
Issiq mavzularda! Meituan katta modeli "tezlik" bilan mashhur bo‘ldi

Ichki va xorijiy dasturchilar: O‘zimiz sinab ko‘rdik, Meituan yangi ochiq manbali modeli juda tez ishlaydi!
AI haqiqatan ham suv va elektr kabi keng tarqalgan bo‘lib qolgach, modelning kuchliligi endi yagona muhim masala emas.
Yil boshidan beri Claude 3.7 Sonnet, Gemini 2.5 Flash va yaqinda GPT-5, DeepSeek V3.1 kabi ilg‘or model ishlab chiqaruvchilari barchasi bir savol ustida bosh qotirmoqda: aniqlikni ta’minlagan holda, AI har bir muammoni eng kam hisoblash quvvati bilan qanday hal qilishi va eng qisqa vaqtda javob bera olishi mumkin? Boshqacha aytganda, tokenlarni ham, vaqtni ham isrof qilmaslik qanday amalga oshiriladi?
Model asosida ilovalar yaratadigan korxonalar va dasturchilar uchun bu “eng kuchli model qurishdan ko‘ra amaliy va tezkor model qurish”ga o‘tish yaxshi yangilikdir. Bundan ham quvonarlisi, bu yo‘nalishda ochiq manbali modellar ham tobora ko‘paymoqda.
Birinchi kunlarda biz HuggingFace’da yangi modelni topdik — LongCat-Flash-Chat.

Ushbu model Meituan’ning LongCat-Flash seriyasidan bo‘lib, rasmiy sayt orqali bevosita foydalanish mumkin.
U “not all tokens are equal” tamoyilini tabiiy ravishda biladi, shuning uchun muhim tokenlarga dinamik hisoblash byudjetini ajratadi. Shu sababli, u faqat oz sonli parametrlarni faollashtirgan holda ham, hozirgi ochiq manbali ilg‘or modellar bilan teng natija bera oladi.

LongCat-Flash ochiq manbaga chiqqach, trendga aylandi.
Shu bilan birga, bu modelning tezligi ham ko‘pchilikda chuqur taassurot qoldirdi — H800 grafik kartasida inference tezligi har soniyada 100 tokendan oshadi. Ichki va xorijiy dasturchilarning amaliy sinovlari ham buni tasdiqladi — kimdir 95 tokens/s tezlikka erishdi, kimdir esa eng qisqa vaqtda Claude bilan teng natijani oldi.
Rasm manbasi: Zhihu foydalanuvchisi @Xiaoxiaojiang.
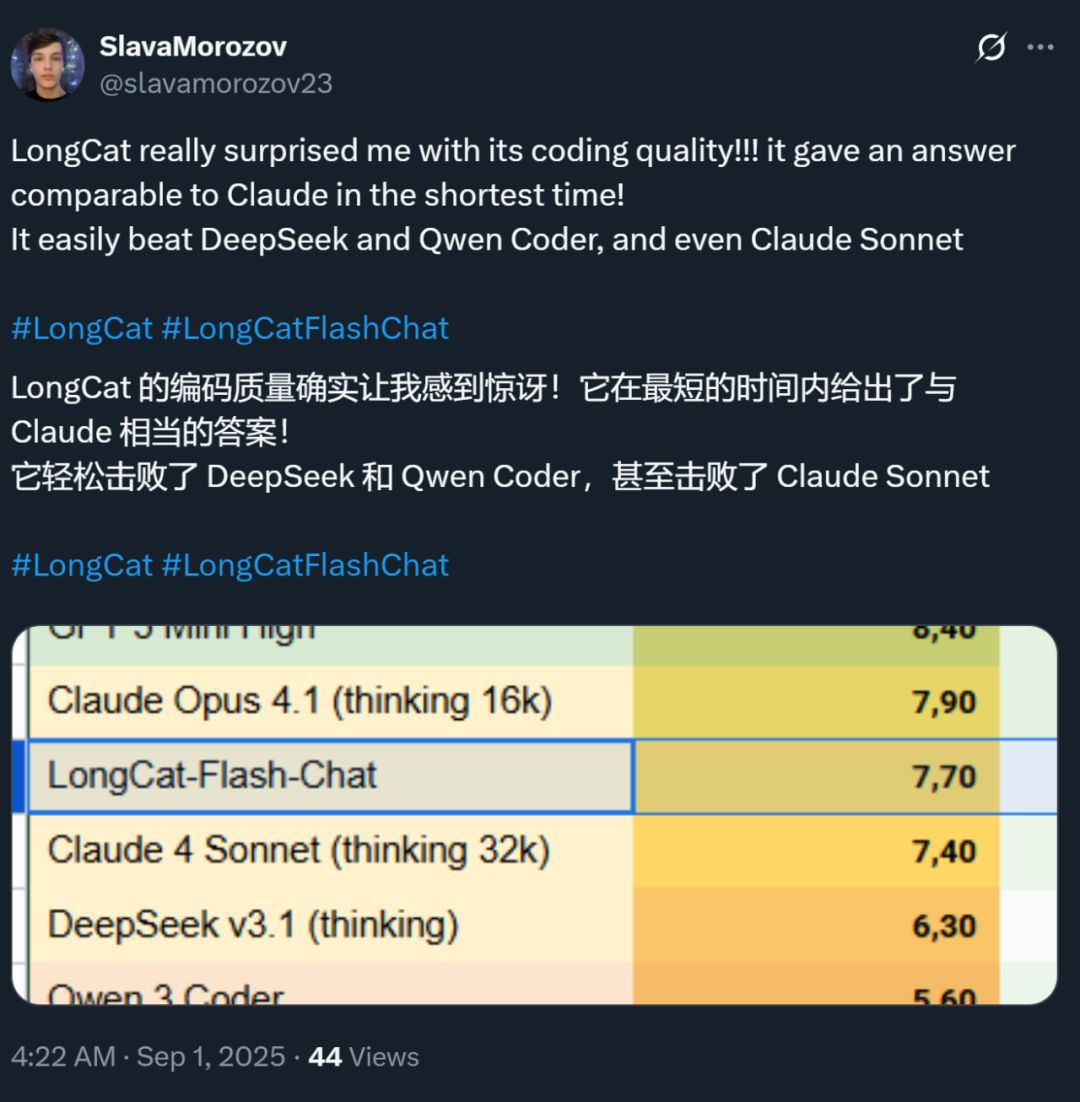
Rasm manbasi: X foydalanuvchisi @SlavaMorozov.
