
Виталик: Архитектура glue и сопроцессоров — новая концепция для повышения эффективности и безопасности

Склеивающий элемент должен быть оптимизирован для того, чтобы быть хорошим склеивающим элементом, а сопроцессор — для того, чтобы быть хорошим сопроцессором.
Клей должен быть оптимизирован для того, чтобы быть хорошим клеем, а сопроцессор — для того, чтобы быть хорошим сопроцессором.
Оригинальное название: «Glue and coprocessor architectures»
Автор: Vitalik Buterin, основатель Ethereum
Перевод: Deng Tong, Jinse Finance
Особая благодарность Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra и различным участникам Flashbots за предоставленные отзывы и комментарии.
Если вы с умеренной степенью детализации проанализируете любой ресурсоемкий вычислительный процесс в современном мире, вы снова и снова обнаружите одну особенность: вычисления можно разделить на две части:
- Относительно небольшое количество сложной, но не ресурсоемкой «бизнес-логики»;
- Большое количество интенсивной, но высокоструктурированной «дорогой работы».
Эти две формы вычислений лучше всего обрабатывать по-разному: первая может быть менее эффективной по архитектуре, но требует очень высокой универсальности; вторая — менее универсальна, но требует очень высокой эффективности.
Какие примеры такого различия существуют на практике?
Для начала давайте рассмотрим среду, с которой я знаком лучше всего: Ethereum Virtual Machine (EVM). Вот отладочный трейс geth для недавней транзакции в Ethereum: обновление IPFS-хэша моего блога в ENS. Эта транзакция в сумме потребила 46924 газа, которые можно классифицировать следующим образом:
- Базовая стоимость: 21,000
- Данные вызова: 1,556
- Выполнение EVM: 24,368
- Операция SLOAD: 6,400
- Операция SSTORE: 10,100
- Операция LOG: 2,149
- Другое: 6,719

Трассировка EVM для обновления ENS-хэша. Вторая с конца колонка — потребление газа.
Мораль этой истории такова: большая часть исполнения (если смотреть только на EVM — около 73%, если учитывать базовую стоимость, покрывающую вычисления — около 85%) сосредоточена в очень небольшом количестве структурированных дорогих операций: чтение и запись в хранилище, логирование и криптография (базовая стоимость включает 3000 за проверку подписи, EVM также включает 272 за хэширование). Остальная часть исполнения — это «бизнес-логика»: перестановка битов calldata для извлечения ID записи, которую я пытаюсь установить, и хэша, на который я её устанавливаю, и т.д. В переводе токенов это будет сложение и вычитание баланса, в более сложных приложениях — циклы и прочее.
В EVM эти две формы исполнения обрабатываются по-разному. Высокоуровневая бизнес-логика пишется на более высокоуровневых языках, обычно на Solidity, который компилируется в EVM. Дорогая работа по-прежнему инициируется опкодами EVM (такими как SLOAD), но более 99% реальных вычислений выполняется в специализированных модулях, написанных непосредственно во внутреннем коде клиента (или даже в библиотеках).
Чтобы лучше понять этот паттерн, давайте рассмотрим другой контекст: AI-код на Python с использованием torch.
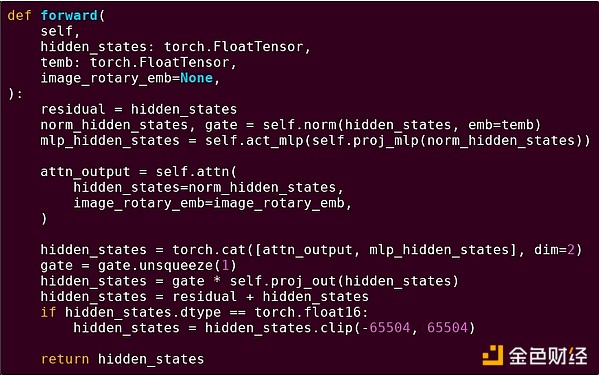
Прямой проход одного блока трансформер-модели
Что мы здесь видим? Мы видим относительно небольшое количество «бизнес-логики», написанной на Python, которая описывает структуру выполняемых операций. На практике будет и другой тип бизнес-логики, определяющий такие детали, как получение входных данных и обработка выходных. Но если мы углубимся в каждую отдельную операцию (self.norm, torch.cat, +, *, отдельные шаги внутри self.attn...), мы увидим векторизованные вычисления: одни и те же операции параллельно применяются к большому количеству значений. Как и в первом примере, небольшая часть вычислений уходит на бизнес-логику, а большая часть — на выполнение крупных структурированных матричных и векторных операций — по сути, в основном матричное умножение.
