
Остання AI-модель зображень "Banana" від Google викликає ажіотаж серед користувачів завдяки функції "Vibe Photoshoping"

Google AI Studio випустила Gemini 2.5 Flash Image (кодове ім’я nano-banana) — це найсучасніша модель генерації та редагування зображень від Google, яка працює швидко та має відмінні результати у багатьох рейтингах. Анотацію створено Mars AI Ця анотація згенерована моделлю Mars AI, і її точність та повнота все ще знаходяться на стадії удосконалення.

Пам’ятаєте загадкову AI-модель для редагування зображень «nano-banana», яка нещодавно викликала бурхливі обговорення? Тоді на LMArena, арені великих мовних моделей, вона завдяки своїй видатній продуктивності стала справжньою сенсацією. Провідні інженери Google Gemini також по черзі підігрівали інтерес у соціальних мережах, і навіть певний час її вважали чутками про Gemini 3.0 Pro.
Тепер Google нарешті зняла завісу таємниці з цього продукту.
О 8:00 ранку за східноазійським часом 27 серпня Google AI Studio офіційно представила Gemini 2.5 Flash Image (кодова назва nano banana) 🍌.
Gemini 2.5 Flash Image, на яку довго чекали, нарешті з’явилася | Джерело зображення: GeekPark
Це найсучасніша на сьогодні модель генерації та редагування зображень від Google: вона не лише надзвичайно швидка, забезпечуючи майже «блискавичний» досвід, а й встановила SOTA-результати у багатьох рейтингах, значно випереджаючи конкурентів на LMArena.
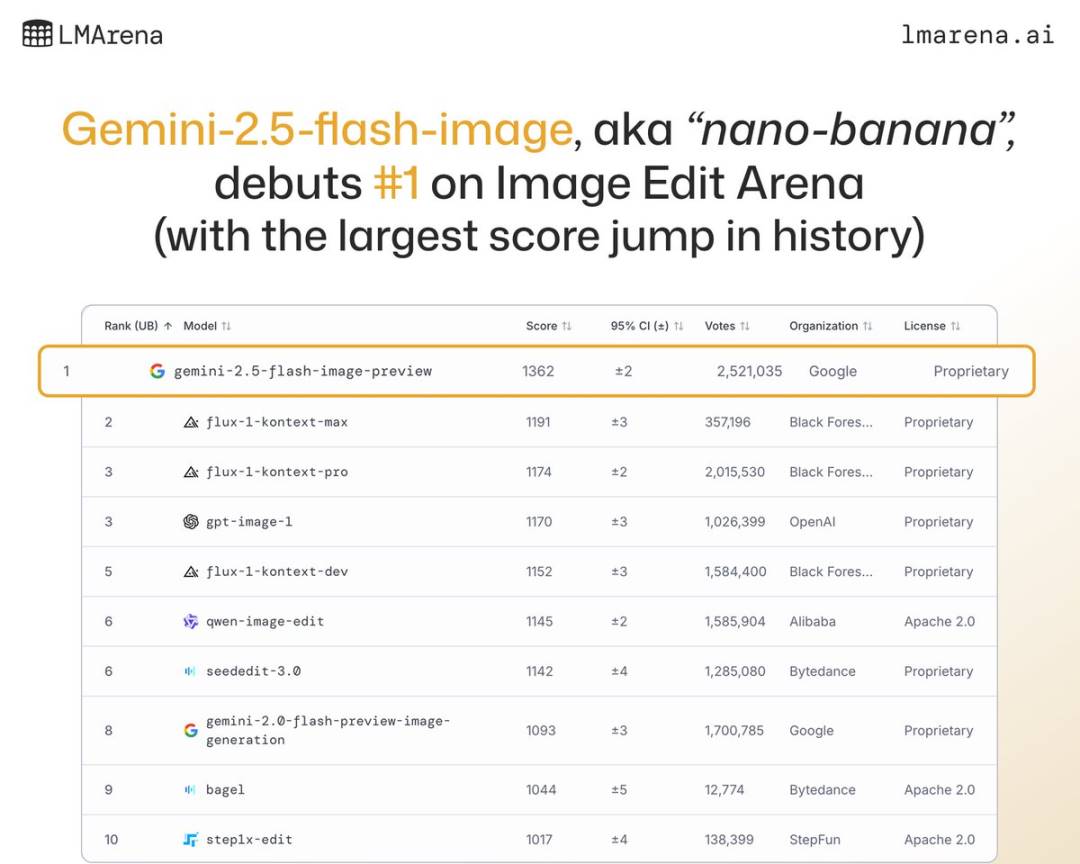