Ochiq manbali model bilan birga, Meituan LongCat-Flash texnik hisobotini ham chiqardi, unda ko‘plab texnik tafsilotlarni ko‘rish mumkin.

Texnik hisobot: LongCat-Flash Technical Report
Ushbu maqolada biz batafsil tanishtiramiz.
Katta model qanday qilib hisoblash quvvatini tejaydi?
LongCat-Flash’ning arxitektura innovatsiyasi va o‘qitish usullariga qarang
LongCat-Flash — bu gibrid ekspert modeli bo‘lib, umumiy parametrlari 560 billions ni tashkil etadi va kontekst ehtiyojiga qarab 18.6 billions dan 31.3 billions (o‘rtacha 27 billions) parametrlarni faollashtira oladi.
Modelni o‘qitish uchun ishlatilgan ma’lumotlar hajmi 20 trillion token’dan oshadi, lekin o‘qitish vaqti 30 kundan kam bo‘lgan. Shu vaqt ichida tizim 98.48% vaqt ishlash ko‘rsatkichiga erishdi va deyarli inson aralashuvisiz nosozliklarni bartaraf etdi — bu butun o‘qitish jarayoni asosan “inson aralashuvisiz” avtomatik amalga oshirilganini anglatadi.
Yana bir taassurotli jihati shundaki, bunday o‘qitilgan model real joylashtirishda ham a’lo natija ko‘rsatadi.
Quyidagi rasmda ko‘rsatilganidek, fikrlashsiz model sifatida LongCat-Flash SOTA fikrlashsiz modellar bilan teng natijaga erishdi, jumladan DeepSeek-V3.1 va Kimi-K2, shu bilan birga kamroq parametr va tezroq inference tezligiga ega. Bu uni umumiy, dasturlash, agent vositalaridan foydalanish kabi yo‘nalishlarda raqobatbardosh va amaliy qiladi.
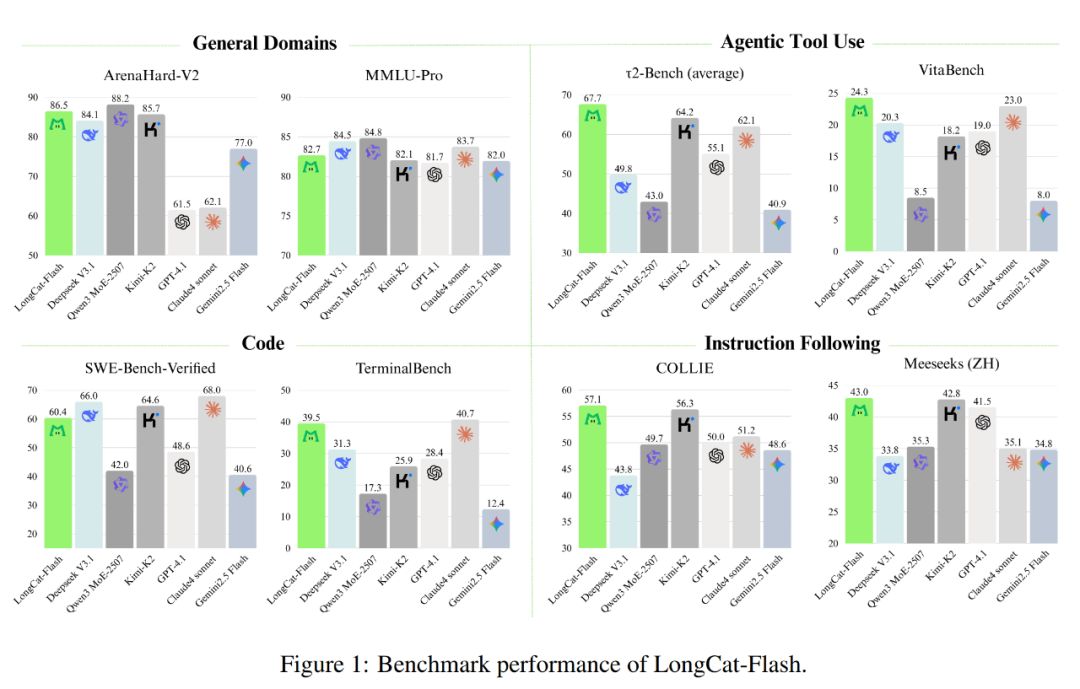
Bundan tashqari, uning narxi ham juda jozibali, faqat har million chiqish token uchun 0.7 dollar. Bu narx bozoridagi shu o‘lchamdagi modellar bilan solishtirganda juda arzon hisoblanadi.