Как и в примере с EVM, эти два типа работы обрабатываются по-разному. Высокоуровневый код бизнес-логики пишется на Python — это очень универсальный и гибкий язык, но очень медленный, и мы просто принимаем низкую эффективность, потому что он затрагивает лишь небольшую часть общих вычислительных затрат. В то же время интенсивные операции пишутся на высокооптимизированном коде, обычно CUDA, который работает на GPU. Мы даже всё чаще видим, что LLM-инференс выполняется на ASIC.
Современная программируемая криптография, такая как SNARK, снова следует аналогичной модели на двух уровнях. Во-первых, прувер может быть написан на высокоуровневом языке, где тяжёлая работа выполняется векторизованными операциями, как в AI-примере выше. Мой круговой STARK-код это демонстрирует. Во-вторых, сама программа, исполняемая внутри криптографии, может быть написана так, чтобы разделять универсальную бизнес-логику и высокоструктурированную дорогую работу.
Чтобы понять, как это работает, давайте посмотрим на одну из последних тенденций в STARK-доказательствах. Для универсальности и удобства команды всё чаще строят STARK-пруверы для широко используемых минимальных виртуальных машин, таких как RISC-V. Любая программа, выполнение которой нужно доказать, может быть скомпилирована в RISC-V, после чего прувер может доказать выполнение этого кода на RISC-V.
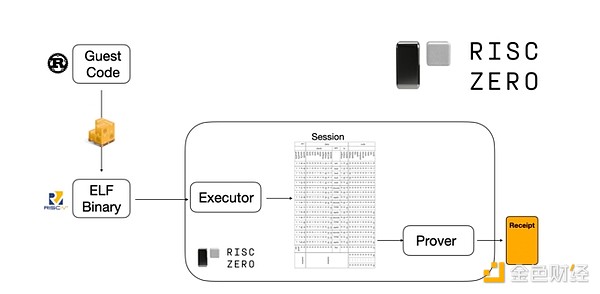
Диаграмма из документации RiscZero
Это очень удобно: это значит, что нам нужно написать логику доказательства только один раз, и с этого момента любую программу, которую нужно доказать, можно писать на любом «традиционном» языке программирования (например, RiskZero поддерживает Rust). Но есть проблема: этот подход создаёт большие накладные расходы. Программируемая криптография и так очень дорогая; добавление накладных расходов на выполнение кода в интерпретаторе RISC-V слишком велико. Поэтому разработчики придумали трюк: определить конкретные дорогие операции, составляющие большую часть вычислений (обычно это хэши и подписи), а затем создать специализированные модули для очень эффективного доказательства этих операций. Затем вы просто комбинируете неэффективную, но универсальную систему доказательств RISC-V с эффективной, но специализированной системой доказательств — и получаете лучшее из обоих миров.
Программируемая криптография за пределами ZK-SNARK, например, многопартийные вычисления (MPC) и полностью гомоморфное шифрование (FHE), также могут быть оптимизированы аналогичным образом.
В целом, какова суть этого явления?
Современные вычисления всё чаще следуют тому, что я называю архитектурой клея и сопроцессора: у вас есть центральный «клеящий» компонент, обладающий высокой универсальностью, но низкой эффективностью, который отвечает за передачу данных между одним или несколькими сопроцессорами, обладающими низкой универсальностью, но высокой эффективностью.
