
Trending! Meituan's large model becomes popular thanks to its "speed"

Domestic and international developers: Tested, Meituan’s newly open-sourced model is super fast!
As AI truly becomes as ubiquitous as water and electricity, the strength of a model is no longer the only thing people care about.
From Claude 3.7 Sonnet and Gemini 2.5 Flash at the beginning of the year to the recent GPT-5 and DeepSeek V3.1, all leading model providers are thinking: under the premise of ensuring accuracy, how can AI solve each problem with the least amount of computing power and respond in the shortest possible time? In other words, how can we avoid wasting both tokens and time?
For enterprises and developers building applications on top of models, this shift from “simply building the strongest model to building more practical and faster models” is good news. Even more gratifying is that related open-source models are gradually increasing.
A few days ago, we discovered a new model on HuggingFace—LongCat-Flash-Chat.

This model comes from Meituan’s LongCat-Flash series, and can be used directly on the official website.
It inherently understands that “not all tokens are equal,” and therefore dynamically allocates computational budgets to important tokens based on their significance. This allows it to match the performance of today’s leading open-source models while activating only a small number of parameters.

LongCat-Flash went viral after being open-sourced.
At the same time, the speed of this model has also left a deep impression—on H800 GPUs, inference speed exceeds 100 tokens per second. Both domestic and international developers have confirmed this through real-world testing—some achieved 95 tokens/s, and some received answers comparable to Claude in the shortest time.
