
De la tempête de liquidations à la panne du cloud : le moment de crise pour l’infrastructure crypto

Le 20, un problème avec AWS d'Amazon a provoqué la panne de Coinbase ainsi que de dizaines d'autres grandes plateformes de cryptomonnaies, dont Robinhood, Infura, Base et Solana.
Titre original : Crypto Infrastructure is Far From Perfect
Auteur original : YQ, KOL crypto
Traduction originale : AididiaoJP, Foresight News
Amazon Web Services a de nouveau subi une panne majeure, affectant gravement l’infrastructure crypto. Les problèmes d’AWS dans la région Est des États-Unis (centre de données de Virginie du Nord) ont provoqué la paralysie de Coinbase ainsi que de dizaines d’autres grandes plateformes crypto, dont Robinhood, Infura, Base et Solana.
AWS a reconnu une « augmentation du taux d’erreur » affectant Amazon DynamoDB et EC2, des services de base de données et de calcul essentiels sur lesquels des milliers d’entreprises s’appuient. Cette panne fournit une validation immédiate et frappante de l’argument central de cet article : la dépendance de l’infrastructure crypto envers les fournisseurs de services cloud centralisés crée des vulnérabilités systémiques qui se manifestent à plusieurs reprises sous pression.
Le timing est particulièrement révélateur. Dix jours seulement après qu’un événement de liquidation en chaîne de 1,93 milliards de dollars ait exposé des défaillances d’infrastructure au niveau des plateformes de trading, la panne d’AWS d’aujourd’hui montre que le problème dépasse le cadre d’une seule plateforme et s’étend à la couche fondamentale de l’infrastructure cloud. Lorsque AWS tombe en panne, les effets en cascade touchent simultanément les plateformes d’échange centralisées, les plateformes « décentralisées » dépendantes de services centralisés, ainsi qu’une multitude d’autres services.
Ce n’est pas un incident isolé, mais un schéma récurrent. L’analyse suivante documente des pannes similaires d’AWS survenues en avril 2025, décembre 2021 et mars 2017, chacune ayant entraîné la paralysie de services crypto majeurs. La question n’est pas de savoir si la prochaine défaillance d’infrastructure aura lieu, mais quand et quel en sera le déclencheur.
Événement de liquidation en chaîne du 10-11 octobre 2025 : étude de cas
L’événement de liquidation en chaîne du 10-11 octobre 2025 offre une étude de cas éclairante sur les schémas de défaillance d’infrastructure. À 20h00 UTC, une annonce géopolitique majeure a déclenché une vente massive sur l’ensemble du marché. En une heure, 6 milliards de dollars ont été liquidés. À l’ouverture des marchés asiatiques, 19,3 milliards de dollars de positions à effet de levier avaient disparu sur 1,6 million de comptes de traders.
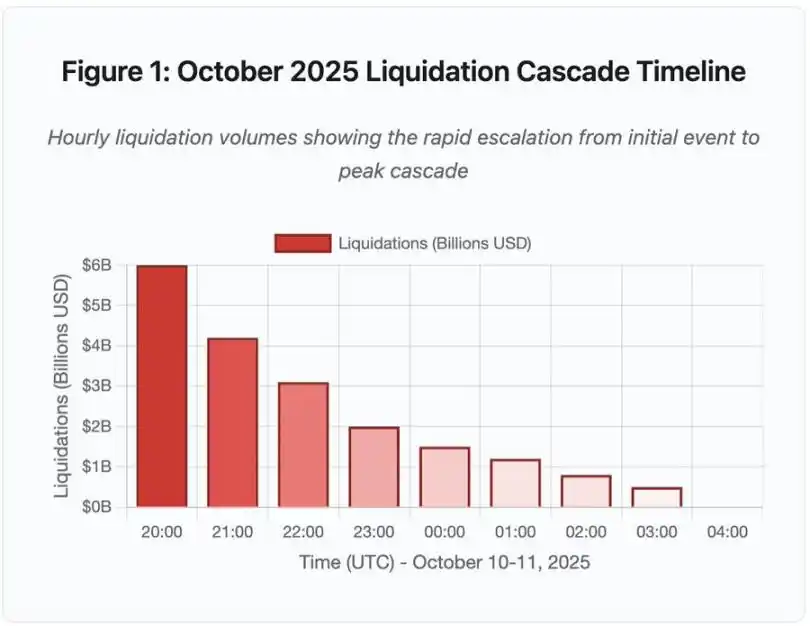
Figure 1 : Chronologie de l’événement de liquidation en chaîne d’octobre 2025
Ce graphique chronologique interactif montre l’évolution dramatique du volume de liquidations par heure. Rien que durant la première heure, 6 milliards de dollars se sont évaporés, suivis d’une accélération encore plus marquée lors de la deuxième heure. La visualisation indique :