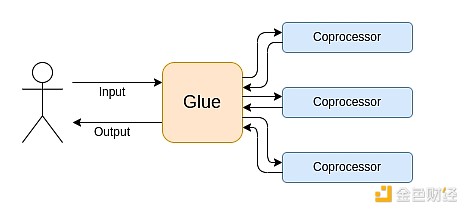
Это упрощение: на практике компромисс между эффективностью и универсальностью почти всегда имеет больше двух уровней. GPU и другие чипы, обычно называемые в индустрии «сопроцессорами», менее универсальны, чем CPU, но более универсальны, чем ASIC. Компромиссы в специализации сложны и зависят от прогнозов и интуиции о том, какие части алгоритма останутся неизменными через пять лет, а какие изменятся через полгода. В архитектуре ZK-доказательств мы часто видим аналогичную многоуровневую специализацию. Но для широкой модели мышления достаточно двух уровней. Во многих вычислительных областях наблюдается похожая ситуация:
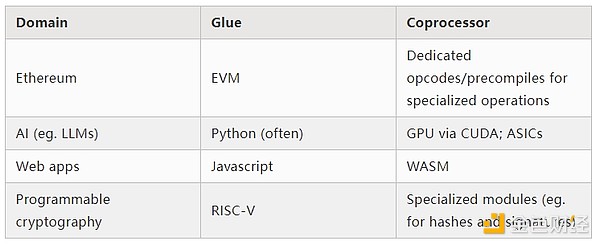
Из приведённых выше примеров видно, что вычисления действительно можно разделить таким образом, и это кажется естественным законом. На самом деле, вы можете найти примеры специализации вычислений за десятилетия. Однако я считаю, что это разделение усиливается. И на то есть причины:
Только недавно мы достигли предела увеличения тактовой частоты CPU, поэтому дальнейшие улучшения возможны только за счёт параллелизма. Но параллелизм сложно анализировать, поэтому для разработчиков зачастую практичнее продолжать рассуждать последовательно и позволять параллелизму происходить на бэкенде, обёрнутом в специализированные модули для конкретных операций.
Скорость вычислений недавно стала настолько высокой, что вычислительные затраты бизнес-логики стали по-настоящему незначительными. В таком мире оптимизация VM для бизнес-логики ради целей, отличных от вычислительной эффективности, тоже имеет смысл: удобство для разработчиков, знакомство, безопасность и другие подобные цели. В то же время специализированные модули «сопроцессоров» могут продолжать проектироваться для эффективности и получать свою безопасность и удобство для разработчиков от относительно простого «интерфейса» с клеем.
Всё более ясно, какие именно операции являются самыми дорогими. Это особенно заметно в криптографии, где наиболее вероятны определённые типы дорогих операций: модульные вычисления, линейные комбинации на эллиптических кривых (также известные как многоскалярное умножение), быстрое преобразование Фурье и т.д. В AI это тоже становится всё более очевидным: уже более двадцати лет большая часть вычислений — это «в основном матричное умножение» (хотя и с разной точностью). В других областях наблюдаются аналогичные тенденции. По сравнению с 20 годами назад, в (вычислительно интенсивных) вычислениях гораздо меньше неизвестных неизвестных.
Что это значит?
Ключевой момент в том, что клей (Glue) должен быть оптимизирован для того, чтобы быть хорошим клеем, а сопроцессор (coprocessor) — для того, чтобы быть хорошим сопроцессором. Мы можем рассмотреть, что это значит, на нескольких ключевых примерах.
EVM
Виртуальным машинам блокчейна (например, EVM) не нужна высокая эффективность, им нужно быть знакомыми. Просто добавьте правильные сопроцессоры (также известные как «предкомпилированные»), и вычисления в неэффективной VM на самом деле могут быть столь же эффективны, как и в нативной эффективной VM. Например, накладные расходы из-за 256-битных регистров EVM относительно малы, а преимущества знакомости EVM и существующей экосистемы разработчиков огромны и долговременны. Команды, оптимизирующие EVM, даже обнаружили, что отсутствие параллелизма обычно не является основным препятствием для масштабируемости.