Image source: Zhihu user @小小将.
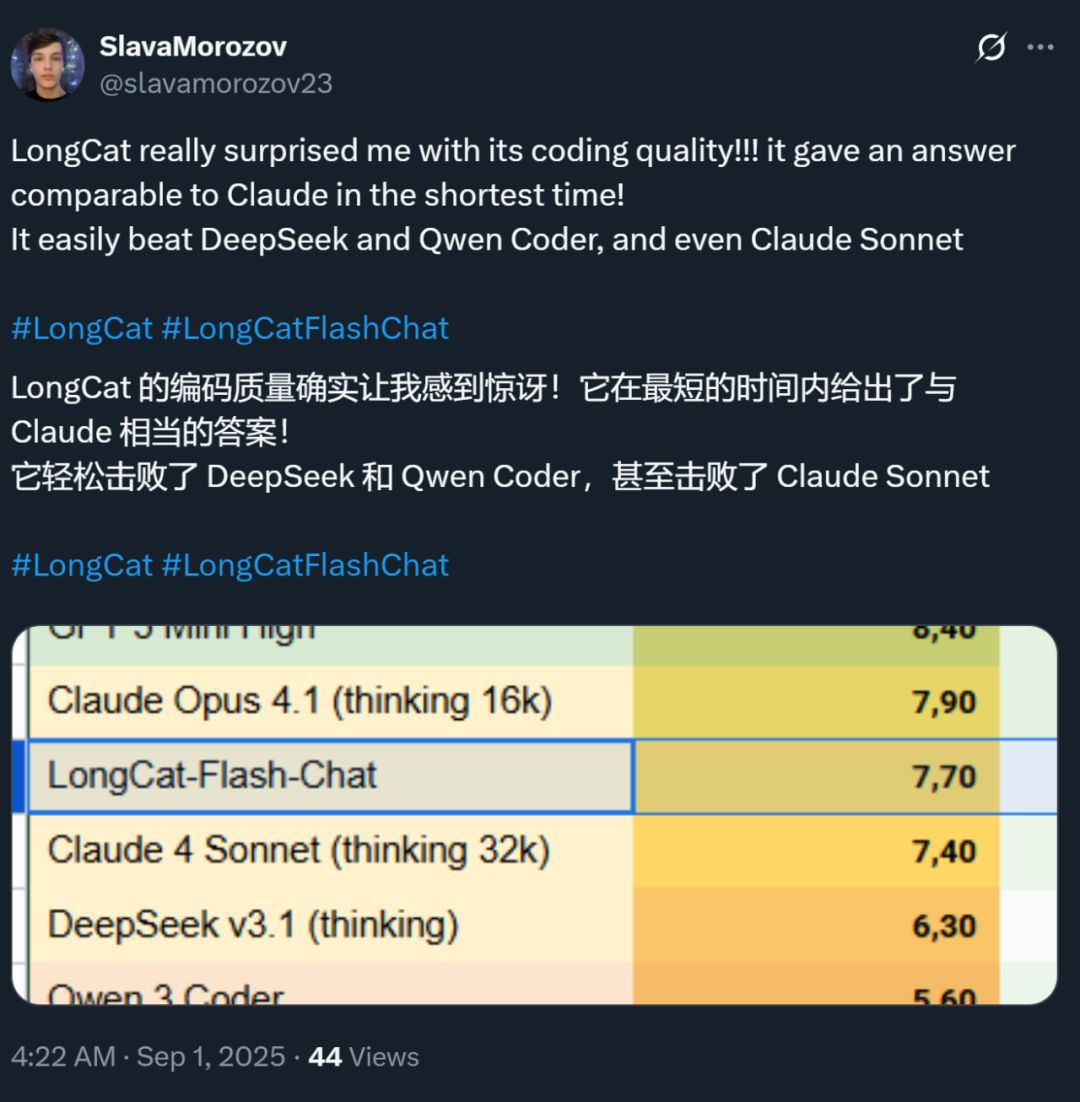
Image source: X user @SlavaMorozov.
Alongside open-sourcing the model, Meituan also released the LongCat-Flash technical report, where we can see many technical details.

Technical Report: LongCat-Flash Technical Report
In this article, we will introduce it in detail.
How do large models save computing power?
Let’s look at LongCat-Flash’s architectural innovations and training methods
LongCat-Flash is a Mixture of Experts (MoE) model with a total parameter count of 560 billions, and can activate between 18.6 billions and 31.3 billions (average 27 billions) parameters depending on contextual needs.
The amount of data used to train this model exceeds 20 trillion tokens, but the training time was less than 30 days. Moreover, during this period, the system achieved a 98.48% uptime, with almost no need for manual intervention to handle failures—meaning the entire training process was basically “unattended” and completed automatically.
Even more impressive is that the model trained in this way also performs excellently in actual deployment.
As shown below, as a non-thinking model, LongCat-Flash achieves performance comparable to SOTA non-thinking models, including DeepSeek-V3.1 and Kimi-K2, while using fewer parameters and offering faster inference speed. This makes it highly competitive and practical in areas such as general tasks, programming, and agent tool usage.
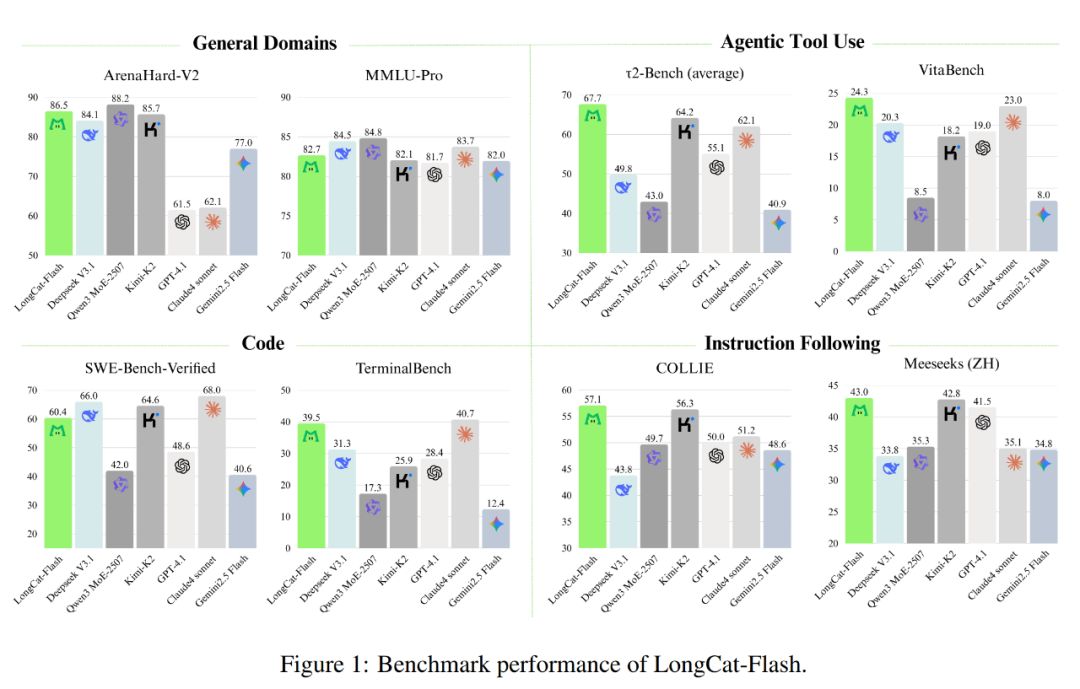
In addition, its cost is also impressive, at only $0.7 per million output tokens. Compared to models of similar scale on the market, this price is very cost-effective.