· 20h00-21h00 : Choc initial – 6 milliards de dollars liquidés (zone rouge)
· 21h00-22h00 : Pic de la chaîne – 4,2 milliards de dollars, début de la limitation du débit API
· 22h00-04h00 : Détérioration continue – 9,1 milliards de dollars liquidés sur un marché à faible liquidité
· Point de bascule clé : limitation du débit API, retrait des market makers, carnet d’ordres qui s’amincit
L’ampleur de l’événement dépasse d’un ordre de grandeur tout ce que le marché crypto a connu auparavant, la comparaison historique mettant en évidence la nature exponentielle de cet événement :
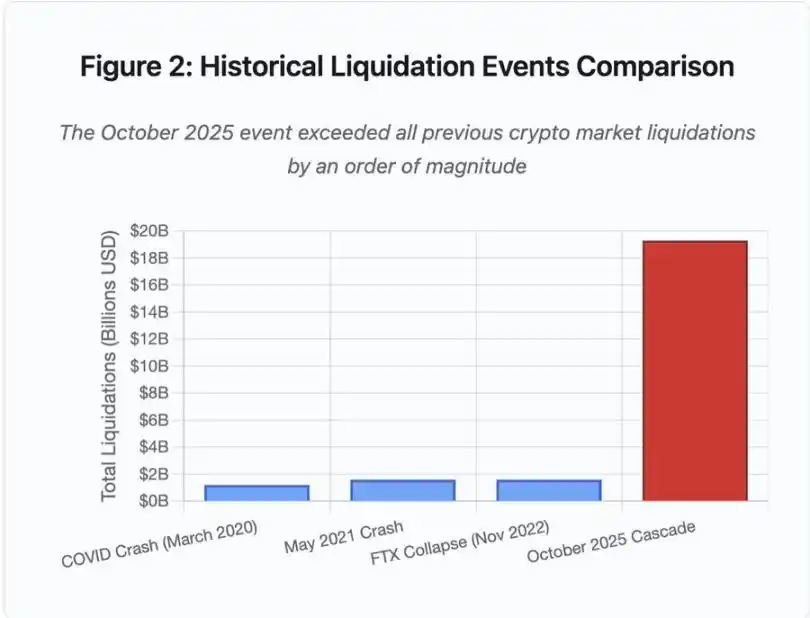
Figure 2 : Comparaison des événements historiques de liquidation
Le graphique en barres illustre de façon spectaculaire l’ampleur exceptionnelle de l’événement d’octobre 2025 :
· Mars 2020 (COVID) : 1,2 milliard de dollars
· Mai 2021 (krach) : 1,6 milliard de dollars
· Novembre 2022 (FTX) : 1,6 milliard de dollars
· Octobre 2025 : 19,3 milliards de dollars, soit 16 fois le précédent record
Mais les chiffres de liquidation ne racontent qu’une partie de l’histoire. La question la plus intéressante concerne le mécanisme : comment un événement de marché externe déclenche-t-il ce schéma particulier de défaillance ? La réponse révèle des faiblesses systémiques dans l’infrastructure des plateformes d’échange centralisées et la conception des protocoles blockchain.
Pannes hors chaîne : architecture des plateformes d’échange centralisées
Surcharge d’infrastructure et limitation du débit
Les API des plateformes d’échange mettent en œuvre des limitations de débit pour prévenir les abus et gérer la charge des serveurs. En fonctionnement normal, ces limites permettent les transactions légitimes tout en bloquant les attaques potentielles. En période de volatilité extrême, lorsque des milliers de traders tentent simultanément d’ajuster leurs positions, ces mêmes limites deviennent des goulets d’étranglement.
Les CEX limitent les notifications de liquidation à une par seconde, même lorsqu’ils traitent des milliers d’ordres par seconde. Lors de l’événement en chaîne d’octobre, cela a créé un manque de transparence. Les utilisateurs ne pouvaient pas évaluer en temps réel la gravité de la chaîne. Les outils de surveillance tiers montraient des centaines de liquidations par minute, alors que les sources officielles en affichaient beaucoup moins.
La limitation du débit API a empêché les traders de modifier leurs positions durant la première heure critique : les requêtes de connexion expiraient, les soumissions d’ordres échouaient. Les ordres stop-loss n’ont pas été exécutés, les requêtes de position renvoyaient des données obsolètes ; ce goulot d’étranglement a transformé un événement de marché en crise opérationnelle.
Les plateformes traditionnelles configurent leur infrastructure pour la charge normale plus une marge de sécurité. Mais la charge normale diffère radicalement de la charge sous stress, et le volume moyen quotidien ne prédit pas bien les pics de demande. Lors d’un événement en chaîne, le volume de transactions explose par 100 ou plus, les requêtes de données de position par 1 000, chaque utilisateur vérifiant simultanément son compte.