Gemini 2.5 Flash Image одразу досягає SOTA-рівня | Джерело зображення: LMarena.ai
У технічному блозі Google зазначає, що Gemini 2.0 Flash вже завоювала прихильність розробників завдяки низькій затримці та високій ефективності, але користувачі завжди очікували ще якісніших зображень і потужнішого контролю над творчістю. Саме з цими значними оновленнями і з’явилася Gemini 2.5 Flash Image: послідовність персонажів тепер зберігається повністю, редагування зображень за підказками стало точнішим, поєднання кількох зображень виглядає природно, а розуміння реальних знань про світ робить цю модель не просто інструментом, а «точкою відліку» для майбутніх хітових застосунків.
GeekPark також одразу протестував новинку. Неочікувано, це не просто оновлення моделі — вперше виникає відчуття, що майбутнє AI-редагування зображень вже зовсім поруч.
Google AI Studio вже відкрила доступ до тестування | Джерело зображення: GeekPark
Спочатку я просто хотів звично протестувати нову модель, «подивитися, чим вона швидша». Але несподівано, всього за кілька годин тестування я ніби зазирнув у майбутнє наступного покоління хітових застосунків.
Ми звикли до таких інструментів, як Meitu XiuXiu: натискаєш кнопку, накладаєш фільтр — і фото одразу стає гарнішим. Але Gemini 2.5 Flash Image створює зовсім інше враження. Вона неймовірно швидка, розумна, наче дизайнер, який читає твої думки: достатньо просто описати бажаний ефект, і вже за кілька секунд ти бачиш результат.