Technically, LongCat-Flash mainly targets two goals of language models: computational efficiency and agent capability, and integrates architectural innovation with multi-stage training methods to achieve a scalable and intelligent model system.
In terms of model architecture, LongCat-Flash adopts a novel MoE architecture (Figure 2), with two main highlights:
Zero-computation Experts;
Shortcut-connected MoE (ScMoE).
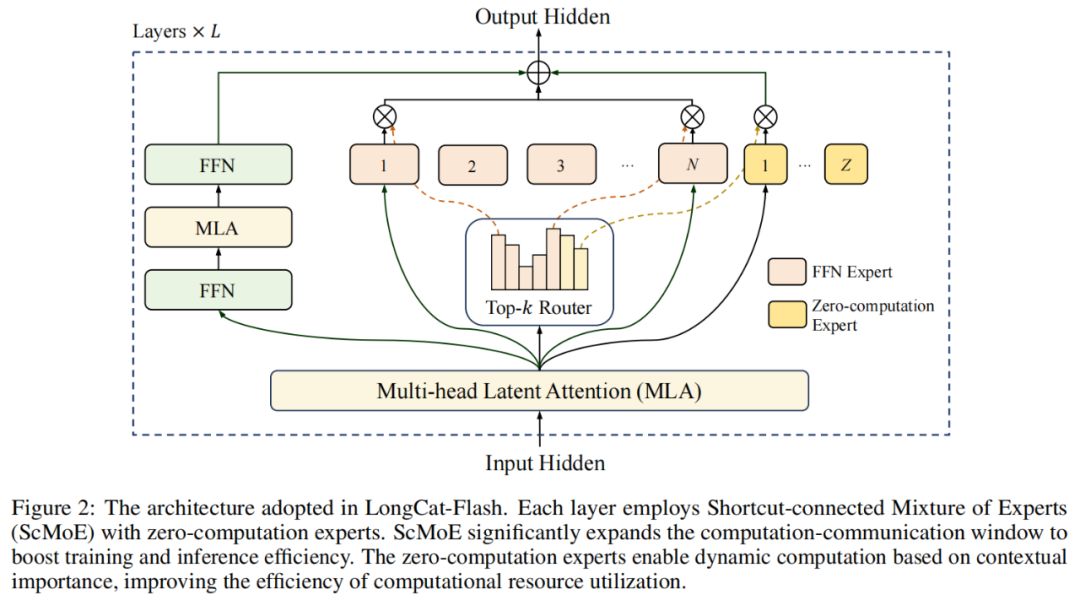
Zero-computation Experts
The core idea of zero-computation experts is that not all tokens are “equal.”
We can understand it this way: in a sentence, some words are very easy to predict, such as “的” or “是” (Chinese function words), which require almost no computation, while others, such as “person names,” require a lot of computation to predict accurately.
In previous research, the common approach was: regardless of whether the token is simple or complex, it would activate a fixed number (K) of experts, resulting in huge computational waste. For simple tokens, it’s unnecessary to call so many experts, while for complex tokens, there may not be enough computational allocation.