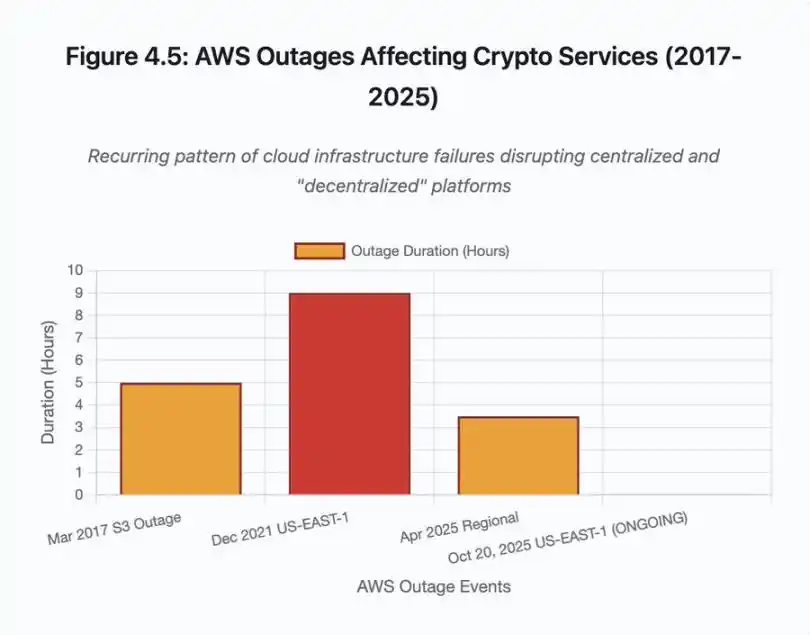
Figure 4.5 : Panne AWS affectant les services crypto
L’infrastructure cloud à mise à l’échelle automatique aide, mais ne répond pas instantanément : lancer des réplicas de base de données supplémentaires prend plusieurs minutes. Créer de nouvelles instances de passerelle API prend aussi plusieurs minutes. Pendant ce laps de temps, les systèmes de marge continuent de marquer la valeur des positions sur la base de données de prix corrompues issues de carnets d’ordres surchargés.
Manipulation d’oracle et failles de tarification
Lors de l’événement en chaîne d’octobre, un choix de conception clé dans les systèmes de marge est devenu évident : certaines plateformes calculent la valeur des collatéraux sur la base du prix du marché spot interne, plutôt que sur des flux de données d’oracle externes. En conditions normales, les arbitragistes maintiennent la cohérence des prix entre plateformes. Mais sous pression, ce couplage s’effondre.

Figure 3 : Schéma de manipulation d’oracle
Ce schéma interactif visualise cinq étapes de vecteur d’attaque :
· Vente initiale : pression de vente de 60 millions de dollars sur USDe
· Manipulation du prix : USDe chute de 1,00 $ à 0,65 $ sur une seule plateforme
· Défaillance de l’oracle : le système de marge utilise un flux de prix interne corrompu
· Déclenchement en chaîne : le collatéral est sous-évalué, liquidation forcée
· Amplification : 19,3 milliards de dollars de liquidations (amplification x322)
L’attaque a exploité le fait que Binance utilise le prix spot pour les collatéraux synthétiques emballés. Lorsqu’un attaquant a vendu 60 millions de dollars d’USDe sur un carnet d’ordres peu liquide, le prix spot est tombé de 1,00 $ à 0,65 $. Le système de marge, configuré pour marquer les collatéraux USDe au prix spot, a dévalué toutes les positions collatéralisées en USDe de 35 %. Cela a déclenché des appels de marge et des liquidations forcées sur des milliers de comptes.
Ces liquidations ont forcé davantage de ventes sur le même marché illiquide, faisant encore baisser le prix. Le système de marge a observé ces prix plus bas et a marqué la valeur de plus de positions, créant une boucle de rétroaction qui a amplifié la pression de vente de 60 millions de dollars en 19,3 milliards de dollars de liquidations forcées.

Figure 4 : Boucle de rétroaction de liquidation en chaîne
Ce diagramme de boucle illustre la nature auto-renforçante de la chaîne :
Baisse du prix → déclenchement de liquidation → ventes forcées → nouvelle baisse du prix → [boucle répétée]
Un système d’oracle bien conçu aurait empêché ce mécanisme. Si Binance avait utilisé un prix moyen pondéré dans le temps (TWAP) sur plusieurs plateformes, une manipulation de prix instantanée n’aurait pas affecté la valorisation des collatéraux. S’ils avaient utilisé des flux de prix agrégés de Chainlink ou d’autres oracles multi-sources, l’attaque aurait échoué.
L’incident wBETH survenu quatre jours plus tôt a révélé une faille similaire. wBETH doit maintenir un taux d’échange 1:1 avec ETH. Lors de l’événement en chaîne, la liquidité s’est tarie et le marché spot wBETH/ETH affichait une décote de 20 %. Le système de marge a alors dévalué les collatéraux wBETH, déclenchant la liquidation de positions pourtant entièrement collatéralisées par de l’ETH sous-jacent.
Mécanisme d’Auto-Deleveraging (ADL)
Lorsque les liquidations ne peuvent pas être exécutées au prix du marché, les plateformes appliquent l’auto-deleveraging (ADL), répartissant les pertes sur les traders gagnants. L’ADL force la clôture des positions gagnantes au prix courant pour combler le déficit des positions liquidées.
Lors de l’événement en chaîne d’octobre, Binance a exécuté l’ADL sur plusieurs paires. Les traders détenant des positions longues gagnantes ont vu leurs trades clôturés de force, non pas à cause d’une mauvaise gestion du risque de leur part, mais parce que d’autres positions étaient devenues insolvables.
L’ADL reflète un choix d’architecture fondamental dans le trading de produits dérivés centralisés. Les plateformes garantissent de ne pas perdre d’argent elles-mêmes. Cela signifie que les pertes doivent être supportées par :
· Le fonds d’assurance (fonds réservé par la plateforme pour combler les déficits de liquidation)
· L’ADL (clôture forcée des positions gagnantes)
· La socialisation des pertes (répartition des pertes sur tous les utilisateurs)
La taille du fonds d’assurance par rapport à l’encours des contrats détermine la fréquence de l’ADL. Le fonds d’assurance de Binance totalisait environ 2 milliards de dollars en octobre 2025. Par rapport à 4 milliards de dollars d’encours sur les contrats perpétuels BTC, ETH et BNB, cela offrait une couverture de 50 %. Mais lors de l’événement en chaîne d’octobre, l’encours total sur toutes les paires dépassait 20 milliards de dollars. Le fonds d’assurance ne pouvait pas couvrir le déficit.