Окрім ефекту, швидкість — ще одна помітна відмінність Gemini 2.5 Flash Image від попередніх моделей | Джерело зображення: GeekPark
01 Блискавичне створення — результат за кілька секунд
Найочевидніше враження від nano banana — це швидкість. Раніше, навіть якщо у вас потужний комп’ютер, при використанні деяких open-source моделей доводилося чекати десятки секунд або й довше, щоб отримати пристойне зображення. Для користувачів смартфонів це очікування було ще боліснішим.
Але Gemini 2.5 Flash Image знизила цю планку до кількох секунд. Це, за заявою Google, «найновіша, найшвидша, найефективніша» нативна мультимодальна модель, для оптимізації якої доклали чимало зусиль. Під час тестування я вводив підказку — і вже за три-чотири секунди отримував результат із чіткою роздільною здатністю та деталізацією. (UTC+8)
Цей досвід нагадує звичну обробку фото в Meitu XiuXiu: натискаєш «покращити», і ефект майже миттєвий. Але різниця в тому, що Meitu XiuXiu застосовує фільтр, а Gemini 2.5 Flash Image створює зображення з нуля або радикально змінює фото відповідно до ваших побажань. Це відчуття «сказав — отримав» раніше було неможливим у складних процесах ручного редагування.

Такі завдання, як «видалити людей з фону», вирішуються одним prompt | Джерело зображення: GeekPark
Якщо швидкість вирішує проблему користувацького досвіду традиційних P-інструментів, то «нативна мультимодальність» розширює межі можливостей AI для зображень.
Gemini 2.5 Flash Image не лише генерує зображення, а й розуміє текстові та візуальні підказки одночасно. Це означає, що я можу завантажити фото й додати текстову інструкцію — і модель врахує обидва джерела інформації, щоб зрозуміти, чого я хочу.
Наприклад, я завантажив фото, зроблене на вулиці, і попросив «змінити фон на нічний Токіо, район Сіндзюку». В результаті модель не лише розпізнала головний об’єкт на фото, а й акуратно вирізала людину, замінивши фон на неонові вогні Сіндзюку. Ще важливіше — вона зберегла єдність світлотіні, уникнувши ефекту «грубої вставки», як це часто буває при ручному вирізанні.
Це нагадує функцію «заміна фону в один клік», яку останніми роками часто рекламують виробники смартфонів у стандартних галереях. Але тоді результат часто мав розмиті краї, неправильне освітлення, виглядав неприродно. Тепер же Gemini 2.5 Flash Image використовує знання про світ і візуальне розуміння для відтворення деталей, забезпечуючи набагато природніший результат, ніж традиційні text-to-image або image-to-image моделі.

Оригінал & результат Gemini 2.5 Flash Image | Джерело зображення: GeekPark
Ось чому я вважаю, що ця модель змінить досвід редагування: тепер не потрібно вручну налаштовувати безліч параметрів — модель сама розуміє ваші інструкції й виконує складні завдання, наприклад, у портретній обробці, де важлива кожна деталь.

Для таких завдань, як обробка портретів, Gemini 2.5 Flash Image забезпечує безпрецедентний досвід «Vibe Photoshoping» завдяки послідовності персонажів.

Одна секунда — і програмісту «врятовано репутацію» | Джерело зображення: GeekPark
Цей досвід руйнує уявлення багатьох про AI-генерацію зображень як про «магію»: якщо prompt хороший — результат вражає, якщо ні — виходить щось зовсім неочікуване.
Але в Gemini 2.5 Flash Image це відчуття «магії» значно зменшилося. Модель точніше розуміє підказки, краще відповідає очікуванням користувача — саме тому багато хто відразу відчуває, що працювати з нею набагато зручніше.
Наприклад, я кажу: «розмий фон, виділи людину на передньому плані» — і за кілька секунд отримую саме той ефект, який хотів; прошу «зробити людину на фото усміхненою» — і не лише куточки губ підняті, а й погляд змінено, деталі опрацьовані дуже ретельно; навіть коли я спробував «розфарбувати чорно-біле фото», результат був максимально наближений до історичної атмосфери, а не просто хаотичне розфарбування.
Ця здатність «сказав — зроблено» нагадує мені досвід із Meitu XiuXiu: хотів лише трохи згладити шкіру, а отримав «лялькове» обличчя з максимальним ефектом. Тепер же Gemini 2.5 Flash Image працює точно й стримано, дійсно розуміє ваші побажання й намагається їх відтворити.
02 Посилені можливості — після цього важко повернутися назад
Для наочності я спеціально порівняв цю модель із мобільними інструментами, якими користуюся щодня.
У Snapseed, щоб розмити фон, мені доводиться вручну виділяти передній план і налаштовувати ступінь розмиття — це займає одну-дві хвилини, навіть якщо маєш досвід, не уникнути повторних коригувань.
У Meitu XiuXiu є функція розмиття фону в один клік, але часто вона розмиває й краї людини, результат виглядає неприродно.
А в Gemini 2.5 Flash Image достатньо одного речення: модель сама визначає межі між людиною і фоном, розмиття виглядає природно, не потребує додаткового редагування.

