая для последующего агентного обучения; для этого Meituan разработала двухэтапную стратегию слияния данных для концентрации данных из областей, насыщенных задачами рассуждения.
На среднем этапе Meituan дополнительно усиливает способности модели к рассуждению и программированию; одновременно увеличивает длину контекста до 128k, чтобы удовлетворить потребности агентного обучения.
Наконец, проводится многоступенчатое постобучение. Учитывая дефицит высококачественных и сложных обучающих данных для агентов, Meituan разработала многоагентную синтетическую платформу: она определяет сложность задач по трем осям — обработка информации, сложность набора инструментов и взаимодействие с пользователем, а специальный контроллер генерирует задачи, требующие итеративного рассуждения и взаимодействия с окружением.
Такой подход обеспечивает отличные результаты при выполнении сложных задач, требующих вызова инструментов и взаимодействия с окружением.
Быстро и дешево в работе
Как LongCat-Flash этого добилась?
Как уже упоминалось, LongCat-Flash может выполнять инференс на H800 со скоростью более 100 токенов в секунду, а стоимость составляет всего 0,7 доллара за миллион выходных токенов — то есть работает быстро и дешево.
Как это реализовано? Во-первых, у них параллельная архитектура инференса, спроектированная совместно с архитектурой модели; во-вторых, они внедрили оптимизации вроде квантования и кастомных ядер.
Специальные оптимизации: чтобы модель «сама работала плавно»
Известно, что для построения эффективной системы инференса нужно решить две ключевые задачи: координация вычислений и коммуникаций, а также чтение/запись и хранение KV-кэша.
Для первой задачи обычно используют три уровня параллелизма: перекрытие на уровне операторов, на уровне экспертов и на уровне слоев. Архитектура ScMoE в LongCat-Flash добавляет четвертое измерение — перекрытие на уровне модулей. Для этого команда разработала SBO (Single Batch Overlap) стратегию планирования для оптимизации задержки и пропускной способности.
SBO — это четырехэтапный pipeline, который максимально использует потенциал LongCat-Flash за счет перекрытия на уровне модулей (см. рис. 9). В отличие от TBO, SBO скрывает издержки на коммуникацию внутри одного батча. На первом этапе выполняется расчет MLA, подготавливая вход для следующих этапов; на втором этапе Dense FFN и Attn 0 (QKV-проекция) перекрываются с all-to-all dispatch-коммуникацией; на третьем этапе отдельно выполняется MoE GEMM, задержка которого минимизируется за счет широкой стратегии EP; на четвертом этапе Attn 1 (основное внимание и выходная проекция) и Dense FFN перекрываются с all-to-all combine. Такой дизайн эффективно снижает издержки на коммуникацию и обеспечивает высокоэффективный инференс LongCat-Flash.
Для второй задачи — чтения/записи и хранения KV-кэша — LongCat-Flash решает эти проблемы за счет инноваций в attention-механизме и архитектуре MTP, что снижает I/O-нагрузку.
Во-первых, ускорение speculative decoding. LongCat-Flash использует MTP как черновую модель, оптимизируя три ключевых фактора через системный анализ формулы ускорения speculative decoding: ожидаемую длину принятия, соотношение стоимости черновой и целевой моделей, а также соотношение стоимости валидации и декодирования. Интеграция одной MTP-головы и внедрение на поздних этапах pretraining обеспечили около 90% принятия. Для баланса качества и скорости черновика используется легковесная архитектура MTP и метод C2T для фильтрации маловероятных токенов через классификационную модель.
Во-вторых, оптимизация KV-кэша реализована через 64-головочный attention MLA. MLA обеспечивает баланс между производительностью и эффективностью, значительно снижая вычислительную нагрузку и обеспечивая отличное сжатие KV-кэша, уменьшая нагрузку на память и пропускную способность. Это критично для pipeline LongCat-Flash, поскольку модель всегда содержит attention-вычисления, которые нельзя перекрыть с коммуникацией.