Après l’événement d’octobre, Binance a annoncé qu’ils garantissaient l’absence d’ADL sur les contrats BTC, ETH et BNB USDⓈ-M tant que l’encours total restait sous 4 milliards de dollars. Cela crée une structure d’incitation : la plateforme peut maintenir un fonds d’assurance plus important pour éviter l’ADL, mais cela immobilise des fonds qui pourraient être déployés de manière plus rentable.
Pannes sur chaîne : limites des protocoles blockchain
Le graphique en barres compare la durée des pannes lors de différents événements :
· Solana (février 2024) : 5 heures – goulot d’étranglement du débit de vote
· Polygon (mars 2024) : 11 heures – incompatibilité de version des validateurs
· Optimism (juin 2024) : 2,5 heures – surcharge du séquenceur (airdrop)
· Solana (septembre 2024) : 4,5 heures – attaque par spam de transactions
· Arbitrum (décembre 2024) : 1,5 heure – panne du fournisseur RPC
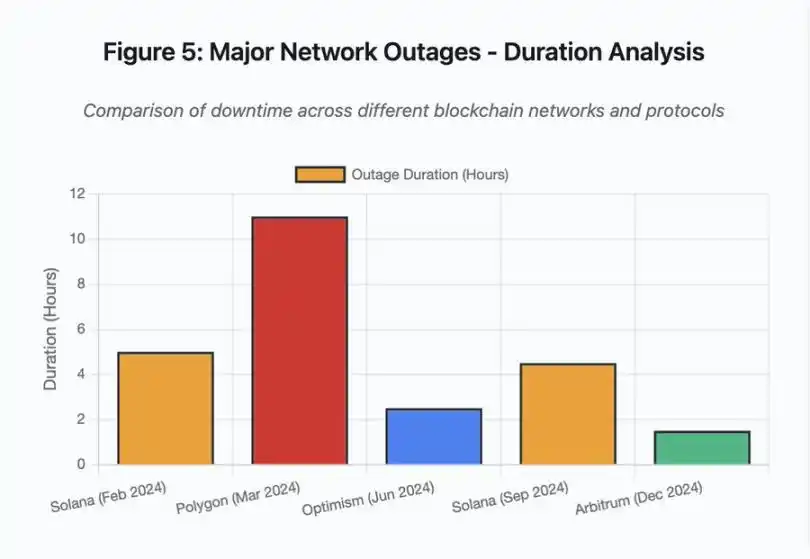
Figure 5 : Principales pannes réseau – analyse de la durée
Solana : goulot d’étranglement du consensus
Solana a connu plusieurs pannes entre 2024 et 2025. Celle de février 2024 a duré environ 5 heures, celle de septembre 2024, 4 à 5 heures. Ces interruptions proviennent de causes fondamentales similaires : le réseau ne peut pas traiter le volume de transactions lors d’attaques par spam ou d’activité extrême.
Détail figure 5 : les pannes de Solana (5 heures en février, 4,5 heures en septembre) soulignent la récurrence des problèmes de résilience du réseau sous pression.
L’architecture de Solana est optimisée pour le débit. Dans des conditions idéales, le réseau traite 3 000 à 5 000 transactions par seconde avec une finalité inférieure à la seconde. Cette performance surpasse Ethereum de plusieurs ordres de grandeur. Mais lors d’événements de stress, cette optimisation crée des vulnérabilités.
La panne de septembre 2024 a été causée par un afflux massif de transactions spam qui a submergé le mécanisme de vote des validateurs. Les validateurs Solana doivent voter sur les blocs pour parvenir au consensus. En fonctionnement normal, ils priorisent les transactions de vote pour assurer la progression du consensus. Mais le protocole traitait auparavant les transactions de vote comme des transactions ordinaires sur le marché des frais.
Lorsque le mempool est saturé de millions de transactions spam, les validateurs ont du mal à propager les votes. Sans suffisamment de votes, les blocs ne peuvent pas être finalisés. Sans finalisation, la chaîne s’arrête. Les utilisateurs voient leurs transactions bloquées dans le mempool. Les nouvelles transactions ne peuvent pas être soumises.
StatusGator a enregistré plusieurs pannes de service Solana en 2024-2025, alors que Solana ne les a jamais officiellement reconnues. Cela crée une asymétrie d’information. Les utilisateurs ne peuvent pas distinguer un problème de connexion local d’un problème à l’échelle du réseau. Les services de surveillance tiers apportent de la transparence, mais les plateformes devraient maintenir une page d’état complète.
Ethereum : explosion des frais de gas
Ethereum a connu une flambée extrême des frais de gas lors du boom DeFi de 2021, les frais de transaction pour un simple transfert dépassant 100 dollars. Les interactions complexes avec des smart contracts coûtaient 500 à 1 000 dollars. Ces frais rendaient le réseau inutilisable pour les petits montants, tout en ouvrant une nouvelle surface d’attaque : l’extraction de MEV.