Texnik nuqtai nazardan, LongCat-Flash til modellari uchun ikki asosiy maqsadga yo‘naltirilgan: hisoblash samaradorligi va agent qobiliyati, va arxitektura innovatsiyasi hamda ko‘p bosqichli o‘qitish usullarini birlashtirib, kengaytiriladigan va aqlli model tizimini yaratdi.
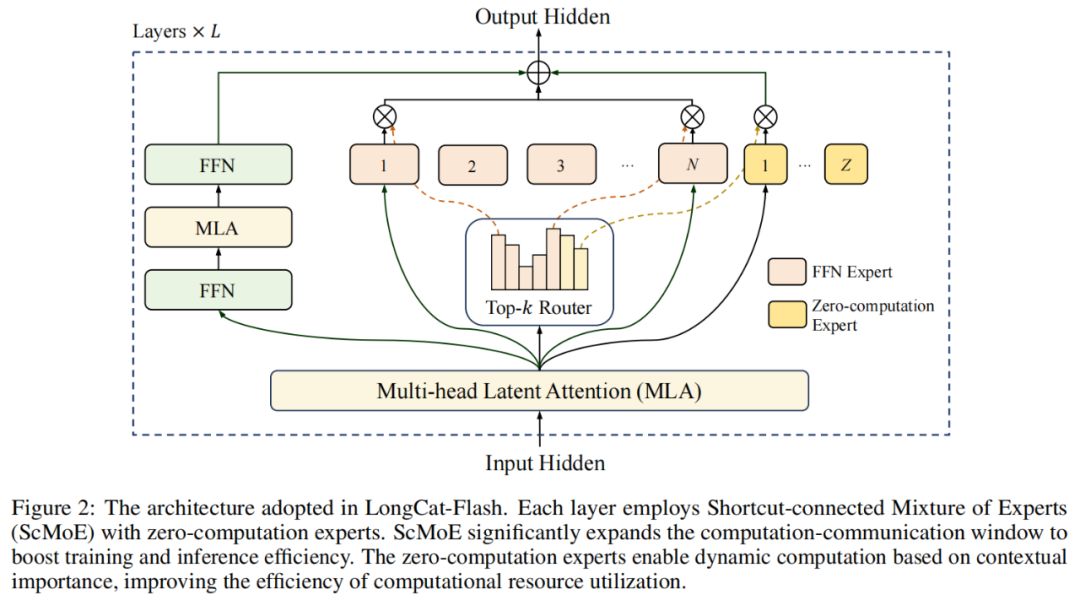
Model arxitekturasi bo‘yicha, LongCat-Flash yangi MoE arxitekturasini (2-rasm) qabul qilgan, uning asosiy jihatlari quyidagilar:
Zero-computation Experts (Nol hisoblash ekspertlari);
Shortcut-connected MoE (ScMoE).
Nol hisoblash ekspertlari
Nol hisoblash ekspertlarining asosiy g‘oyasi — barcha tokenlar “teng” emas.
Buni shunday tushunish mumkin: gapda ba’zi so‘zlarni oldindan aytish juda oson, masalan, “ning”, “bu” — deyarli hisoblash talab qilmaydi, lekin ba’zi so‘zlar, masalan, “ism” aniq aytish uchun ko‘p hisoblash talab qiladi.
Oldingi tadqiqotlarda, odatda quyidagicha qilinardi: token oddiy yoki murakkab bo‘lishidan qat’i nazar, u har doim belgilangan miqdordagi (K) ekspertlarni faollashtiradi, bu esa katta hisoblash isrofini keltirib chiqaradi. Oddiy token uchun bunchalik ko‘p ekspert chaqirish shart emas, murakkab token uchun esa yetarli hisoblash ajratilmasligi mumkin.
Shundan ilhomlanib, LongCat-Flash dinamik hisoblash resurslarini taqsimlash mexanizmini taklif qildi: nol hisoblash ekspertlari orqali har bir token uchun turli miqdordagi FFN (Feed-Forward Network) ekspertlarini dinamik faollashtirib, kontekst muhimligiga qarab hisoblash hajmini oqilona taqsimlaydi.
Aniq aytganda, LongCat-Flash ekspertlar havzasida, asl N ta standart FFN ekspertlaridan tashqari, Z ta nol hisoblash ekspertlarini ham kengaytirdi. Nol hisoblash ekspertlari kirishni o‘z holicha chiqish sifatida qaytaradi, shuning uchun qo‘shimcha hisoblash yukini keltirib chiqarmaydi.