Inspired by this, LongCat-Flash proposes a dynamic computational resource allocation mechanism: through zero-computation experts, it dynamically activates different numbers of FFN (Feed-Forward Network) experts for each token, thereby allocating computational resources more reasonably based on contextual importance.
Specifically, in its expert pool, LongCat-Flash extends the original N standard FFN experts with Z zero-computation experts. Zero-computation experts simply return the input as output, thus introducing no additional computational overhead.
The MoE module in LongCat-Flash can be formalized as:
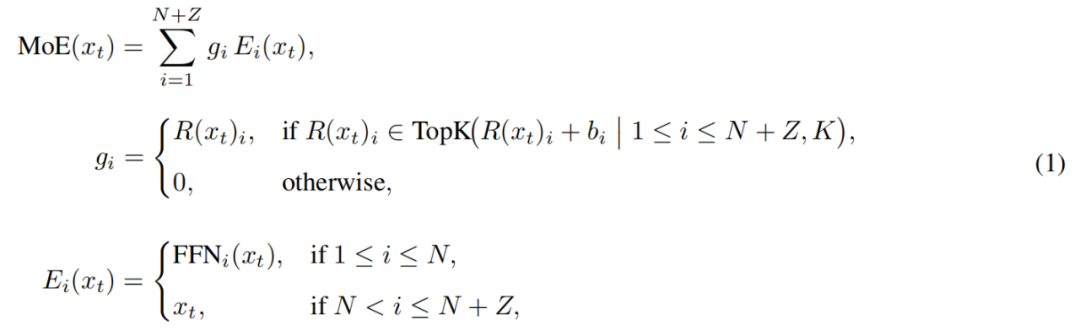
Here, x_t is the t-th token in the input sequence, R denotes the softmax router, b_i is the bias term for the i-th expert, and K is the number of experts selected for each token. The router assigns each token to K experts, with the number of activated FFN experts varying according to the contextual importance of the token. Through this adaptive allocation mechanism, the model can learn to dynamically allocate more computational resources to tokens that are more important in context, thereby achieving better performance under the same computational budget, as shown in Figure 3a.
Additionally, when processing input, the model needs to learn to decide whether to spend more computational resources based on the importance of different tokens. If the frequency of zero-computation experts being selected is not controlled, the model may tend to choose computational experts and ignore the role of zero-computation experts, resulting in inefficient use of computational resources.
To solve this problem, Meituan improved the expert bias mechanism in the aux-loss-free strategy: introducing expert-specific bias terms that can dynamically adjust routing scores based on recent expert usage, while remaining decoupled from the language model’s training objective.
The update rule uses a PID controller from control theory to fine-tune expert biases in real time. Thanks to this, when processing each token, the model only needs to activate between 18.6 billions and 31.3 billions (with the average stable at about 27 billions) parameters, thus achieving optimized resource allocation.
Shortcut-connected MoE
Another highlight of LongCat-Flash is the shortcut-connected MoE mechanism.
Generally, the efficiency of large-scale MoE models is largely limited by communication overhead. In traditional execution paradigms, expert parallelism introduces a sequential workflow: a global communication operation must first route tokens to their designated experts before computation can begin.
This sequence of communication followed by computation introduces additional waiting time, especially in large-scale distributed training, where communication latency significantly increases and becomes a performance bottleneck.
Previously, some researchers adopted shared expert architectures, attempting to alleviate the problem by overlapping communication with the computation of a single expert, but their efficiency is limited by the small computation window of a single expert.
Meituan overcomes this limitation by introducing the ScMoE architecture, which adds a cross-layer shortcut connection between layers. This key innovation allows the computation of the previous dense FFN to be executed in parallel with the dispatch/aggregation communication operations of the current MoE layer, forming a larger communication-computation overlap window compared to shared expert architectures.
This architectural design has been validated in multiple experiments.
First, the ScMoE design does not reduce model quality. As shown in Figure 4, the training loss curves of the ScMoE architecture and the baseline without ScMoE are almost identical, proving that this reordered execution method does not harm model performance. This conclusion has been consistently validated under various configurations.