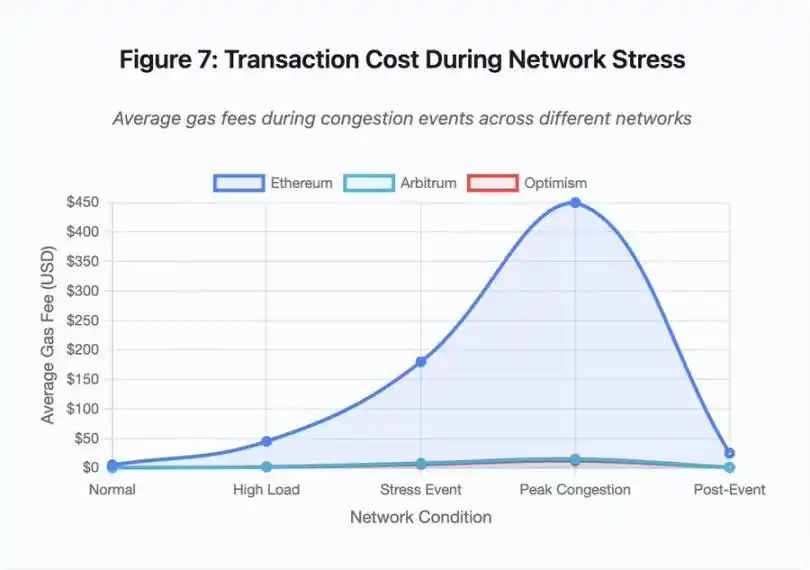
Figure 7 : Coût des transactions lors de périodes de stress réseau
Ce graphique linéaire montre de façon spectaculaire l’explosion des frais de gas sur différents réseaux lors d’événements de stress :
· Ethereum : 5 $ (normal) → 450 $ (pic de congestion) – x90
· Arbitrum : 0,50 $ → 15 $ – x30
· Optimism : 0,30 $ → 12 $ – x40
La visualisation montre que même les solutions Layer 2 subissent une hausse significative des frais de gas, bien que le point de départ soit beaucoup plus bas.
La valeur maximale extractible (MEV) décrit le profit que les validateurs peuvent tirer en réordonnant, incluant ou excluant des transactions. En environnement de frais élevés, le MEV devient particulièrement lucratif. Les arbitragistes se disputent la priorité sur les grosses transactions DEX, les bots de liquidation rivalisent pour liquider en premier les positions sous-collatéralisées. Cette compétition se traduit par une guerre d’enchères sur les frais de gas.
Les utilisateurs souhaitant garantir l’inclusion de leur transaction lors de la congestion doivent surenchérir sur les bots MEV. Cela crée des situations où les frais dépassent la valeur de la transaction. Vous voulez réclamer votre airdrop de 100 $ ? Payez 150 $ de frais de gas. Besoin d’ajouter du collatéral pour éviter la liquidation ? Faites face à des bots payant 500 $ de frais prioritaires.
La limite de gas d’Ethereum restreint la quantité totale de calcul par bloc. En période de congestion, les utilisateurs enchérissent pour l’espace limité des blocs. Le marché des frais fonctionne comme prévu : le plus offrant a la priorité. Mais cette conception rend le réseau de plus en plus cher lors des pics d’utilisation, précisément quand les utilisateurs ont le plus besoin d’y accéder.
Les solutions Layer 2 tentent de résoudre ce problème en déplaçant le calcul hors chaîne, tout en héritant de la sécurité d’Ethereum via des règlements périodiques. Optimism, Arbitrum et d’autres rollups traitent des milliers de transactions hors chaîne, puis soumettent des preuves compressées à Ethereum. Cette architecture réduit le coût par transaction en fonctionnement normal.
Layer 2 : goulot d’étranglement du séquenceur
Mais les solutions Layer 2 introduisent de nouveaux goulets d’étranglement. Optimism a connu une panne en juin 2024 lorsque 250 000 adresses ont réclamé un airdrop simultanément. Le séquenceur, composant qui trie les transactions avant de les soumettre à Ethereum, a été submergé, empêchant les utilisateurs de soumettre des transactions pendant plusieurs heures.
Cette panne montre que déplacer le calcul hors chaîne n’élimine pas les besoins d’infrastructure. Le séquenceur doit traiter les transactions entrantes, les trier, les exécuter et générer des preuves de fraude ou des preuves ZK pour le règlement sur Ethereum. Sous trafic extrême, le séquenceur fait face aux mêmes défis de scalabilité qu’une blockchain indépendante.
Il est essentiel de maintenir plusieurs fournisseurs RPC disponibles. Si le principal échoue, les utilisateurs doivent pouvoir basculer sans interruption. Lors de la panne d’Optimism, certains fournisseurs RPC sont restés fonctionnels, d’autres non. Les utilisateurs dont le portefeuille était connecté par défaut à un fournisseur défaillant ne pouvaient pas interagir avec la chaîne, même si celle-ci restait en ligne.
Les pannes AWS ont démontré à plusieurs reprises le risque d’infrastructure centralisée dans l’écosystème crypto :
· 20 octobre 2025 (aujourd’hui) : panne de la région Est des États-Unis affectant Coinbase, ainsi que Venmo, Robinhood et Chime. AWS reconnaît une augmentation du taux d’erreur sur DynamoDB et EC2.