Лучший способ улучшить EVM, возможно, просто (i) добавить лучшие предкомпилированные или специализированные опкоды, например, нечто вроде комбинации EVM-MAX и SIMD, и (ii) улучшить структуру хранения, например, изменения Verkle tree в качестве побочного эффекта значительно снижают стоимость доступа к соседним слотам хранения.
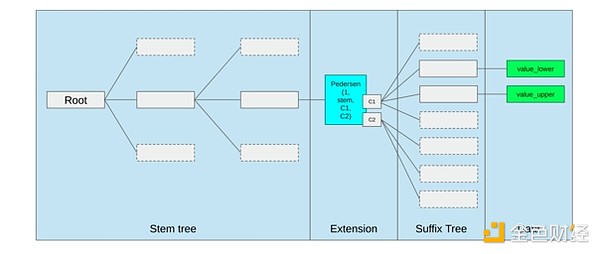
Оптимизация хранения из предложения Ethereum Verkle tree, где соседние ключи хранения располагаются вместе, а стоимость газа скорректирована соответственно. Такие оптимизации, вместе с лучшими предкомпилированными, могут быть важнее, чем изменение самой EVM.
Безопасные вычисления и открытое оборудование
Одна из главных проблем повышения безопасности современных вычислений на аппаратном уровне — их чрезмерная сложность и закрытость: чипы проектируются для эффективности, что требует проприетарных оптимизаций. Закладки легко скрыть, побочные каналы постоянно обнаруживаются.
Люди продолжают работать над более открытыми и безопасными альтернативами с разных сторон. Некоторые вычисления всё чаще выполняются в доверенных средах, включая пользовательские смартфоны, что уже повысило безопасность пользователей. Движение за более открытое потребительское оборудование продолжается, и недавно были достигнуты некоторые успехи, например, ноутбук на RISC-V под управлением Ubuntu.
Ноутбук на RISC-V под управлением Debian
Однако эффективность всё ещё остаётся проблемой. Автор вышеуказанной статьи пишет:
Такие новые открытые чип-дизайны, как RISC-V, не могут сравниться с процессорными технологиями, которые существуют и совершенствуются десятилетиями. Прогресс всегда начинается с чего-то.
Более параноидальные идеи, например, такой дизайн компьютера на RISC-V на FPGA, сталкиваются с ещё большими накладными расходами. Но что если архитектура клея и сопроцессора означает, что эти накладные расходы на самом деле не важны? Что если мы примем, что открытые и безопасные чипы будут медленнее проприетарных, если потребуется — даже откажемся от таких обычных оптимизаций, как спекулятивное исполнение и предсказание ветвлений, но попытаемся компенсировать это добавлением (если нужно, проприетарных) ASIC-модулей для самых ресурсоёмких специфических вычислений? Чувствительные вычисления могут выполняться на «главном чипе», оптимизированном для безопасности, открытости и устойчивости к побочным каналам. Более интенсивные вычисления (например, ZK-доказательства, AI) будут выполняться на ASIC-модулях, которые будут знать меньше о выполняемых вычислениях (возможно, с помощью криптографического ослепления — в некоторых случаях даже ноль информации).
Криптография
Ещё один ключевой момент — всё это очень оптимистично для криптографии, особенно для программируемой криптографии как мейнстрима. Мы уже видели сверхоптимизированные реализации некоторых конкретных высокоструктурированных вычислений в SNARK, MPC и других системах: накладные расходы на некоторые хэш-функции всего в несколько сотен раз выше, чем при прямом вычислении, а накладные расходы на AI (в основном матричное умножение) тоже очень низки. Дальнейшие улучшения, такие как GKR, могут ещё больше снизить этот уровень. Полностью универсальное выполнение VM, особенно в интерпретаторе RISC-V, может по-прежнему давать накладные расходы примерно в 10,000 раз, но по причинам, описанным в этой статье, это не важно: если самые ресурсоёмкие части вычислений обрабатываются с помощью эффективных специализированных техник, общий накладной расход остаётся контролируемым.