LongCat-Flash’dagi MoE modulini quyidagicha ifodalash mumkin:
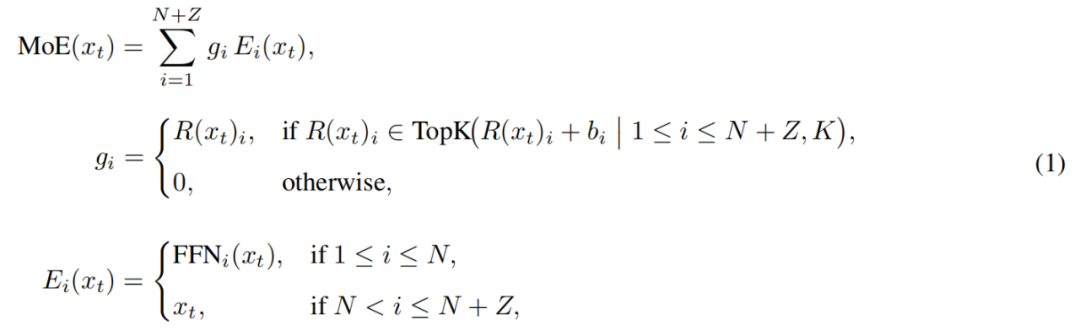
Bu yerda x_t — kirish ketma-ketligidagi t-token, R — softmax router, b_i — i-ekspertga mos keluvchi bias, K — har bir token tanlaydigan ekspertlar soni. Router har bir tokenni K ta ekspertga taqsimlaydi, faollashtirilgan FFN ekspertlar soni token kontekst muhimligiga qarab o‘zgaradi. Bu moslashuvchan taqsimlash orqali model kontekstda muhim tokenlarga ko‘proq hisoblash resursini dinamik ajratishni o‘rganadi va shu bilan bir xil hisoblash hajmida yaxshiroq natijaga erishadi (3a-rasm).
Bundan tashqari, model kirishni qayta ishlashda har bir token muhimligiga qarab ko‘proq hisoblash resursi ajratish-ajrata olmaslikni o‘rganishi kerak. Agar nol hisoblash ekspertlari tanlanish chastotasini nazorat qilmasa, model hisoblashli ekspertlarni tanlashga moyil bo‘lib, nol hisoblash ekspertlari rolini e’tiborsiz qoldiradi. Bu esa hisoblash resurslarining samaradorligini pasaytiradi.
Bu muammoni hal qilish uchun, Meituan aux-loss-free strategiyasidagi ekspert bias mexanizmini takomillashtirdi: ekspertga xos bias kiritildi, bu bias so‘nggi ekspert ishlatilishiga qarab router ballini dinamik sozlaydi va til modelining o‘qitish maqsadidan ajratilgan.
Yangi qoidalar nazorat nazariyasidagi PID controller yordamida ekspert biasini real vaqtda sozlaydi. Shu tufayli, model har bir tokenni qayta ishlashda faqat 18.6 billions dan 31.3 billions (o‘rtacha 27 billions atrofida) parametrlarni faollashtiradi va resurslarni optimallashtiradi.
Shortcut-connected MoE
LongCat-Flash’ning yana bir muhim jihati — shortcut-connected MoE mexanizmi.
Odatda, yirik MoE modellarining samaradorligi ko‘p jihatdan aloqa xarajatlari bilan cheklanadi. An’anaviy bajarish usulida, ekspertlar parallel ishlaganda, tokenlarni kerakli ekspertga yo‘naltirish uchun avval global aloqa amalga oshiriladi, so‘ngra hisoblash boshlanadi.
Bu “avval aloqa, so‘ng hisoblash” tartibi ortiqcha kutish vaqtini keltirib chiqaradi, ayniqsa yirik taqsimlangan o‘qitishda aloqa kechikishi sezilarli darajada oshadi va samaradorlikka to‘sqinlik qiladi.
Oldingi tadqiqotlarda umumiy ekspert arxitekturasi yordamida aloqa va bitta ekspert hisoblashini birga bajarishga harakat qilindi, lekin bu samaradorlik bitta ekspert hisoblash oynasining kichikligi bilan cheklanadi.
Meituan ScMoE arxitekturasini joriy etib, bu cheklovni yengib o‘tdi. ScMoE qatlamlar orasida shortcut ulanishini kiritdi, bu esa oldingi qatlamdagi zich FFN hisoblashini hozirgi MoE qatlamidagi dispatch/aggregate aloqa bilan parallel bajarishga imkon beradi va umumiy ekspert arxitekturasiga qaraganda kattaroq aloqa-hisoblash oyna hosil qiladi.
Bu arxitektura dizayni bir nechta tajribalarda tasdiqlangan.
Birinchidan, ScMoE dizayni model sifatini pasaytirmaydi. 4-rasmda ko‘rsatilganidek, ScMoE arxitekturasi va ScMoE’siz bazis model o‘qitish yo‘qotish egri chizig‘ida deyarli bir xil natija ko‘rsatdi, bu esa bajarish tartibini o‘zgartirish model sifatiga zarar yetkazmasligini isbotlaydi. Bu xulosa turli konfiguratsiyalarda ham tasdiqlangan.