· Avril 2025 : panne régionale affectant simultanément Binance, KuCoin et MEXC. Plusieurs grandes plateformes deviennent indisponibles lorsque leurs composants hébergés sur AWS tombent en panne.
· Décembre 2021 : panne de la région Est des États-Unis provoquant la paralysie de Coinbase, Binance.US et de la plateforme « décentralisée » dYdX pendant 8 à 9 heures, affectant aussi les entrepôts d’Amazon et les principaux services de streaming.
· Mars 2017 : panne S3 empêchant les utilisateurs de se connecter à Coinbase et GDAX pendant cinq heures, accompagnée d’une panne Internet généralisée.
Le schéma est clair : ces plateformes hébergent des composants critiques sur l’infrastructure AWS. Lorsqu’AWS subit une panne régionale, plusieurs grandes plateformes et services deviennent simultanément indisponibles. Les utilisateurs ne peuvent pas accéder à leurs fonds, exécuter des transactions ou modifier leurs positions, précisément lorsque la volatilité du marché exige une action immédiate.
Polygon : incompatibilité de version du consensus
Polygon (anciennement Matic) a connu une panne de 11 heures en mars 2024. La cause fondamentale était une incompatibilité de version des validateurs : certains exécutaient une version logicielle obsolète, d’autres une version mise à jour. Ces versions calculaient différemment les transitions d’état.
Détail figure 5 : la panne de Polygon (11 heures) est la plus longue des événements analysés, soulignant la gravité des défaillances de consensus.
Lorsque les validateurs tirent des conclusions différentes sur l’état correct, le consensus échoue et la chaîne ne peut plus produire de nouveaux blocs, car les validateurs ne s’accordent pas sur la validité des blocs. Cela crée une impasse : les validateurs sur l’ancienne version refusent les blocs produits par la nouvelle, et vice versa.
La résolution nécessite une coordination pour mettre à jour les validateurs, ce qui prend du temps pendant une panne. Chaque opérateur doit être contacté, la bonne version déployée, puis le validateur redémarré. Dans un réseau décentralisé avec des centaines de validateurs indépendants, cette coordination prend des heures, voire des jours.
Les hard forks utilisent généralement un déclencheur basé sur la hauteur de bloc. Tous les validateurs mettent à jour avant une hauteur spécifique, assurant une activation simultanée, mais cela exige une coordination préalable. Les mises à jour progressives, où les validateurs adoptent la nouvelle version progressivement, risquent de provoquer exactement l’incompatibilité ayant causé la panne de Polygon.
Arbitrages architecturaux
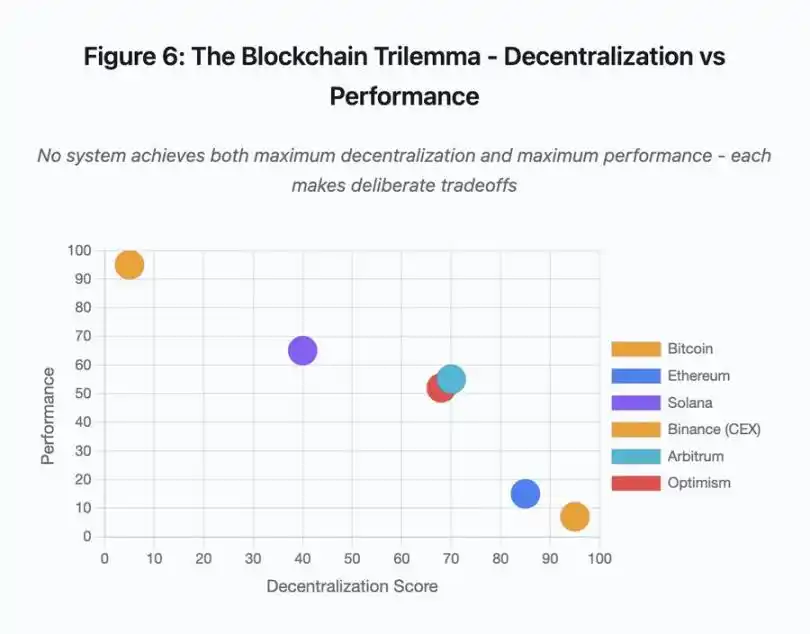
Figure 6 : Trilemme de la blockchain – décentralisation vs performance
Ce nuage de points visualise le positionnement des différents systèmes selon deux axes clés :
· Bitcoin : forte décentralisation, faible performance
· Ethereum : forte décentralisation, performance moyenne
· Solana : décentralisation moyenne, haute performance
· Binance (CEX) : décentralisation minimale, performance maximale
· Arbitrum/Optimism : décentralisation moyenne à élevée, performance moyenne
Point clé : aucun système ne réalise à la fois la décentralisation et la performance maximales, chaque conception fait des compromis réfléchis selon les cas d’usage.
Les plateformes centralisées atteignent une faible latence grâce à la simplicité architecturale : le moteur de matching traite les ordres en microsecondes, l’état réside dans une base de données centralisée. Aucun protocole de consensus n’ajoute de surcharge, mais cette simplicité crée un point de défaillance unique, et les pannes se propagent dans les systèmes étroitement couplés sous pression.