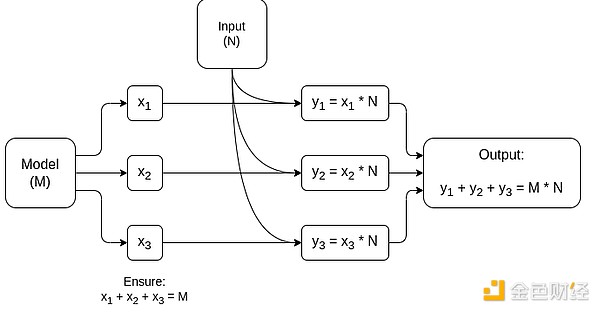
Упрощённая схема MPC, специализированного для матричного умножения — самой крупной составляющей инференса AI-моделей. Подробнее см. в этой статье, включая способы сохранения приватности модели и входных данных.
Исключением из идеи «клеящий слой должен быть знакомым, а не эффективным» являются задержки, а в меньшей степени — пропускная способность данных. Если вычисления включают десятки повторяющихся тяжёлых операций над одними и теми же данными (как в криптографии и AI), любая задержка, вызванная неэффективным клеящим слоем, может стать основным узким местом по времени выполнения. Поэтому у клеящего слоя тоже есть требования к эффективности, хотя они более специфичны.
Заключение
В целом, я считаю, что описанные выше тенденции — очень позитивное развитие с разных точек зрения. Во-первых, это разумный способ максимизировать вычислительную эффективность при сохранении удобства для разработчиков, что приносит пользу всем. Особенно, специализация на стороне клиента для повышения эффективности увеличивает наши возможности выполнять чувствительные и требовательные к производительности вычисления (например, ZK-доказательства, LLM-инференс) локально на пользовательском оборудовании. Во-вторых, это создаёт огромное окно возможностей, чтобы стремление к эффективности не вредило другим ценностям, самым очевидным из которых являются безопасность, открытость и простота: безопасность и открытость аппаратного обеспечения против побочных каналов, снижение сложности схем в ZK-SNARK, снижение сложности виртуальных машин. Исторически стремление к эффективности отодвигало эти факторы на второй план. С архитектурой клея и сопроцессора в этом больше нет необходимости. Одна часть машины оптимизируется для эффективности, другая — для универсальности и других ценностей, и они работают вместе.
Эта тенденция также очень благоприятна для криптографии, поскольку сама криптография — один из главных примеров «дорогих структурированных вычислений», и эта тенденция ускоряет её развитие. Это даёт ещё одну возможность повысить безопасность. В мире блокчейна также становится возможным повысить безопасность: мы можем меньше беспокоиться об оптимизации виртуальных машин и больше — об оптимизации предкомпилированных и других функций, сосуществующих с виртуальной машиной.
В-третьих, эта тенденция открывает возможности для небольших и новых участников. Если вычисления становятся менее монолитными, а более модульными, это значительно снижает барьер для входа. Даже ASIC для одного типа вычислений может быть полезен. То же самое относится к области ZK-доказательств и оптимизации EVM. Написание кода с почти передовой эффективностью становится проще и доступнее. Аудит и формальная верификация такого кода также становятся проще и доступнее. И наконец, поскольку эти очень разные вычислительные области сходятся к некоторым общим паттернам, между ними появляется больше пространства для сотрудничества и обмена опытом.
Дисклеймер: содержание этой статьи отражает исключительно мнение автора и не представляет платформу в каком-либо качестве. Данная статья не должна являться ориентиром при принятии инвестиционных решений.
Вам также может понравиться
Криптовалюта: Индекс страха упал до 10, но аналитики ожидают разворот

Uniswap Labs сталкивается с критикой, так как основатель Aave подчеркивает опасения по поводу централизации DAO

Дорожная карта Interop для Ethereum: как разблокировать «последнюю милю» для массового внедрения
От кросс-чейна к "интероперабельности": многочисленные инфраструктуры Ethereum ускоряют интеграцию системы для массового внедрения.

Выкуп на 170 миллионов долларов и функции AI всё ещё не могут скрыть упадок: Pump.fun застрял в цикле Meme.
Перед лицом сложной рыночной среды и внутренних вызовов сможет ли этот флагман мемов действительно восстановить свои позиции?