Системные оптимизации: чтобы оборудование работало «командой»
Для минимизации издержек на планирование команда LongCat-Flash решила проблему launch-bound, вызванную издержками запуска ядер в LLM-инференсе. Особенно после внедрения speculative decoding независимое планирование валидационных и черновых forward-операций приводит к значительным издержкам. С помощью стратегии TVD они объединили целевой forward, валидацию и черновой forward в один CUDA-граф. Для дальнейшего повышения загрузки GPU реализован overlapped scheduler и multi-step overlapped scheduler, который запускает несколько forward-операций за одну итерацию планирования, эффективно скрывая издержки на планирование и синхронизацию CPU.
Кастомные ядра оптимизированы под особенности autoregressive-инференса LLM. Этап prefill вычислительно интенсивен, а этап decoding часто ограничен памятью из-за малых и нерегулярных размеров батча. Для MoE GEMM применяется техника SwapAB, где веса считаются левой матрицей, а активации — правой, что позволяет максимально использовать tensor core за счет гибкости по размерности n (8 элементов). Коммуникационные ядра используют аппаратное ускорение NVLink Sharp для broadcast и in-switch reduction, минимизируя перемещение данных и загрузку SM, и превосходят NCCL и MSCCL++ на диапазоне сообщений от 4KB до 96MB, используя всего 4 thread block.
В части квантования LongCat-Flash использует тот же fine-grained block-level quantization, что и DeepSeek-V3. Для оптимального баланса между производительностью и точностью реализовано смешанное квантование по слоям на основе двух схем: первая выявляет линейные слои (особенно Downproj) с экстремальной амплитудой входных активаций до 10^6; вторая вычисляет ошибку FP8-квантования по блокам для каждого слоя и находит значительные ошибки в отдельных экспертных слоях. Пересечение этих схем дает значительный прирост точности.
Практические данные: насколько быстро и дешево?
Тесты показывают, что LongCat-Flash демонстрирует отличные результаты в разных условиях. По сравнению с DeepSeek-V3 при аналогичной длине контекста LongCat-Flash обеспечивает большую пропускную способность и более высокую скорость генерации.
В агентных приложениях, учитывая разницу между инференсом контента (видим для пользователя, должен соответствовать скорости чтения — около 20 токенов/с) и команд действий (невидим для пользователя, но напрямую влияет на время запуска инструментов, требует максимальной скорости), скорость генерации LongCat-Flash около 100 токенов/с позволяет держать задержку вызова инструмента менее 1 секунды, что значительно повышает интерактивность. При стоимости H800 GPU 2 доллара в час это означает цену 0,7 доллара за миллион выходных токенов.
Теоретический анализ производительности показывает, что задержка LongCat-Flash определяется тремя компонентами: MLA, all-to-all dispatch/combine и MoE. При EP=128, batch=96 на карту, MTP acceptance rate ≈80% теоретический предел TPOT составляет 16 мс, что значительно лучше, чем у DeepSeek-V3 (30 мс) и Qwen3-235B-A22B (26,2 мс). При стоимости H800 GPU 2 доллара в час LongCat-Flash выдает цену 0,09 доллара за миллион токенов, что намного ниже, чем у DeepSeek-V3 (0,17 доллара). Однако это теоретические пределы.
Мы также протестировали LongCat-Flash на бесплатной демо-странице.
Сначала мы попросили модель написать статью о осени, примерно на 1000 слов.
Как только мы сформулировали запрос и начали запись экрана, LongCat-Flash уже выдала ответ — мы даже не успели вовремя остановить запись.
Если присмотреться, видно, что первый токен LongCat-Flash выводит особенно быстро. В других диалоговых моделях часто приходится ждать, что раздражает пользователя, как если бы вы спешили прочитать сообщение в WeChat, а телефон показывает «получение». LongCat-Flash меняет этот опыт — задержка первого токена практически не ощущается.
Дальнейшая генерация токенов также очень быстрая, намного опережая скорость чтения глазами.