Це порівняння показує головне: Gemini 2.5 Flash Image звільняє користувача від складних дій, перекладаючи більшу частину роботи на модель. Для звичайних людей це знижує поріг входу в редагування, для професіоналів — економить багато часу.
Після тестування я зрозумів: Gemini 2.5 Flash Image — це вже не просто інструмент для редагування, а справжній «інтелектуальний помічник».
Раніше, використовуючи Meitu XiuXiu, ми працювали з набором готових функцій: фільтри, покращення, мозаїка — кожна кнопка відповідає за певну дію. Треба було поступово обирати й налаштовувати, поки не отримаєш бажане.
Тепер же логіка Gemini 2.5 Flash Image зовсім інша: не потрібно вивчати інтерфейс — модель сама розуміє ваші потреби. Просто скажіть, і вона зробить усе за вас.
Здається, це дрібниця, але насправді це повністю змінює процес редагування: раніше ми підлаштовувалися під інструмент, тепер інструмент підлаштовується під нас. Такий спосіб взаємодії — це прототип наступного покоління застосунків.
Зараз Gemini 2.5 Flash Image ще на ранній стадії, її можливості мають межі. Але швидкість, розуміння й точність відтворення вже дають простір для фантазії щодо майбутнього.
Що буде, якщо поєднати її з Meitu XiuXiu? Можливо, ви відкриєте застосунок, скажете: «Відредагуй це фото, зроби шкіру природнішою» — і за кілька секунд отримаєте результат (UTC+8); або під час подорожі скажете: «Зроби погоду сонячною» — і фото одразу стане яскравим; навіть у відеоредакторі можна буде змінити атмосферу сцени одним реченням.

Такий підхід може швидко стати стандартною функцією редагування зображень у мобільних ОС | Джерело зображення: Twitter
Ось чому я вважаю, що ця модель швидко змінить існуючі процеси редагування й визначить нове покоління «Meitu XiuXiu»: це вже не просто редагування, а новий спосіб взаємодії з зображеннями, де AI стає вашим партнером у постобробці фото.
Однак наразі Gemini 2.5 Flash Image ще не може стати масовим P-інструментом «з коробки»: її основна мета — генерація зображень, а не дрібне редагування, і всі створені чи відредаговані зображення містять цифровий водяний знак SynthID для ідентифікації AI-контенту на соціальних платформах.
03 Точка вибухового зростання
Згадайте, чому Meitu XiuXiu колись стала масовим застосунком: вона найпростішим способом вирішила універсальну проблему — зробити фото красивішими.
Gemini 2.5 Flash Image йде ще далі: складні AI-можливості перетворюються на досвід «миттєвого результату», доступний кожному.
Коли я вперше сказав їй: «розмий фон», і вже за кілька секунд отримав природно оброблене зображення, я зрозумів: це і є точка вибухового зростання хітового застосунку. Це не просто модель, а фундамент для безлічі майбутніх продуктів.
AI-функція «заміни неба» кілька років тому стала хітом серед користувачів смартфонів | Джерело зображення: спільнота vivo
Можливо, через кілька років ми забудемо кодову назву Banana, але побачимо дедалі більше інструментів для обробки зображень, які дозволяють «просто сказати — і миттєво отримати результат». Вони, як і Meitu XiuXiu свого часу, стануть спільною пам’яттю цілого покоління користувачів.
Тільки цього разу AI розширить межі нашої уяви ще далі.
Відмова від відповідальності: зміст цієї статті відображає виключно думку автора і не представляє платформу в будь-якій якості. Ця стаття не повинна бути орієнтиром під час прийняття інвестиційних рішень.
Вас також може зацікавити
Не дайте себе обдурити відскоком! Bitcoin у будь-який момент може вдруге протестувати підтримку | Спеціальний аналіз
Аналітик Conaldo, використовуючи кількісну торгову модель, проаналізував минулотижневу динаміку bitcoin і успішно здійсни�в дві короткострокові операції з сумарним прибутком 6,93%. На цей тиждень він прогнозує коливання bitcoin у визначеному діапазоні та розробив відповідну торгову стратегію. Короткий зміст згенеровано Mars AI. Модель Mars AI знаходиться на етапі оновлення, тому точність і повнота змісту можуть змінюватися.

Співзасновник Espresso: десять років у криптоіндустрії — я хотів змінити вади Уолл-стріт, але став свідком перетворення на казино
Усе, чого ти чекав, можливо, вже прийшло, просто виглядає це інакше, ніж ти уявляв.

Ethereum спалив $18B, але його пропозиція продовжує зростати

Біткоїн-компанії стикаються з ефектом бумеранга через надмірне використання кредитного плеча