More importantly, these results show that the stability and performance advantages of ScMoE are orthogonal to the specific choice of attention mechanism (i.e., stable and beneficial regardless of which attention mechanism is used).
Second, the ScMoE architecture provides significant system-level efficiency improvements for both training and inference. Specifically:
In large-scale training: the expanded overlap window allows the computation of preceding blocks to be fully parallelized with the dispatch and aggregation communication stages in the MoE layer, achieved by splitting operations into fine-grained blocks along the token dimension.
In efficient inference: ScMoE supports single-batch overlapping pipeline, reducing the theoretical tokens-per-output-time (TPOT) by nearly 50% compared to leading models such as DeepSeek-V3. More importantly, it allows concurrent execution of different communication modes: intra-node tensor parallel communication on dense FFN (via NVLink) can be fully overlapped with inter-node expert parallel communication (via RDMA), maximizing overall network utilization.
In short, ScMoE provides significant performance improvements without sacrificing model quality.
Model scaling strategy and multi-stage training
Meituan has also proposed a set of efficient model scaling strategies that can significantly improve model performance as scale increases.
First is hyperparameter transfer. When training ultra-large-scale models, directly trying various hyperparameter configurations is very expensive and unstable. Therefore, Meituan first experiments on smaller models to find the best hyperparameter combination, then transfers these parameters to the large model. This saves costs and ensures effectiveness. The transfer rules are shown in Table 1:
Second is model growth initialization. Meituan starts with a half-scale model pre-trained on tens of billions of tokens, saves the checkpoint after training, then expands the model to full scale and continues training.
With this approach, the model exhibits a typical loss curve: a brief increase in loss followed by rapid convergence, and ultimately significantly outperforms the randomly initialized baseline. Figure 5b shows a representative result from the 6B activated parameter experiment, demonstrating the advantage of model growth initialization.
The third point is a multi-level stability suite. Meituan enhances LongCat-Flash’s training stability from three aspects: router stability, activation stability, and optimizer stability.
The fourth point is deterministic computation, which ensures complete reproducibility of experimental results and enables detection of Silent Data Corruption (SDC) during training.
With these measures, LongCat-Flash’s training process remains highly stable, with no unrecoverable loss spikes.
On the basis of stable training, Meituan also carefully designed a training pipeline to endow LongCat-Flash with advanced agent behaviors. This process covers large-scale pre-training, mid-stage training for reasoning and coding capabilities, and post-training focused on dialogue and tool usage.
In the initial stage, a base model more suitable for agent post-training is built. For this, Meituan designed a two-stage pre-training data fusion strategy to focus on data from reasoning-intensive domains.
In the mid-training stage, Meituan further enhances the model’s reasoning and coding abilities, and extends the context length to 128k to meet the needs of agent post-training.
Finally, Meituan conducted multi-stage post-training. Given the scarcity of high-quality, high-difficulty training data in the agent domain, Meituan designed a multi-agent synthesis framework: this framework defines task difficulty from three dimensions—information processing, toolset complexity, and user interaction—using specialized controllers to generate complex tasks requiring iterative reasoning and environmental interaction.
This design enables it to excel at executing complex tasks that require tool invocation and environmental interaction.
Fast and cheap to run
How does LongCat-Flash achieve this?
As mentioned earlier, LongCat-Flash can perform inference at over 100 tokens per second on H800 GPUs, with a cost of only $0.7 per million output tokens—truly fast and cheap.
How is this achieved? First, they have a parallel inference architecture co-designed with the model architecture; second, they have incorporated optimizations such as quantization and custom kernels.
Dedicated optimization: Letting the model “run smoothly on its own”
We know that to build an efficient inference system, two key problems must be solved: coordination of computation and communication, and the reading, writing, and storage of KV cache.
For the first challenge, existing methods typically exploit parallelism at three conventional granularities: operator-level overlap, expert-level overlap, and layer-level overlap. LongCat-Flash’s ScMoE architecture introduces a fourth dimension—module-level overlap. For this, the team designed the SBO (Single Batch Overlap) scheduling strategy to optimize latency and throughput.