Les protocoles décentralisés distribuent l’état entre validateurs, éliminant le point de défaillance unique. Les chaînes à haut débit conservent cette propriété lors des pannes (les fonds ne sont pas perdus, seule la disponibilité est temporairement affectée). Mais parvenir au consensus entre validateurs introduit une surcharge computationnelle, car ils doivent s’accorder sur les transitions d’état avant la finalité. Si les validateurs exécutent des versions incompatibles ou font face à un trafic écrasant, le consensus peut s’arrêter temporairement.
Ajouter des réplicas accroît la tolérance aux pannes, mais augmente le coût de coordination. Dans les systèmes tolérants aux fautes byzantines, chaque validateur supplémentaire accroît la charge de communication. Les architectures à haut débit minimisent cette charge via une communication optimisée entre validateurs, atteignant des performances supérieures, mais restant vulnérables à certains types d’attaques. Les architectures axées sur la sécurité privilégient la diversité des validateurs et la robustesse du consensus, limitant le débit de la couche de base tout en maximisant la résilience.
Les solutions Layer 2 tentent d’offrir les deux propriétés via une conception en couches. Elles héritent de la sécurité d’Ethereum via le règlement L1, tout en offrant un haut débit via le calcul hors chaîne. Mais elles introduisent de nouveaux goulets d’étranglement au niveau du séquenceur et du RPC, montrant que la complexité architecturale résout certains problèmes tout en créant de nouveaux modes de panne.
La scalabilité reste le problème fondamental
Ces événements révèlent un schéma constant : les systèmes sont dimensionnés pour la charge normale, puis échouent de façon catastrophique sous pression. Solana gère efficacement le trafic ordinaire, mais s’effondre lorsque le volume de transactions augmente de 10 000 %. Les frais d’Ethereum restent raisonnables jusqu’à ce que l’adoption DeFi provoque la congestion. L’infrastructure d’Optimism fonctionne bien jusqu’à ce que 250 000 adresses réclament un airdrop simultanément. L’API de Binance fonctionne normalement, mais devient un goulot d’étranglement lors d’une liquidation en chaîne.
L’événement d’octobre 2025 illustre cette dynamique au niveau des exchanges. En fonctionnement normal, les limitations de débit API et les connexions aux bases de données de Binance suffisent, mais lors d’une liquidation en chaîne, lorsque chaque trader tente simultanément d’ajuster sa position, ces limites deviennent des goulets d’étranglement. Les systèmes de marge, conçus pour protéger la plateforme via des liquidations forcées, amplifient la crise en créant des vendeurs forcés au pire moment.
La mise à l’échelle automatique protège insuffisamment contre les augmentations de charge en escalier. Lancer des serveurs supplémentaires prend plusieurs minutes ; pendant ce temps, les systèmes de marge marquent la valeur des positions sur la base de prix corrompus issus de carnets d’ordres peu liquides. Quand la nouvelle capacité est en ligne, la réaction en chaîne s’est déjà propagée.
Surdimensionner l’infrastructure pour des événements rares coûte cher en fonctionnement normal. Les opérateurs optimisent pour la charge typique, acceptant des pannes occasionnelles comme un compromis économique raisonnable. Le coût des interruptions est externalisé sur les utilisateurs, qui subissent liquidations, blocages de transactions ou inaccessibilité des fonds lors de mouvements de marché critiques.
Améliorations de l’infrastructure
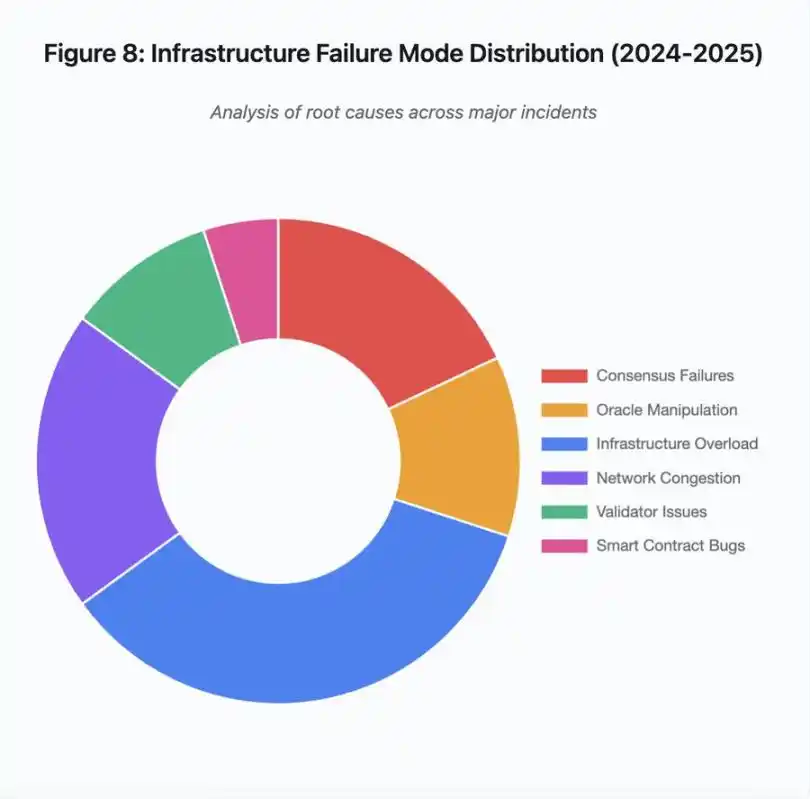
Figure 8 : Répartition des modes de défaillance d’infrastructure (2024-2025)
Le diagramme circulaire des causes fondamentales montre :
· Surcharge d’infrastructure : 35 % (le plus fréquent)
· Congestion réseau : 20 %
· Échec du consensus : 18 %
· Manipulation d’oracle : 12 %
· Problèmes de validateurs : 10 %
· Failles de smart contract : 5 %
Plusieurs changements architecturaux peuvent réduire la fréquence et la gravité des pannes, bien que chacun implique des compromis :
Séparation des systèmes de tarification et de liquidation
Le problème d’octobre provient en partie du couplage du calcul de la marge avec le prix spot. Utiliser le taux d’échange pour les actifs emballés, plutôt que le prix spot, aurait évité la mauvaise valorisation de wBETH. Plus généralement, les systèmes de gestion des risques critiques ne devraient pas dépendre de données de marché manipulables. Des oracles indépendants, multi-sources et avec calcul TWAP, fournissent des flux de prix plus robustes.