Далее мы включили «поиск в интернете», чтобы проверить скорость этой функции. Мы попросили LongCat-Flash порекомендовать хорошие рестораны рядом с Wangjing.
В ходе теста было явно заметно, что LongCat-Flash не «думает» долго, а практически мгновенно выдает ответ. Поиск в интернете также ощущается как «быстрый». Более того, модель не только быстро отвечает, но и приводит ссылки на источники, что обеспечивает достоверность и отслеживаемость информации.
Если у вас есть возможность скачать модель, попробуйте запустить ее локально и посмотрите, насколько впечатляющей окажется скорость LongCat-Flash.
Когда большие модели становятся по-настоящему практичными
В последние годы при появлении новой большой модели все интересовались: каковы ее benchmark-результаты? Сколько рейтингов она обновила? Является ли она SOTA? Сейчас ситуация изменилась. При схожих возможностях все больше интересует: дорого ли использовать эту модель? Какова скорость? Среди компаний и разработчиков, использующих open-source модели, это особенно заметно. Ведь многие выбирают open-source, чтобы снизить зависимость и расходы на закрытые API, поэтому они более чувствительны к вычислительным требованиям, скорости инференса и эффективности квантования.
Открытая Meituan модель LongCat-Flash — яркий представитель этого тренда. Они сделали акцент на том, чтобы большие модели были действительно доступны и быстры — это ключ к массовому внедрению технологий.
Такой практичный подход соответствует нашему восприятию Meituan. Ранее большинство их технических инвестиций были направлены на решение реальных бизнес-проблем: например, статья EDPLVO, получившая в 2022 году премию ICRA за лучшую работу по навигации, была создана для решения проблем, с которыми сталкиваются дроны при доставке (например, потеря сигнала из-за плотной застройки); недавно они участвовали в разработке глобального стандарта ISO по предотвращению столкновений дронов — это результат накопленного опыта по избежанию препятствий, таких как воздушные змеи или страховочные тросы. А LongCat-Flash — это модель, лежащая в основе их AI-инструмента для программирования «NoCode», который используется как внутри компании, так и доступен бесплатно для всех, чтобы каждый мог попробовать vibe coding и повысить эффективность при снижении затрат.
Этот переход от гонки за производительностью к практической направленности отражает естественный ход развития AI-индустрии. По мере выравнивания возможностей моделей инженерная эффективность и стоимость развертывания становятся ключевыми факторами дифференциации. Открытие LongCat-Flash — лишь один из примеров этого тренда, но он действительно дает сообществу технологический ориентир: как, сохраняя качество модели, снизить порог использования за счет архитектурных и системных инноваций. Для разработчиков и компаний с ограниченным бюджетом, желающих использовать передовые AI-возможности, это, безусловно, ценно.
Дисклеймер: содержание этой статьи отражает исключительно мнение автора и не представляет платформу в каком-либо качестве. Данная статья не должна являться ориентиром при принятии инвестиционных решений.
Вам также может понравиться
Децентрализованный AI-проект GAEA завершил стратегический раунд финансирования на 10 миллионов долларов для построения новых отношений между человеком и AI.
GAEA — это первая децентрализованная AI-сеть для обучения, интегрирующая данные человеческих эмоций. Она направлена на создание платформы для эволюции AI, обеспечивая легкий и безопасный для приватности доступ к подлинным человеческим данным для открытых AI-проектов и их лучшего понимания.

Сколько нужно заработать в криптомире, чтобы осмелиться сказать, что «изменил свою судьбу»?
Настоящий риск заключается не в "потерях", а в том, что ты "никогда не узнаешь, что уже победил".

NBER | С помощью моделей раскрывается, как расширение цифровой экономики трансформирует глобальный финансовый ландшафт
Результаты исследования показывают, что в долгосрочной перспективе эффект спроса на резервы преобладает над эффектом замещения, что приводит к снижению процентных ставок в США и увеличению внешних заимствований Соединённых Штатов.