SBO is a four-stage pipeline execution method that fully leverages LongCat-Flash’s potential through module-level overlap, as shown in Figure 9. The difference between SBO and TBO is that communication overhead is hidden within a single batch. In the first stage, MLA computation is performed to provide input for subsequent stages; the second stage overlaps Dense FFN and Attn 0 (QKV projection) with all-to-all dispatch communication; the third stage independently executes MoE GEMM, with latency benefiting from extensive EP deployment strategies; the fourth stage overlaps Attn 1 (core attention and output projection) and Dense FFN with all-to-all combine. This design effectively alleviates communication overhead and ensures efficient inference for LongCat-Flash.
For the second challenge—KV cache reading, writing, and storage—LongCat-Flash addresses these issues through architectural innovations in its attention mechanism and MTP structure to reduce effective I/O overhead.
First is speculative decoding acceleration. LongCat-Flash uses MTP as a draft model, optimizing three key factors through system analysis of the speculative decoding acceleration formula: expected acceptance length, cost ratio between draft and target models, and cost ratio between target verification and decoding. By integrating a single MTP head and introducing it in the later stage of pre-training, an acceptance rate of about 90% is achieved. To balance draft quality and speed, a lightweight MTP architecture is used to reduce parameters, and the C2T method is used to filter tokens unlikely to be accepted via a classification model.
Second is KV cache optimization, achieved through MLA’s 64-head attention mechanism. MLA significantly reduces computational load and achieves excellent KV cache compression while maintaining a balance between performance and efficiency, reducing storage and bandwidth pressure. This is crucial for coordinating LongCat-Flash’s pipeline, as the model always has attention computations that cannot be overlapped with communication.
System-level optimization: Letting hardware “collaborate as a team”
To minimize scheduling overhead, the LongCat-Flash research team addressed the launch-bound problem caused by kernel launch overhead in LLM inference systems. Especially after introducing speculative decoding, independent scheduling of verification kernels and draft forward passes incurs significant overhead. Through the TVD fusion strategy, they fused target forward, verification, and draft forward into a single CUDA graph. To further improve GPU utilization, they implemented an overlapping scheduler and introduced a multi-step overlapping scheduler to launch multiple forward step kernels in a single scheduling iteration, effectively hiding CPU scheduling and synchronization overhead.
Custom kernel optimization addresses the unique efficiency challenges brought by the autoregressive nature of LLM inference. The prefill stage is compute-intensive, while the decoding stage often has small and irregular batch sizes due to traffic patterns and is typically memory-bound. For MoE GEMM, they use the SwapAB technique to treat weights as the left matrix and activations as the right matrix, maximizing tensor core utilization with 8-element granularity along the n-dimension. Communication kernels use NVLink Sharp’s hardware-accelerated broadcast and in-switch reduction to minimize data movement and SM occupancy, consistently outperforming NCCL and MSCCL++ across message sizes from 4KB to 96MB with only 4 thread blocks.
In terms of quantization, LongCat-Flash adopts the same fine-grained block-level quantization scheme as DeepSeek-V3. To achieve the best performance-accuracy trade-off, it implements hierarchical mixed-precision quantization based on two schemes: the first identifies that input activations of certain linear layers (especially Downproj) have extreme magnitudes up to 10^6; the second computes block-level FP8 quantization errors layer by layer and finds significant quantization errors in specific expert layers. By taking the intersection of the two schemes, significant accuracy improvements are achieved.
Real-world data: How fast? How cheap?
Measured performance shows that LongCat-Flash performs excellently under different settings. Compared to DeepSeek-V3, LongCat-Flash achieves higher generation throughput and faster generation speed at similar context lengths.
In Agent applications, considering the differentiated needs between inference content (visible to users, requiring a match to human reading speed of about 20 tokens/s) and action commands (invisible to users but directly affecting tool invocation startup time, requiring maximum speed), LongCat-Flash’s nearly 100 tokens/s generation speed keeps single-round tool invocation latency within 1 second, significantly improving Agent application interactivity. Assuming an H800 GPU cost of $2 per hour, this means the price per million output tokens is $0.7.