Yana muhim jihati, bu natijalar shuni ko‘rsatadiki: ScMoE barqarorligi va samaradorlik ustunligi, e’tibor mexanizmi tanlovidan mustaqil (ya’ni qaysi e’tibor mexanizmi ishlatilishidan qat’i nazar, barqarorlik va foyda saqlanadi).
Ikkinchidan, ScMoE arxitekturasi o‘qitish va inference uchun ko‘plab tizim darajasidagi samaradorlikni ta’minlaydi. Xususan:
Katta hajmdagi o‘qitishda: kengaytirilgan overlap oyna oldingi blok hisoblashini MoE qatlamidagi dispatch va aggregate aloqa bosqichlari bilan to‘liq parallel bajarishga imkon beradi, bu token o‘lchami bo‘yicha operatsiyalarni mayda bloklarga bo‘lish orqali amalga oshiriladi.
Samarali inference’da: ScMoE bitta batch overlap pipeline’ni qo‘llab-quvvatlaydi, DeepSeek-V3 kabi ilg‘or modellar bilan solishtirganda, nazariy har soniyada chiqish token vaqti (TPOT) ni deyarli 50% ga qisqartiradi. Bundan ham muhimi, u turli aloqa rejimlarining parallel bajarilishini ta’minlaydi: zich FFN’dagi ichki tugun tensor parallel aloqasi (NVLink orqali) va tugunlararo ekspert parallel aloqasi (RDMA orqali) to‘liq overlap qilinadi va umumiy tarmoqdan maksimal foydalanish ta’minlanadi.
Xulosa qilib aytganda, ScMoE model sifatini qurbon qilmasdan katta samaradorlikni ta’minlaydi.
Model kengaytirish strategiyasi va ko‘p bosqichli o‘qitish
Meituan samarali model kengaytirish strategiyasini ham taklif qildi, bu model hajmi oshganda natijani sezilarli yaxshilaydi.
Birinchidan, giperparametrlarni ko‘chirish: juda yirik modelni o‘qitishda turli giperparametrlarni to‘g‘ridan-to‘g‘ri sinash qimmat va beqaror. Shuning uchun Meituan avval kichik modelda tajriba o‘tkazib, eng yaxshi giperparametrlarni topdi, so‘ngra ularni katta modelga ko‘chirdi. Bu xarajatni tejadi va natijani kafolatlaydi. Ko‘chirish qoidalari 1-jadvalda ko‘rsatilgan:
Ikkinchidan, model o‘sishi (Model Growth) initsializatsiyasi: Meituan avval yuz billion tokenlarda oldindan o‘qitilgan yarim o‘lchamdagi modeldan boshladi, o‘qitib, checkpointni saqlab qoldi. Shundan so‘ng modelni to‘liq o‘lchamga kengaytirib, o‘qitishni davom ettirdi.
Bu usul asosida model odatiy yo‘qotish egri chizig‘ini ko‘rsatdi: yo‘qotish qisqa muddatda oshib, tezda konvergentsiyalashdi va nihoyat tasodifiy initsializatsiyadan ancha yaxshi natija berdi. 5b-rasmda 6B faollashtirilgan parametrlar tajribasining tipik natijasi ko‘rsatilgan, bu model o‘sishi initsializatsiyasining ustunligini ko‘rsatadi.
Uchinchidan, ko‘p darajali barqarorlik to‘plami: Meituan router barqarorligi, faollashtirish barqarorligi va optimizer barqarorligi orqali LongCat-Flash o‘qitish barqarorligini kuchaytirdi.
To‘rtinchidan, deterministik hisoblash: bu usul tajriba natijalarining to‘liq takrorlanishini kafolatlaydi va o‘qitish jarayonida Silent Data Corruption (SDC) ni aniqlash imkonini beradi.
Ushbu choralar orqali LongCat-Flash o‘qitish jarayoni doimo yuqori barqarorlikda bo‘lib, tiklanmaydigan loss spike holatlari yuzaga kelmaydi.
O‘qitish barqarorligini saqlagan holda, Meituan LongCat-Flash’ga ilg‘or agent xatti-harakatlarini beruvchi o‘qitish pipeline’ini puxta loyihaladi, bu jarayon keng ko‘lamli oldindan o‘qitish, inference va kod qobiliyatiga yo‘naltirilgan o‘rta bosqichli o‘qitish, hamda dialog va vosita ishlatishga qaratilgan keyingi o‘qitishni o‘z ichiga oladi.
Boshlang‘ich bosqichda, agent uchun mos asosiy model qurildi, buning uchun Meituan ikki bosqichli oldindan o‘qitish ma’lumotlarini birlashtirish strategiyasini ishlab chiqdi va inference-intensiv sohalarga e’tibor qaratdi.
O‘qitish o‘rtasida, Meituan modelning inference va kod qobiliyatini yanada kuchaytirdi; kontekst uzunligini 128k gacha kengaytirdi, bu agent uchun keyingi o‘qitish ehtiyojini qondiradi.
Oxirida, Meituan ko‘p bosqichli keyingi o‘qitishni amalga oshirdi. Agent sohasida yuqori sifatli va murakkab o‘qitish ma’lumotlari kamligi sababli, Meituan ko‘p agentli sintetik ramkani ishlab chiqdi: bu ramka uchta o‘lchamda vazifa murakkabligini belgilaydi — ma’lumotlarni qayta ishlash, vosita to‘plami murakkabligi va foydalanuvchi bilan o‘zaro aloqada bo‘lish, maxsus controller yordamida iterativ inference va muhit bilan o‘zaro aloqani talab qiluvchi murakkab vazifalarni yaratadi.