Surdimensionnement et redondance de l’infrastructure
La panne AWS d’avril 2025 affectant Binance, KuCoin et MEXC démontre le risque de dépendance à une infrastructure centralisée. Exécuter des composants critiques sur plusieurs clouds accroît la complexité et le coût, mais élimine les pannes corrélées. Les réseaux Layer 2 peuvent maintenir plusieurs fournisseurs RPC avec basculement automatique. Le coût supplémentaire semble du gaspillage en fonctionnement normal, mais évite des heures d’interruption lors des pics de demande.
Tests de charge renforcés et planification de capacité
Le schéma où les systèmes fonctionnent bien jusqu’à l’échec montre un manque de tests sous pression. Simuler une charge 100 fois supérieure à la normale devrait être une pratique standard ; identifier les goulets d’étranglement en développement coûte moins cher que de les découvrir lors d’une panne réelle. Mais les tests réalistes restent difficiles : le trafic en production présente des schémas que les tests synthétiques ne capturent pas, et le comportement des utilisateurs diffère lors d’un crash réel.
La voie à suivre
Le surdimensionnement offre la solution la plus fiable, mais entre en conflit avec les incitations économiques. Maintenir une capacité excédentaire x10 pour des événements rares coûte chaque jour, pour éviter un problème qui ne survient qu’une fois par an. Tant que les pannes catastrophiques n’imposent pas un coût suffisant pour justifier le surdimensionnement, les systèmes continueront d’échouer sous pression.
La pression réglementaire pourrait forcer le changement. Si la réglementation impose 99,9 % de disponibilité ou limite le temps d’arrêt acceptable, les plateformes devront surdimensionner. Mais la réglementation suit généralement les catastrophes, pas la prévention. L’effondrement de Mt. Gox en 2014 a conduit le Japon à réglementer formellement les plateformes crypto. L’événement en chaîne d’octobre 2025 pourrait entraîner une réponse réglementaire similaire. Reste à savoir si ces réponses fixeront des résultats (temps d’arrêt maximal, slippage maximal lors des liquidations) ou imposeront des moyens (oracles spécifiques, seuils de coupe-circuit).
Le défi fondamental est que ces systèmes fonctionnent en continu sur des marchés mondiaux, mais s’appuient sur une infrastructure conçue pour des horaires commerciaux traditionnels. Lorsque la pression survient à 2h du matin, les équipes s’empressent de déployer des correctifs, tandis que les utilisateurs subissent des pertes croissantes. Les marchés traditionnels suspendent les échanges lors des crises ; les marchés crypto s’effondrent simplement. Selon le point de vue, c’est une fonctionnalité ou un défaut.
Les systèmes blockchain ont atteint une complexité technique remarquable en peu de temps. Maintenir un consensus distribué entre des milliers de nœuds est un véritable exploit d’ingénierie. Mais assurer la fiabilité sous pression exige de dépasser l’architecture de prototype pour atteindre une infrastructure de niveau production. Cette transition nécessite des fonds et de privilégier la robustesse sur la rapidité de développement fonctionnel.
Le défi est de placer la robustesse avant la croissance en période de marché haussier, quand tout le monde gagne de l’argent et que les pannes semblent être le problème des autres. Attendre le prochain cycle pour tester le système sous pression révélera de nouvelles faiblesses. L’industrie tirera-t-elle les leçons d’octobre 2025 ou répétera-t-elle le même schéma ? L’histoire suggère que nous découvrirons la prochaine faille critique à travers un nouvel échec de plusieurs milliards sous pression.
Avertissement : le contenu de cet article reflète uniquement le point de vue de l'auteur et ne représente en aucun cas la plateforme. Cet article n'est pas destiné à servir de référence pour prendre des décisions d'investissement.
Vous pourriez également aimer
【Long tweet en anglais】USDe est-il vraiment assez sûr ?
BlackRock acquiert pour 211 millions de dollars de Bitcoin

Le token ZKC bondit de 63 % : s'agit-il du début d'un rallye plus important ?
L'indice de volatilité du Bitcoin dépasse à nouveau 95%
L'indice de volatilité du Bitcoin dépasse 95 % pour la troisième fois en un mois, signalant de potentielles fluctuations importantes des prix. Qu'est-ce qui motive cette forte volatilité ? Comment les traders peuvent-ils naviguer dans cette zone de volatilité ?