Theoretical performance analysis shows that LongCat-Flash’s latency is mainly determined by three components: MLA, all-to-all dispatch/combine, and MoE. Under the assumptions of EP=128, batch per card=96, and MTP acceptance rate ≈80%, LongCat-Flash’s theoretical limit TPOT is 16ms, significantly better than DeepSeek-V3’s 30ms and Qwen3-235B-A22B’s 26.2ms. Assuming an H800 GPU cost of $2 per hour, LongCat-Flash’s output cost is $0.09 per million tokens, much lower than DeepSeek-V3’s $0.17. However, these values are only theoretical limits.
We also tested on LongCat-Flash’s free trial page.
First, we asked this large model to write an article about autumn, around 1,000 words.
As soon as we made the request and started recording, LongCat-Flash had already written the answer—the recording didn’t even have time to catch the very beginning.
Upon closer observation, you’ll notice that LongCat-Flash’s first token output speed is especially fast. With other dialogue models, you often encounter spinning circles and waiting, which really tests user patience—like when you’re anxious to check WeChat, but your phone shows “receiving.” LongCat-Flash changes this experience, making the first token delay almost unnoticeable.
The subsequent token generation speed is also very fast, far exceeding the speed of human reading.
Next, we turned on “web search” to see if LongCat-Flash is fast enough in this capability. We asked LongCat-Flash to recommend good restaurants near Wangjing.
The test clearly showed that LongCat-Flash doesn’t take a long time to “think” before responding, but instead gives an answer almost immediately. The web search also feels “fast.” Moreover, it can provide cited sources while outputting quickly, ensuring both credibility and traceability of information.
Readers who can download the model are encouraged to run it locally to see if LongCat-Flash’s speed is equally impressive.
When large models enter the era of practicality
In the past few years, whenever a new large model came out, everyone would care: What are its benchmark scores? How many leaderboards has it refreshed? Is it SOTA? Now, things have changed. When capabilities are similar, people care more about: Is your model expensive to use? How fast is it? This is especially true among enterprises and developers using open-source models. Many users choose open-source models precisely to reduce dependence on and costs of closed-source APIs, so they are more sensitive to computing power requirements, inference speed, and quantization/compression effects.
Meituan’s open-sourced LongCat-Flash is a representative work that fits this trend. They focus on making large models truly affordable and fast to run, which is key to technological popularization.
This practical approach is consistent with our long-standing impression of Meituan. In the past, most of their technical investments were used to solve real business pain points. For example, the EDPLVO that won ICRA’s Best Navigation Paper in 2022 was actually to solve various unexpected situations encountered by drones during delivery (such as signal loss due to dense buildings); the recently co-developed global drone obstacle avoidance ISO standard is a technical summary of cases like drones avoiding kite strings and window cleaning ropes during flight. The open-sourced LongCat-Flash this time is actually the model behind their AI programming tool “NoCode,” which serves both internal company needs and is open to the public for free, hoping everyone can use vibe coding to reduce costs and increase efficiency.
This shift from performance competition to practical orientation actually reflects the natural law of AI industry development. As model capabilities gradually converge, engineering efficiency and deployment costs become key differentiators. The open-sourcing of LongCat-Flash is just one example of this trend, but it does provide the community with a reference technical path: how to lower the usage threshold through architectural innovation and system optimization while maintaining model quality. For developers and enterprises with limited budgets but eager to leverage advanced AI capabilities, this is undoubtedly valuable.
Disclaimer: The content of this article solely reflects the author's opinion and does not represent the platform in any capacity. This article is not intended to serve as a reference for making investment decisions.
You may also like
El Salvador Divides $678M Bitcoin to Mitigate Quantum Risks
Fluid: The New Ruler of DeFi?
Will the overlooked DeFi strong contender Fluid be listed on major exchanges soon?

How to earn a five-figure passive income in Web3?
Only additional income can bring true freedom.

When faced with the contradiction between claims that Bitcoin will eventually reach 1 million and the reality of its continuously falling price, who should we trust?
People are speaking out not for self-custody or cypherpunk-style bitcoin discussions, but for political figures and financial engineering.