Bu dizayn vosita chaqirish va muhit bilan o‘zaro aloqani talab qiluvchi murakkab vazifalarni bajarishda modelni juda samarali qiladi.
Tez va arzon ishlash
LongCat-Flash buni qanday amalga oshirdi?
Yuqorida aytilganidek, LongCat-Flash H800 grafik kartasida har soniyada 100 token’dan ortiq inference tezligiga ega va har million chiqish token uchun atigi 0.7 dollar turadi — ya’ni tez va arzon ishlaydi.
Buni qanday amalga oshirdi? Birinchidan, ular model arxitekturasi bilan uyg‘unlashtirilgan parallel inference arxitekturasiga ega; ikkinchidan, ular kvantlash va maxsus yadro kabi optimallashtirish usullarini qo‘shgan.
Maxsus optimallashtirish: model “o‘zi yaxshi ishlasin”
Ma’lumki, samarali inference tizimi qurish uchun ikki asosiy muammoni hal qilish kerak: hisoblash va aloqa muvofiqligi, hamda KV keshini o‘qish-yozish va saqlash.
Birinchi muammo uchun, mavjud usullar odatda uchta an’anaviy darajada parallelizmni qo‘llaydi: operator darajasida overlap, ekspert darajasida overlap va qatlam darajasida overlap. LongCat-Flash’ning ScMoE arxitekturasi to‘rtinchi o‘lcham — modul darajasida overlapni kiritdi. Shu maqsadda, jamoa SBO (Single Batch Overlap) scheduling strategiyasini ishlab chiqdi va kechikish va throughput’ni optimallashtirdi.
SBO — bu to‘rt bosqichli pipeline bajarish usuli bo‘lib, modul darajasida overlap orqali LongCat-Flash’ning imkoniyatlarini to‘liq namoyon qiladi (9-rasm). SBO va TBO farqi shundaki, SBO aloqa xarajatini bitta batch ichida yashiradi. Birinchi bosqichda MLA hisoblash bajariladi va keyingi bosqichlarga kirish ta’minlanadi; ikkinchi bosqichda Dense FFN va Attn 0 (QKV proyeksiya) all-to-all dispatch aloqa bilan overlap qilinadi; uchinchi bosqichda MoE GEMM mustaqil bajariladi va keng EP joylashtirish strategiyasi tufayli kechikish kamayadi; to‘rtinchi bosqichda Attn 1 (asosiy e’tibor va chiqish proyeksiyasi) va Dense FFN all-to-all combine bilan overlap qilinadi. Bu dizayn aloqa xarajatini samarali kamaytiradi va LongCat-Flash inference samaradorligini ta’minlaydi.
Ikkinchi muammo — KV keshini o‘qish-yozish va saqlash — LongCat-Flash e’tibor mexanizmi va MTP arxitektura innovatsiyasi orqali hal qilinadi va samarali I/O xarajatini kamaytiradi.
Birinchidan, spekulyativ dekodlash tezlashtirilgan. LongCat-Flash MTP’ni draft model sifatida ishlatadi va tizimli tahlil orqali spekulyativ dekodlash tezlashtirish formulasini optimallashtiradi: kutilgan qabul uzunligi, draft va target model xarajat nisbati, target verification va decoding xarajat nisbati. Bitta MTP head integratsiyasi va oldindan o‘qitish oxirida kiritilishi orqali taxminan 90% qabul qilish darajasiga erishildi. Draft sifat va tezlik muvozanatini saqlash uchun yengil MTP arxitekturasi parametrlarni kamaytiradi, C2T usuli esa tasdiqlanish ehtimoli past tokenlarni klassifikatsion model orqali filtrlash uchun ishlatiladi.
Ikkinchidan, KV kesh optimallashtirilgan, bu MLA’ning 64 head e’tibor mexanizmi orqali amalga oshiriladi. MLA samaradorlik va natija muvozanatini saqlagan holda hisoblash yukini sezilarli kamaytiradi va KV keshni siqishni ta’minlaydi, bu esa saqlash va tarmoq bosimini pasaytiradi. Bu LongCat-Flash pipeline’ini muvofiqlashtirish uchun muhim, chunki modelda har doim aloqa bilan overlap qilinmaydigan e’tibor hisoblash mavjud.
Tizim darajasidagi optimallashtirish: apparat “jamoaviy ishlasin”
Scheduling xarajatini minimallashtirish uchun, LongCat-Flash tadqiqot guruhi LLM inference tizimida yadro ishga tushirish xarajatidan kelib chiqadigan launch-bound muammosini hal qildi. Ayniqsa, spekulyativ dekodlash joriy qilingach, verification yadro va draft forward scheduling mustaqil bo‘lib, sezilarli xarajat keltiradi. TVD birlashtirish strategiyasi orqali ular target forward, verification va draft forward’ni bitta CUDA grafikasi ichida birlashtirdi. GPU’dan maksimal foydalanish uchun overlap scheduler ishlab chiqildi va ko‘p bosqichli overlap scheduler bitta scheduling iteratsiyasida bir nechta forward bosqich yadro ishga tushuradi va CPU scheduling va sinxronizatsiya xarajatini yashiradi.
Maxsus yadro optimallashtirish LLM inference’ning autoregressive xususiyatidan kelib chiqadigan samaradorlik muammolariga qaratilgan. Prefill bosqichi hisoblashga boy, dekodlash bosqichi esa oqim rejimi tufayli kichik va notekis batch o‘lchamiga ega va ko‘pincha xotira bilan cheklanadi. MoE GEMM uchun SwapAB texnologiyasi ishlatiladi, bunda og‘irlik chap matritsa, faollashtirish o‘ng matritsa sifatida qaraladi va n o‘lchamli 8 elementli granularlik yordamida tensor yadrodan maksimal foydalaniladi. Aloqa yadro NVLink Sharp apparat tezlashtirilgan broadcast va in-switch reduction’dan foydalanadi va faqat 4 thread block yordamida 4KB dan 96MB gacha xabar o‘lchamida NCCL va MSCCL++’dan doimiy ustunlikka ega.
Kvantlash bo‘yicha, LongCat-Flash DeepSeek-V3 bilan bir xil nozik blok darajasidagi kvantlash sxemasini qabul qilgan. Eng yaxshi natija-aniqlik muvozanatini ta’minlash uchun, ikki sxema asosida qatlamli aralash aniqlik kvantlash amalga oshiriladi: birinchi sxema ayrim lineer qatlamlarda (ayniqsa Downproj) kirish faollashtirish 10^6 gacha bo‘lgan ekstremal amplitudaga ega ekanini aniqlaydi; ikkinchi sxema qatlamma-qatlam blok darajasida FP8 kvantlash xatosini hisoblaydi va ayrim ekspert qatlamlarda sezilarli kvantlash xatosi borligini aniqlaydi. Ikkala sxema kesishmasi orqali aniqlik sezilarli oshiriladi.
Amaliy ma’lumotlar: Qancha tez va arzon ishlaydi?
Amaliy natijalar shuni ko‘rsatadiki, LongCat-Flash turli sozlamalarda a’lo natija beradi. DeepSeek-V3 bilan solishtirganda, o‘xshash kontekst uzunligida LongCat-Flash ko‘proq generatsiya throughput va tezroq generatsiya tezligiga erishadi.
Agent ilovalarida, inference mazmuni (foydalanuvchiga ko‘rinadi, inson o‘qish tezligi taxminan 20 tokens/s) va harakat buyruqlari (foydalanuvchiga ko‘rinmaydi, lekin vosita chaqirish vaqtiga bevosita ta’sir qiladi, maksimal tezlik talab qilinadi) farqlanadi, LongCat-Flash’ning 100 tokens/s ga yaqin generatsiya tezligi bitta vosita chaqirish kechikishini 1 soniyadan kamda ushlab turadi va Agent ilovalari interaktivligini sezilarli oshiradi. H800 GPU har soat 2 dollar narxida, bu har million chiqish token uchun 0.7 dollar degani.
Teoretik natijalar shuni ko‘rsatadiki, LongCat-Flash kechikishi uchta komponent bilan belgilanadi: MLA, all-to-all dispatch/combine va MoE. EP=128, har karta batch=96, MTP qabul darajasi ≈80% bo‘lsa, LongCat-Flash nazariy TPOT limiti 16ms, DeepSeek-V3’ning 30ms va Qwen3-235B-A22B’ning 26.2ms ga nisbatan ancha ustun. H800 GPU har soat 2 dollar narxida, LongCat-Flash chiqish narxi har million token uchun 0.09 dollar, DeepSeek-V3’ning 0.17 dollaridan ancha past. Biroq, bu qiymatlar faqat nazariy limitlar.
LongCat-Flash’ning bepul tajriba sahifasida biz ham sinovdan o‘tkazdik.
Avval bu katta modeldan kuz fasli haqida 1000 so‘zli maqola yozishni so‘radik.
So‘rov yuborishimiz bilan, yozuvni boshlashimiz bilan, LongCat-Flash javobni yozib bo‘ldi, yozuvni birinchi daqiqada to‘xtatishga ham ulgurmadik.
Yaqindan qarasangiz, LongCat-Flash birinchi token chiqish tezligi juda yuqori. Oldingi dialog modellaridan foydalanganda ko‘pincha aylanish belgisi chiqib, kutishga majbur bo‘lar edik, bu esa foydalanuvchi sabrini sinaydi — xuddi WeChat xabarini kutayotganingizda “Qabul qilinmoqda” degan yozuv chiqib turgandek. LongCat-Flash bu bosqichdagi tajribani o‘zgartirdi, birinchi token kechikishini deyarli sezmay qolasiz.
Keyingi tokenlar generatsiya tezligi ham juda yuqori, inson ko‘zi o‘qish tezligidan ancha yuqori.
Keyin “onlayn qidiruv” funksiyasini yoqib, LongCat-Flash bu imkoniyati tezmi-yo‘qmi sinab ko‘rdik. LongCat-Flash’dan Wangjing atrofida mazali restoranlarni tavsiya qilishni so‘radik.
Sinov natijasida aniq sezildi: LongCat-Flash uzoq o‘ylab javob bermaydi, deyarli darhol javob beradi. Onlayn qidiruv ham “tez” degan taassurot qoldiradi. Bundan tashqari, tez javob berish bilan birga, manba havolasini ham keltiradi, bu esa ma’lumot ishonchliligi va izchilligini kafolatlaydi.
Modelni yuklab olish imkoniyati bo‘lgan o‘quvchilar o‘z kompyuterida LongCat-Flash tezligini sinab ko‘rishi mumkin.
Katta model amaliy davrga kirganda
So‘nggi yillarda har safar yangi katta model chiqqanda, hamma quyidagilarni so‘rardi: benchmark natijasi qancha? Qancha reyting yangilandi? SOTA’mi? Endi esa vaziyat o‘zgardi. Qobiliyatlar deyarli bir xil bo‘lsa, hamma ko‘proq quyidagilarni so‘raydi: bu modeldan foydalanish qimmatmi? Tezligi qanday? Ochiq manbali modeldan foydalanadigan korxona va dasturchilar orasida bu holat ayniqsa yaqqol. Chunki ko‘plab foydalanuvchilar ochiq manbali modeldan foydalanib, yopiq API’ga bo‘lgan qaramlik va xarajatni kamaytirishni xohlaydi, shuning uchun hisoblash quvvati, inference tezligi va kvantlash samaradorligiga juda sezgir.
Meituan ochiq manbali LongCat-Flash aynan shu tendensiyaga javob beradi. Ular e’tiborni katta modelni haqiqatan ham arzon va tez ishlashiga qaratdi, bu esa texnologiyani ommalashtirish uchun muhimdir.
Bu amaliy yo‘nalishni tanlash Meituan haqidagi doimiy taassurotimizga mos keladi. O‘tmishda ular texnologiyaga kiritgan sarmoyaning aksariyatini haqiqiy biznes muammolarini hal qilishga sarflagan, masalan, 2022 yilda ICRA eng yaxshi navigatsiya maqolasini olgan EDPLVO, aslida dron yetkazib berishda yuzaga keladigan muammolarni (masalan, binolar zichligi sababli signal yo‘qolishi) hal qilish uchun ishlab chiqilgan; yaqinda ishlab chiqilgan global dron to‘qnashuvdan qochish ISO standarti esa dronlar uchish paytida kite ipi, oynani artish simi kabi xavfsizlik holatlarini texnik tajriba sifatida jamlagan. Bu safar ochiq manbali LongCat-Flash esa ularning AI dasturlash vositasi “NoCode” ortidagi model bo‘lib, bu vosita kompaniya ichida ham, tashqarida ham bepul taqdim etiladi, maqsad esa vibe coding’dan foydalanishni kengaytirish va xarajatni kamaytirish, samaradorlikni oshirishdir.
Bu natija-yo‘nalishli yondashuvga o‘tish AI sohasidagi rivojlanishning tabiiy qonuniyatini aks ettiradi. Model qobiliyati asta-sekin tenglashganda, muhandislik samaradorligi va joylashtirish xarajati asosiy farqlovchi omilga aylanadi. LongCat-Flash’ning ochiq manbaga chiqishi bu tendensiyadagi bir misol, lekin u jamiyatga texnik yo‘l ko‘rsatadi: model sifatini saqlagan holda, arxitektura innovatsiyasi va tizim optimallashtirish orqali foydalanish to‘siqlarini qanday kamaytirish mumkin. Bu esa byudjeti cheklangan, lekin ilg‘or AI imkoniyatlaridan foydalanmoqchi bo‘lgan dasturchilar va korxonalar uchun, shubhasiz, juda foydalidir.
Mas'uliyatni rad etish: Ushbu maqolaning mazmuni faqat muallifning fikrini aks ettiradi va platformani hech qanday sifatda ifodalamaydi. Ushbu maqola investitsiya qarorlarini qabul qilish uchun ma'lumotnoma sifatida xizmat qilish uchun mo'ljallanmagan.
Sizga ham yoqishi mumkin
Kripto sohasida qancha daromad qilsa, "taqdirni o'zgartirdim" deyishga arziydi?
Haqiqiy xavf "yo‘qotish"da emas, balki "hech qachon g‘alaba qozonganingizni bilmaslik"dadir.

NBER | Model orqali raqamli iqtisodiyot kengayishi global moliyaviy tuzilmani qanday o‘zgartirayotganini ochib beradi
Tadqiqot natijalari shuni ko'rsatadiki, uzoq muddatda zaxira talabining ta'siri almashtirish ta'siridan ustun keladi, bu esa AQSh foiz stavkalarining pasayishiga va AQShning tashqi qarz olishining oshishiga olib keladi.

ETH sahnani egallaydi: Bozorning ikkinchi yarmidagi haqiqiy ochilish
Bozor tuzilmasi, kapital oqimi, onchain ma’lumotlari va siyosiy muhitni hisobga olgan holda, bizning fikrimiz juda aniq: Ethereum asta-sekin Bitcoin o‘rnini egallamoqda va bozorning bull trendining ikkinchi yarmida asosiy aktivga aylanmoqda.
